



26강 - 갱신은 효율적으로
NULL 채우기


SQL문과 실행계획
•
상관 서브쿼리를 이용한다.
•
테이블 seq scan, 즉 풀스캔을 수행한다. 데이터양이 늘어날 경우 인덱스 스캔을 할 것이다.
NULL을 작성
SQL문
•
서브쿼리가 하나의 값을 리턴하는 스칼라 서브쿼리이기 때문에 가능하다.
27강 - 레코드에서 필드로의 갱신
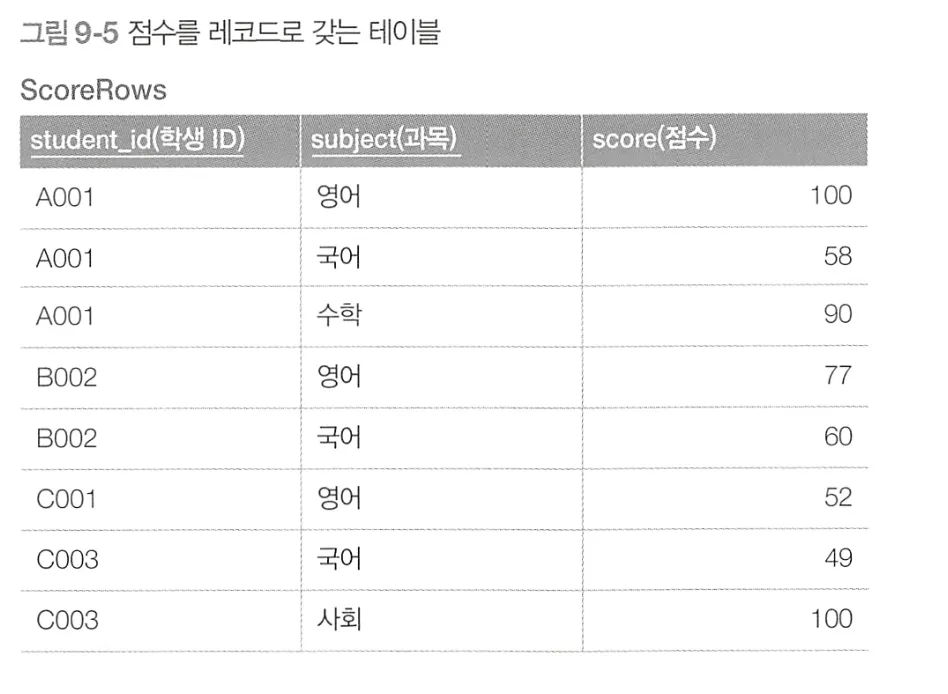

필드를 하나씩 갱신
SQL문과 실행계획
•
간단하고 명확하지만 3개의 상관 서브쿼리를 실행한다는 단점이 있다.
•
갱신해야 할 필드의 수가 늘어날수록 서브쿼리도 많아지므로 성능이 더 악화된다.
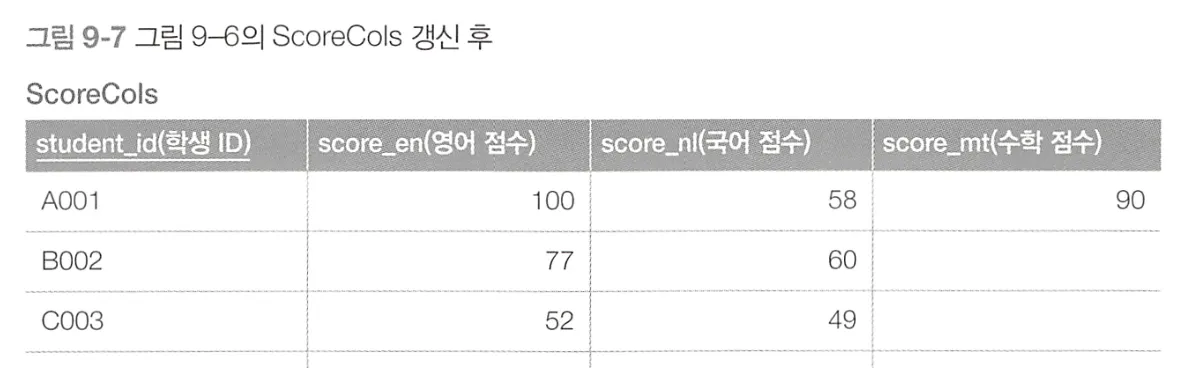
다중 필드 할당
•
여러 개의 필드를 리스트화하고 한 번에 갱신하는 방법
SQL문과 실행계획
•
서브쿼리를 한 번에 처리할 수 있어 성능도 향상되고 코드도 간단해진다.
•
갱신해야 할 필드의 수가 늘어나도 서브쿼리의 수가 늘어나지 않고, 성능 악화도 없다.
•
Index Only Scan이 아닌 Index Range Scan을 실행하고, MAX 함수의 정렬이 추가되는 트레이드오프가 일어난다. 하지만 서브쿼리를 줄이는 것이 훨씬 효율적이다.
NOT NULL 제약이 걸려있는 경우
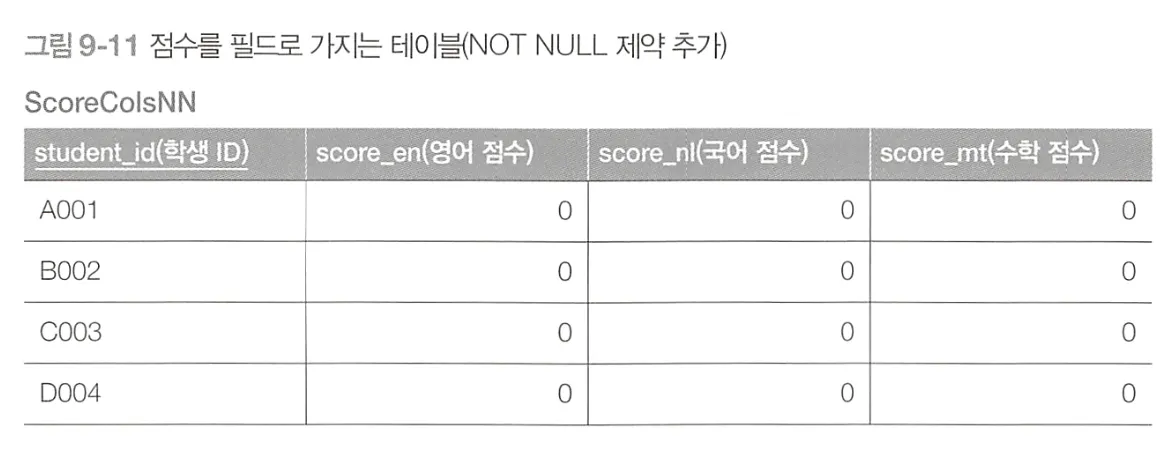
•
UPDATE 구문 사용
SQL문
◦
COALESCE 함수를 이용해서 NULL을 0으로 변경한다.
•
NULL 관련 함수
함수 이름 | 설명 |
NVL(표현식1, 표현식2) / ISNULL(표현식1, 표현식2) | 표현식 1의 결과값이 NULL이면 표현식2의 값을 출력한다. 단, 표현식1과 표현식2의 결과 데이터 타입이 같아야 한다. |
NULLIF(표현식1, 표현식2) | 표현식1이 표현식2와 같으면 NULL을, 같지 않으면 표현식1을 리턴한다. |
COALESCE(표현식1, 표현식2, ...) | 임의의 개수 표현식에서 NULL이 아닌 최초의 표현식을 나타낸다. 모든 표현식이 NULL이라면 NULL을 리턴한다. |
•
MERGE 구문 사용
SQL문과 실행계획
◦
UPDATE와 달리 2개의 장소에 분산되어 있던 조건을 ON구로 한 번에 처리할 수 있다.
◦
풀 스캔 1회 + 정렬 1회가 필요하다. 갱신할 필드가 많아져도 성능 악화될 위험이 없다.
28강 - 필드에서 레코드로 변경
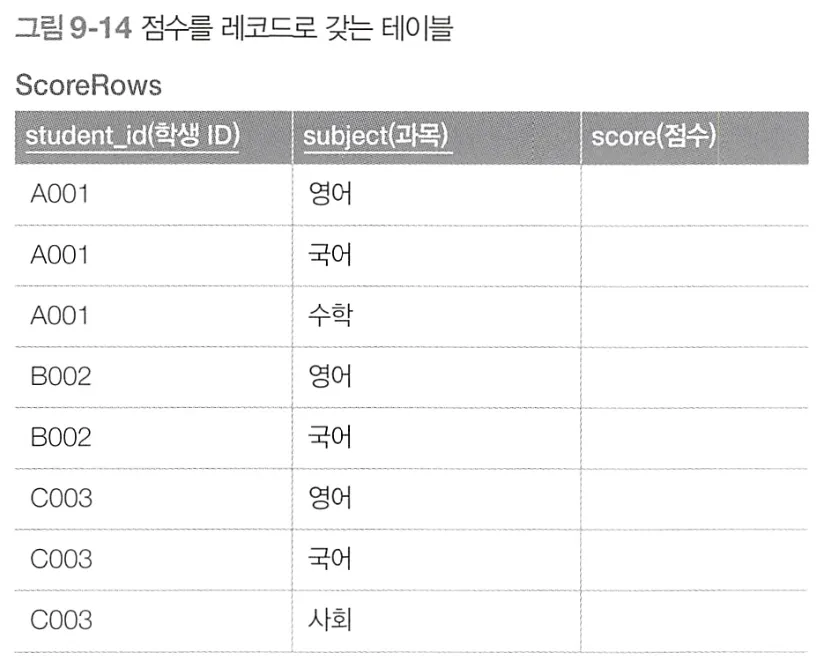
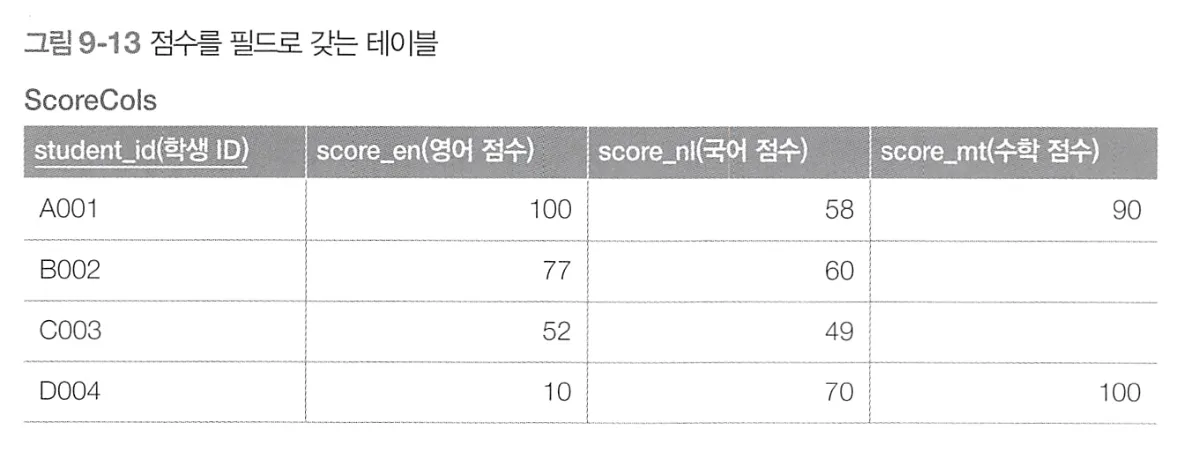
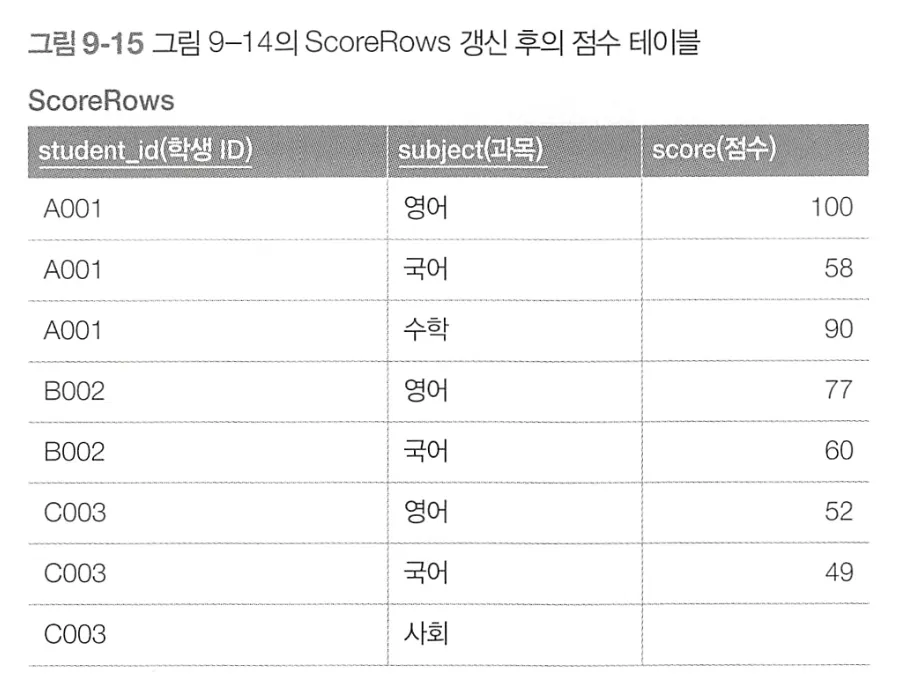
•
CASE식을 이용
SQL문과 실행계획
◦
테이블 접근 1번
◦
기본키 인덱스가 사용되며 정렬과 해시도 없다.
29강 - 같은 테이블의 다른 레코드로 갱신
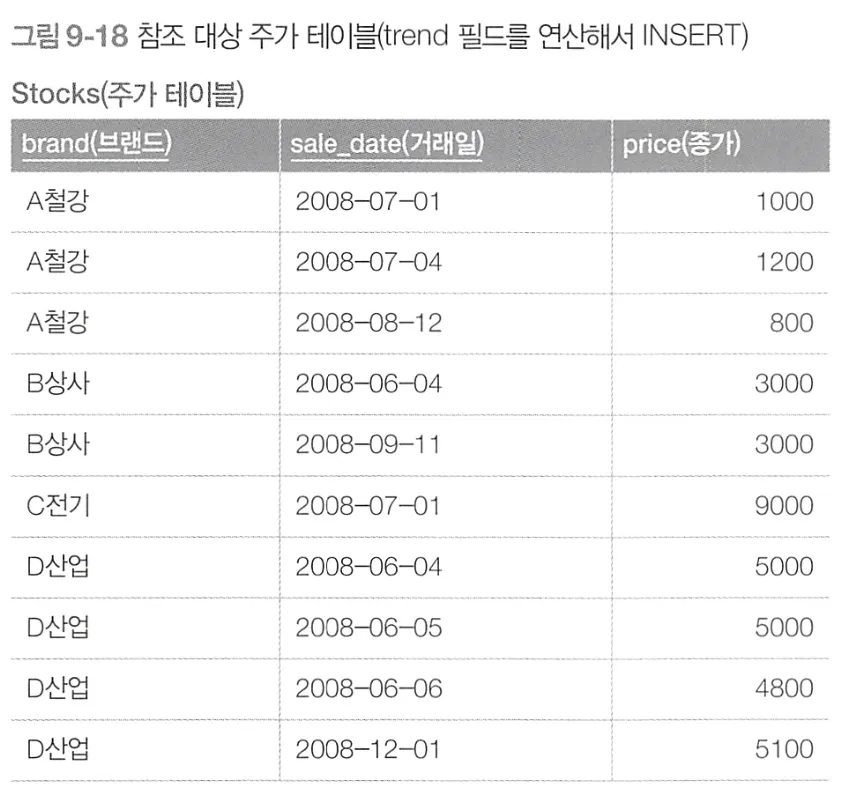
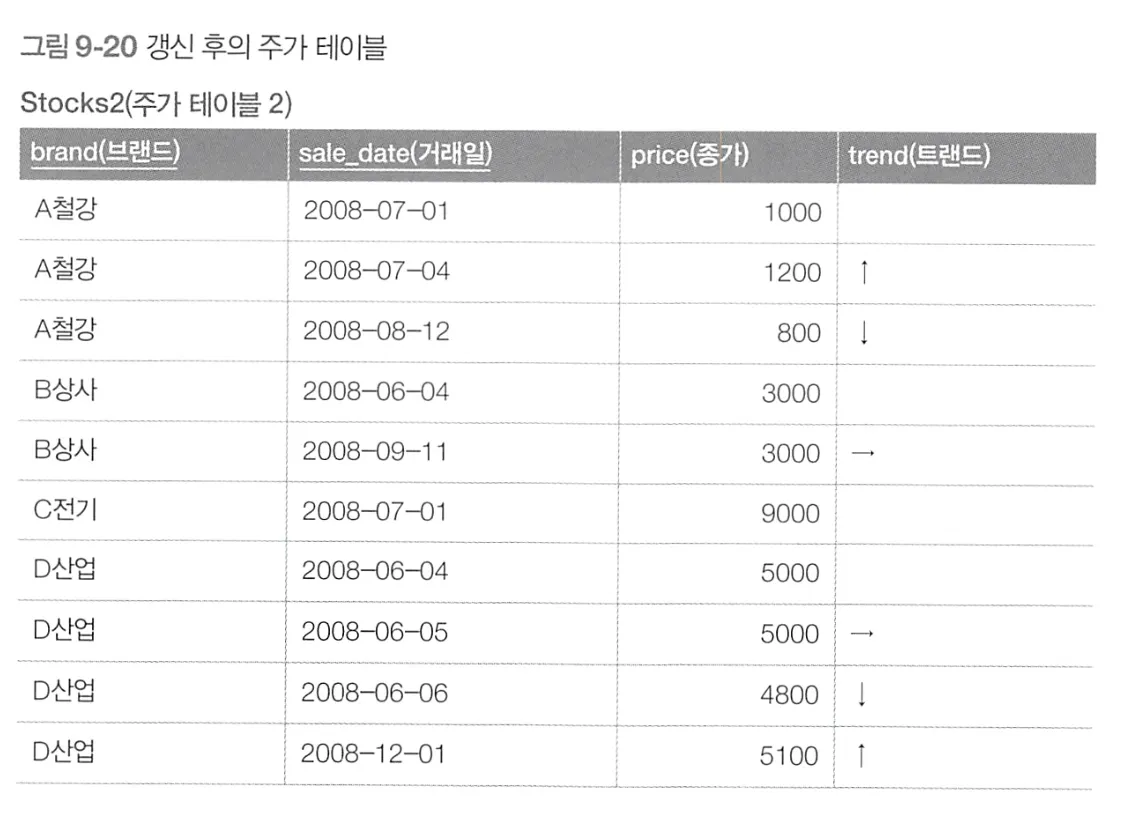
상관 서브쿼리 사용
SQL문과 실행계획
•
상관 서브쿼리로 인해 Stocks 테이블에 여러 차례 접근이 발생한다. 인덱스 온리 스캔과 기본키 인덱스를 사용한 테이블 접근, 테이블 풀 스캔이 수행된다.
윈도우 함수 사용
SQL문과 실행 계획
•
Stocks 테이블에 대한 접근이 풀 스캔 한 번으로 감소한다.
INSERT와 UPDATE 비교
•
INSERT SELECT의 장점
◦
일반적으로 UPDATE에 비해 INSERT SELECT의 성능이 좋다
◦
MySQL처럼 갱신 SQL에서의 자기 참조를 허가하지 않는 데이터베이스에서도 INSERT SELECT를 사용할 수 있다.
•
INSERT SELECT의 단점
◦
같은 크기와 구조를 가진 데이터를 2개 만들어야 한다. → 저장소 용량을 2배 이상 소비한다. (저장소 비용이 낮아지고 있어 큰 단점은 아니다.)
30강 - 갱신이 초래하는 트레이드 오프
•
주문마다 주문일(order_date)와 상품의 배송 예정일(delivery_date)의 차이를 구해 3일 이상이라면 주문자에게 배송 주문이 늦어지고 있다고 알리려고 한다.
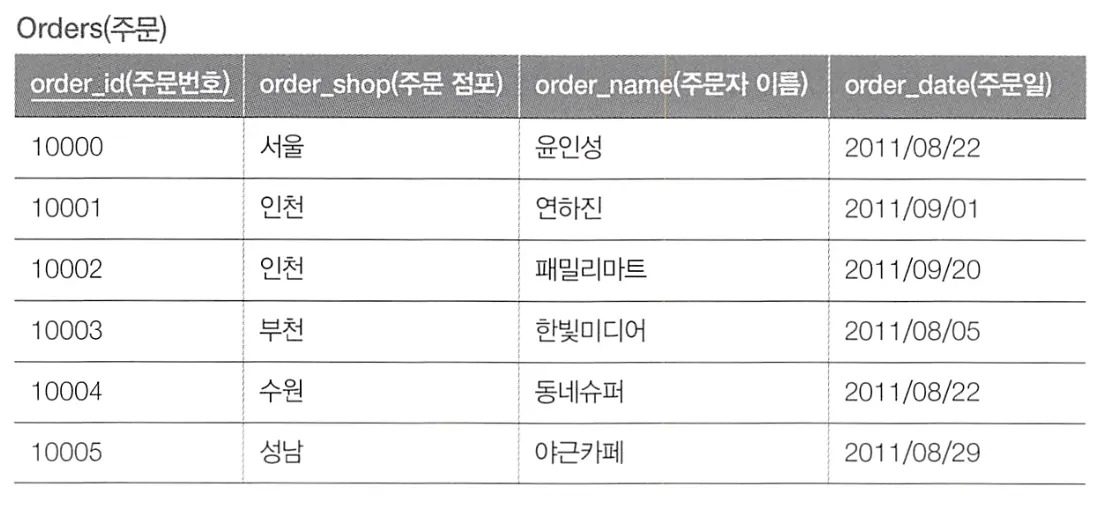
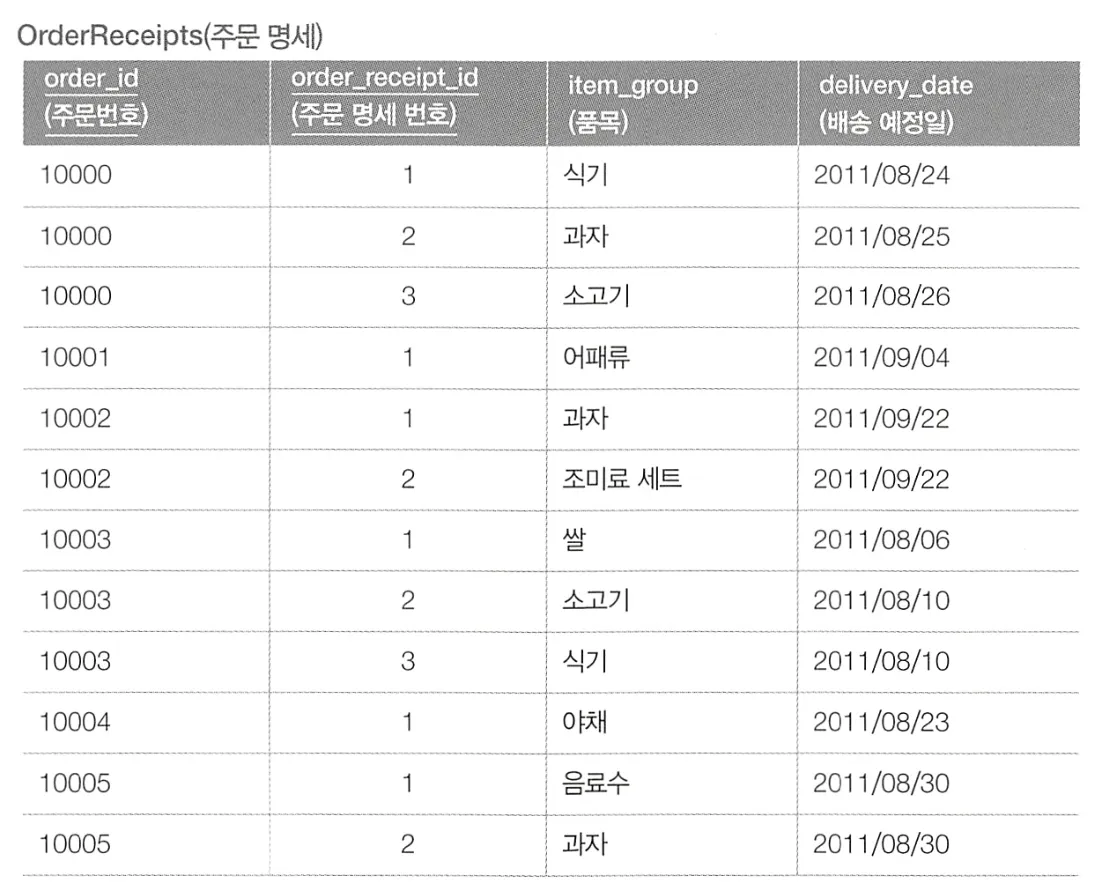
•
SQL을 사용하는 방법
SQL문
•
모델 갱신을 사용하는 방법
◦
결합 또는 집약을 포함한 SQL 구문을 사용하므로 검색 처리에 드는 비용이 높다. 또한, 결합은 실행 계획의 변동 리스크가 있는 만큼 장기적 측면에서 성능을 불안정하게 만든다.
◦
모델 갱신 → 배송이 늦어질 가능성이 있는 주문의 레코드에 대해 플래그 필드를 Orders 테이블에 추가한다.
▪
검색 쿼리는 해당 플래그만을 조건으로 삼으므로 더 간단해진다.
•
SQL 속성의 종류 3가지
ex) 은행에 적금을 들고자 한다. 그래서 우리는 원금을 통장에 입금했다. 이자율은 5%이다.
◦
기본속성 : 업무상 필요한 데이터에 대해 정의. ex) 원금, 이자율
◦
설계속성 : 업무를 규칙화하기 위해 새로 만들거나 변형한 속성. ex) 예금 분류
◦
파생속성 : 다른 속성의 영향을 받아 발생. 주로 계산하는 값들이 이에 해당. ex) 이자
31강 - 모델 갱신의 주의점
높아지는 갱신비용
•
검색 부하 대신 갱신 부하가 발생한다. 레코드를 등록할 때 아직 추가될 필드의 값(개별 상품의 배송 예정일)이 정해져 있지 않은 경우, 플래그 필드를 UPDATE 해야하므로 갱신 비용이 올라간다.
갱신까지의 Time Lag 발생
•
데이터의 실시간성에 문제가 생긴다. 추가된 필드와 기본 필드가 실시간으로 동기화되지 않기 때문이다.
•
야간에 배치 갱신을 통해 일괄 처리하는 경우 Time Lag 기간은 더 길어질 수 있다.
•
실시간성이 중요한 업무일수록 갱신 주기가 짧아야 하고, 이 경우 성능과 실시간성 사이에 트레이드 오프가 발생한다.
모델 갱신비용 발생
•
RDB 데이터 모델 갱신은 코드 기반의 수정에 비해 대대적인 수정이 요구된다.
32강 - 시야 협착 : 관련 문제
경계해라~ 초급자보단 중급자가 더 경계해야 한다.
33강 - 데이터 모델을 지배하는 자가 시스템을 지배한다
의외로 데이터 모델 차원에서 대응하면 쉽게 해결할 수 있다.
데이터 모델이 코드를 결정한다. 코드가 데이터 모델을 결정하는 것이 아니다.
추후 테이블 구조를 바꾸는 것은 어렵고, 권한도 문제가 되니 처음부터 잘 설계하자~