



•
요약
◦
DBMS 와 기억장치의 관계
◦
옵티마이저(optimizer)
◦
메모리 작동 방식
◦
트레이드 오프
[1강] DBMS의 구성(개요)
쿼리 평가 엔진
•
SQL 구문분석
•
실행 계획
•
실행 계획 실행
•
접근 메서드(access method)로 데이터 접근
버퍼 매니저
•
캐시 메모리 관리
디스크 용량 매니저
•
영속성 저장 관련 관리
트랜젝션 매니저 & 락 매니저
•
트랜젝션 & 동시성 관리
리커버리 매니저
•
데이터 백업 & 복구
[2강] DBMS 와 버퍼
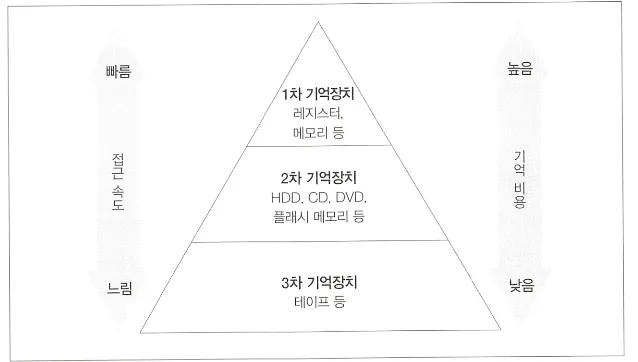
•
2차 기억장치 HDD 에 영속성 저장
•
1차 기억장치에 성능향상을 위한 캐시 메모리 사용
⇒ SQL 구문의 실행 시간 대부분은 I/O에 사용된다 따라서 자주사용하는 데이터는 1차 메모리에 올리고 사용한다
버퍼매니저가 어떤데이터를 어느 정도의 기간으로 올릴지 정해줌
메모리 위에 있는 두 개의 버퍼
데이터 캐시
•
READ
•
I/O 가 필요한 데이터의 일부를 메모리에 유지하기 위해 사용하는 영역
•
우리가 흔히 생각하는 그 “캐시”
로그 버퍼
•
CREATE, UPDATE, DELETE
•
DBMS는 데이터가 갱신될때, 로그 버퍼 위에 변경 정보를 보내고 이후에 I/O 작업을 한다.
•
갱신 처리는 비동기
•
COMMIT 때 메모리→DISK 정보 복사
로그 버퍼 와 휘발성
•
IF 로그 버퍼 위에 있는 데이터가 I/O 작업이 이러나기 전에 장애가 발생해서 사라진다면?
⇒ 복구 불가능
•
DBMS의 갱신을 비동기로 하는 이상 언제든 발생 가능한 문제
•
DBMS 는 commit 시점에 반드시 갱신 전보를 로그 파일(영속) 에 써서 정합성을 유지한다.
⇒ commit 된 데이터 영속화
◦
COMMIT 시에는 반드시 I / O 처리가 일어난다.
데이터캐시와 로그 버퍼의 크기
일반적으로 데이터베이스는 검색을 가정한다
따라서 READ를 담당하는 데이터캐시의 Default 용량이 로그 버퍼의 크기보다 일반적으로 더 크게 설정되어있다.
워킹 메모리
•
정렬 또는 해시 관련 처리에 사용되는 작업용 메모리
•
ORDER BY , GROUP BY, 집합 연산, 윈도우 함수 등의 기능에서 사용
•
반면 해시는 주로 테이블의 결합에서 해시 결합이 사용될 때 실행
특징
•
해시 또는 정렬 처리가 일어날때 사용된다.
•
메모리가 부족하면 SWAP(2차 기억장치-영속장치) 에 임시로 저장해서 메모리처럼 사용한다.
•
아무리 느려져도 에러를 발생시키지 않고, 끝까지 처리한다.

[3강] DBMS 와 실행 계획
권한 이양의 죄악
•
C, Java, Ruby 같은 절차가 기초되는 언어
◦
사용자가 데이터에 접근하기 위한 절치(HOW) 를 책임지고 기술
•
RDB
◦
절차 (HOW)를 시스템에 맡김
◦
사용자는 대상(WHAT) 만 기술하면 된다.
⇒ 비즈니스 생산성 향상

•
WHAT 에 집중하자 는 SQL 이 나온 초기에 생각했던 것이고, HOW 를 의식하지 않고 사용해서 성능 문제로 고생하는 경우가 많다.
•
그래서 우리가 공부해야 한다.
데이터에 접근하는 방법은 어떻게 결정할까?
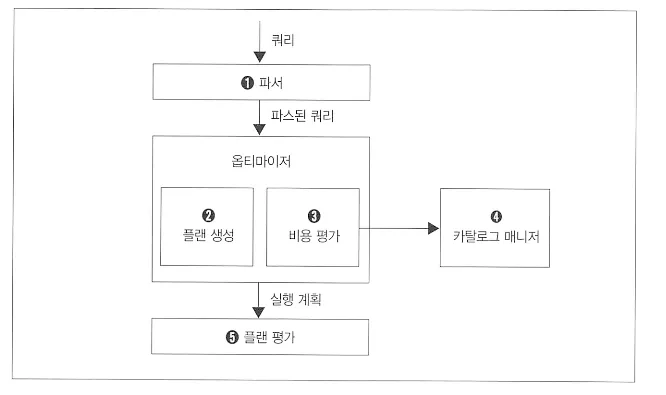
1 파서
•
SQL 구문 분석 - 예외처리
•
SQL 구문 변환 - 정형적인 형식으로 변환 ( 내부에서 일어나는 후속처리를 위한 최적화)
⇒ SQL 문을 AST로 변환한다.
2 (2,3) 옵티마이저
•
RDBMS의 핵심
1.
선택 가능한 많은 실행 계획 을 작성
2.
이들의 비용을 연산
3.
가장 낮은 비용을 가진 실행 계획을 선택
4 카탈로그 매니저
•
카탈로그
◦
DBMS 의 내부 정보를 모아놓은 테이블들
◦
테이블 또는 인덱스의 통계 정보가 저장
⇒ 통계 정보 라고 부른다
5 플랜 평가
•
실행 계획들 중 최적의 실행 결과를 선택
•
실행 계획 은 곧바로 DBMS가 실행할 수 있는 형태의 코드가 아니라, 인간이 보기 편한 형태의 계획서
◦
로우레벨이 아닌 하이레벨
•
절차적인 코드로 변환하고 데이터 접근 수행
옵티마이저와 통계 정보
•
옵티마이저는 명령하는대로 다 잘 처리해주는 만능은 아니다
•
카탈로그 매니저가 관리하는 통계 정보에 대해서는 엔지니어가 항상 신경써야한다.
•
플랜 선택을 100% 옵티마이저에게 맡기는경우, 통계 정보가 부족할때 느려진다.
카탈로그에 포함된 통계 정보
•
각 테이블의 레코드 수
•
각 테이블의 필드 수와 필드 크기
•
필드의 카디널리티 (값의 경우의 수)
•
필드값의 히스토그램 ( 각 값별 분포도)
•
필드 내부에 있는 NULL 수
•
인덱스 정보
⇒ 이러한 정보를 활용해서 옵티마이저는 실행 계획을 만든다.
테이블에 CUD 가 수행될때, 카탈로그 정보가 갱신되지 않는다면 문제가 발생한다.
⇒ Garbage In, Garbage Out
최적의 실행 계획이 작성되게 하려면?
•
올바른 통계 정보가 모이는 것은 매우 중요
•
테이블의 데이터가 많이 바뀌면 카탈로그의 통계 정보도 함께 갱신해야 한다.
◦
수동 갱신
◦
배치 처리할때는 Job Net 을 조합 ⇒ 여러가지 경우의 수 를 그래픽적으로 표현하고 관리
•
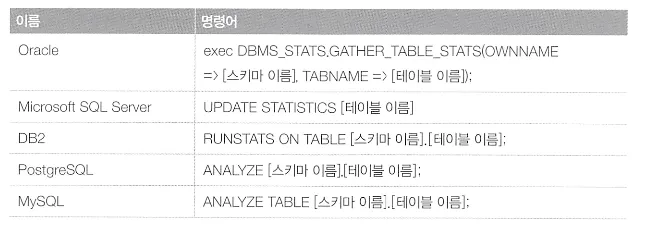
MS SQL은 갱신 처리가 수행되는 시점에 통계 정보 갱신
⇒ 하지만 통계 정보 갱신은 실행 비용이 높은 작업이므로 시점을 잘 검토해야한다.
[4강] 실행 계획이 SQL 구문의 성능을 결정
•
이미 최적의 경로가 설정 되었는데도 느린 경우가 있다
•
통계 정보가 최신이라도 SQL 구문이 복잡하면 옵티마이저가 최적의 선택을 못할 수 있다.
실행 계획 확인 방법

•
공통적인 실행계획 부분
◦
조작 대상 객체
▪
테이블명
▪
인덱스, 파티션, 시퀀스 처럼 SQL 구문으로 조작할 수 있는 객체면 무엇이라도 OK
◦
객체에 대한 조작의 종류
▪
Seq Scan == Sequential Scan
▪
파일을 순차적으로 접근해서 해당 테이블의 데이터 전체를 읽어낸다
▪
TABLE ACCESS FULL 은 테이블 데이터를 전부 읽는다.
◦
조작 대상이 되는 레코드 수
▪
ROWS 항목
▪
얼마만큼의 레코드가 처리되는지 SQL 구문 전체의 실행 비용 파악시 중요 지표
▪
카탈로그로 부터 얻은 값이므로, 실제와 차이가 있을 수 있다. (JIT 의 경우 예외)
테이블 풀 스캔(Full Scan) 의 실행 계획
EXPLAIN EXTENDED SELECT * from cabinet;
SQL
복사
+--+-----------+-------+----+-------------+----+-------+----+----+--------+-----+
|id|select_type|table |type|possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-------+----+-------------+----+-------+----+----+--------+-----+
|1 |SIMPLE |cabinet|ALL |null |null|null |null|398 |100 | |
+--+-----------+-------+----+-------------+----+-------+----+----+--------+-----+
Plain Text
복사
인덱스 스캔의 실행 계획
EXPLAIN EXTENDED SELECT * from user where user_id=3;
SQL
복사
+--+-----------+-----+-----+-------------+-------+-------+-----+----+--------+-----+
|id|select_type|table|type |possible_keys|key |key_len|ref |rows|filtered|Extra|
+--+-----------+-----+-----+-------------+-------+-------+-----+----+--------+-----+
|1 |SIMPLE |user |const|PRIMARY |PRIMARY|8 |const|1 |100 | |
+--+-----------+-----+-----+-------------+-------+-------+-----+----+--------+-----+
Plain Text
복사
•
일반적으로는 스캔하는 모집합 레코드 수 에서 선택되는 레코드 수가 적다면 테이블 풀 스캔보다 빠르게 접근을 수행한다.
•
풀 스캔은 모집합의 데이터 양에 비례해서 처리비용이 늘어난다
•
인덱스는 B-Tree 가 모집합의 데이터 양에 따라 대수 함수적으로 처리 비용이 늘어난다.(완만하게 증가)
◦
레코드 수가 많아지면 차이가 커짐
간단한 테이블 결합의 실행 계획
EXPLAIN EXTENDED
SELECT * from user u
LEFT JOIN lent_history lh ON u.user_id=lh.user_id
where u.user_id=3;
SQL
복사
+--+-----------+-----+-----+--------------------+--------------------+-------+-----+----+--------+-----+
|id|select_type|table|type |possible_keys |key |key_len|ref |rows|filtered|Extra|
+--+-----------+-----+-----+--------------------+--------------------+-------+-----+----+--------+-----+
|1 |SIMPLE |u |const|PRIMARY |PRIMARY |8 |const|1 |100 | |
|1 |SIMPLE |lh |ref |lent_history_user_id|lent_history_user_id|8 |const|1 |100 | |
+--+-----------+-----+-----+--------------------+--------------------+-------+-----+----+--------+-----+
SQL
복사
Nested Loops
•
한쪽 테이블을 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 쭉 다른 테이블에서 찾는 방식
◦
절차 지향형 언어에서 2중 반복문
Sort Merge
•
결합 키로 레코드를 정렬하고, 순차적으로 두 개의 테이블을 결합
•
결합 전 처리로 정렬을 수행 ⇒ 이 때 워킹 메모리를 사용
Hash
•
결합 키 값을 해시값으로 매핑
•
해시 테이블을 만들어야하므로 워킹 메모리 사용
결합 정리
실행 계획은 일반적으로 트리 구조이다.
이때 중첩 단계가 깊을수록 먼저 실행된다.
Nested Loop 보다, Seq Scan과 Index Scan 의 단계가 더 깊으므로, 결합 전에 테이블 접근이 먼저 수행된다.
이때 결합의 경우 어떤 테이블에 먼저 접근하는지가 중요하다.
같은 중첩 단계에서는 위에서 아래로 실행한다.
[5강] 실행 계획의 중요성
•
최근 옵티마이저는 매우 우수 BUT 완벽하지 않다.
•
옵티마이저에게 인덱스 정보를 제대로 줘야한다.
•
테이블 결합 순서를 신경써야 한다.
•
최후의 수단 → 실행 계획 수동 변경
•
Oracle, MySQL 이 가진 hint 구를 사용하면 SQL 구문에서 옵티마이저에게 강제적으로 명령 가능
•
DB2처럼 hint 구가 없는 DBMS 도 있다.
•
SQL 구문들이 어떤 경로로(access path)로 데이터를 검색하는지 아는게 먼저다.
•
공부하자