
.gif&collectionId=dcb50d88-6307-4897-975e-13c151621a8a)


Cabi에 CQRS가 필요한 이유
불필요한 데이터 조회
현재 사물함에 대여 기록을 조회하면, 사물함의 CabinetId로 LentHistory와 User를 Join 연산하여 조회하여 이름을 가져온다. 이 과정에서 DB에서 조회해오는 데이터들은 다음과 같다.
•
LentHistory
◦
대여 날짜
◦
만료 날짜
◦
반납 날짜
◦
cabinetId
◦
userId
•
User
◦
유저 블랙홀 날짜
◦
유저 계정 삭제 날짜(null)
◦
이메일 주소
◦
이름
◦
역할(사용자 or 관리자)
◦
슬랙 알람 수신 정보
◦
이메일 알람 수신 정보
◦
푸시 알람 수신 정보
이 중 대여 기록에는 LentHistory에서 cabinetId, 대여 날짜, 반납 날짜 / User에서 이름, 이렇게 딱 4개의 정보만 사용하여 응답을 보내준다. 이처럼 현재 구조에서는 사용하지 않는 불필요한 정보들이 다수 포함되어 있다. 이를 CQRS 없이 개선하기 위해서는 DAO와 Projection을 통해 데이터를 선택하여 가져와야한다.
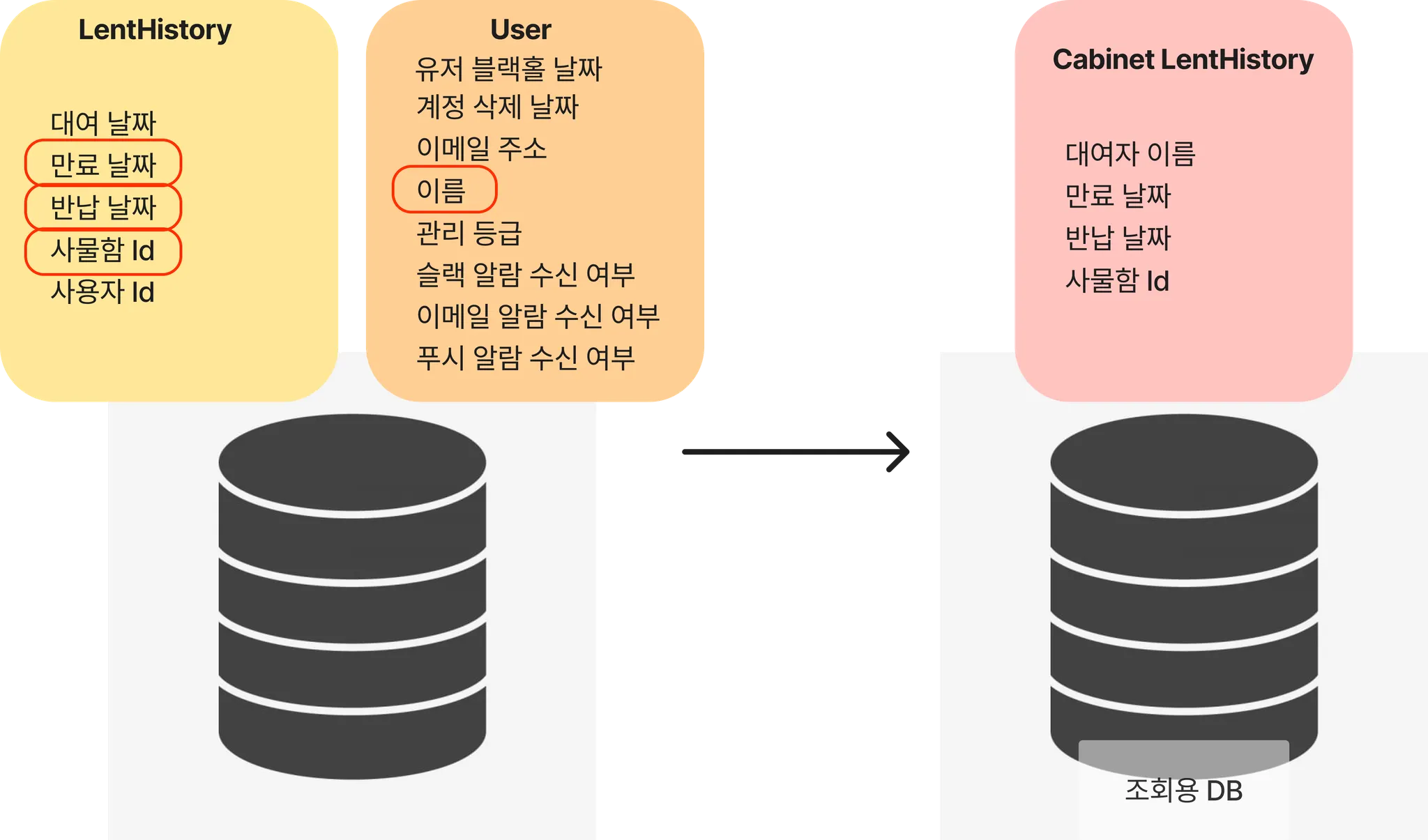
CQRS를 적용하면 각 조회에 맞춰 필요한 데이터만 저장하여, 이와 같은 불필요한 데이터의 조회를 해결할 수 있다.
복잡한 조회 로직 개선
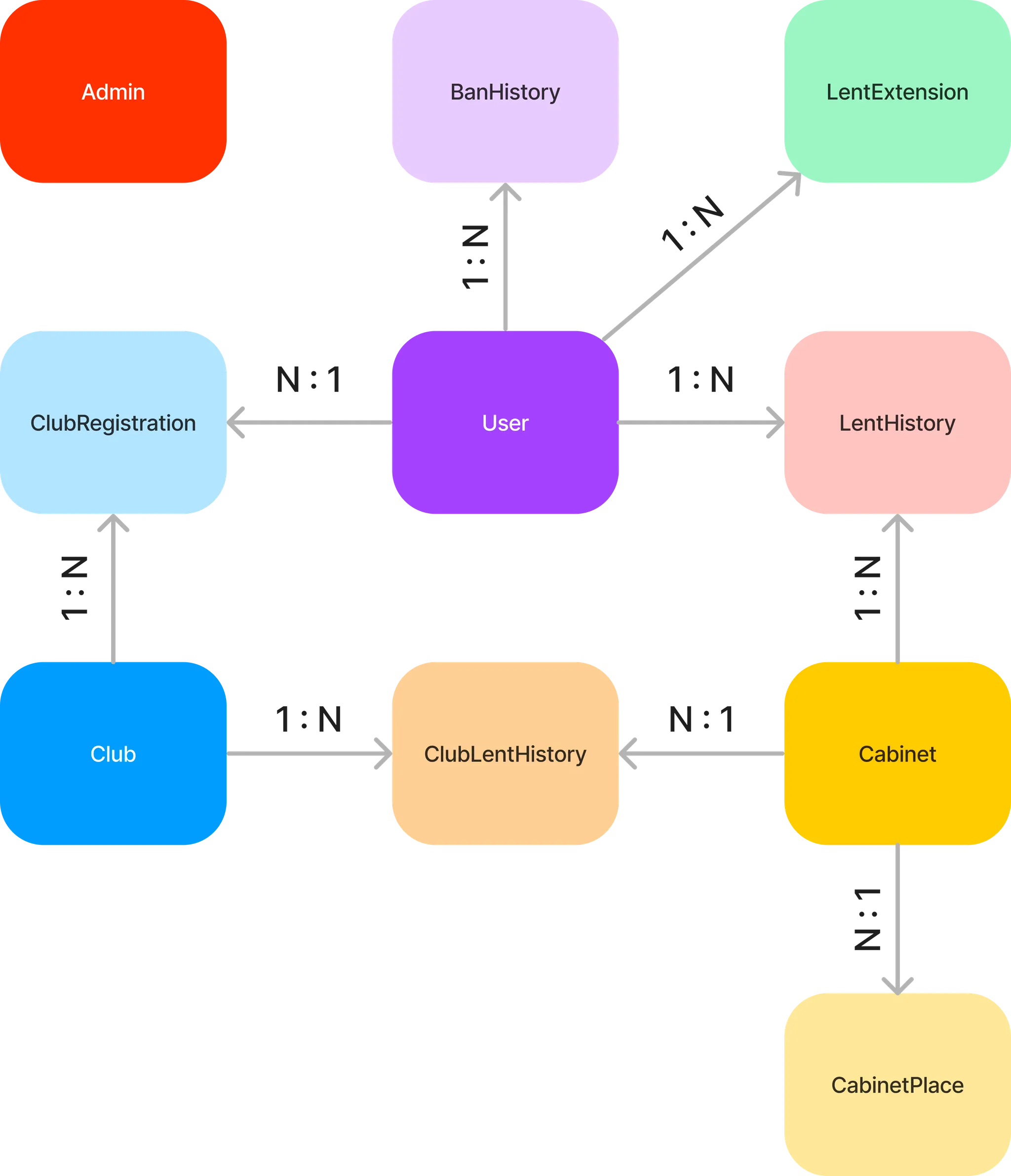
위 구조처럼 User - LentHistory - Cabinet / User - ClubRegistration - Club / Cabinet - ClubLentHistory - Club 처럼 1 : N - M : 1 구조를 가지는 테이블이 6개나 되고, 그 외에도 다수의 1 : N 연관관계를 가지는 테이블들이 있다.
이런 복잡한 구조로 인해 조회 로직에 Join 연산을 굉장히 자주 사용해야하고, 심지어 2중, 3중 Join 연산까지 사용하는 경우도 있다.
현재 Cabi에서 가장 많이 조회되는 API는 CabinetPerSection과 PendingCabinet 로직이다. 로직이 복잡한 것은 둘째치더라도, 당연하게도 이 두 로직에서도 3중 Join 연산을 사용한다.
•
CabinetPerSection 조회 로직
List<ActiveCabinetInfoEntities> activeCabinetInfos = cabinetQueryService.findActiveCabinetInfoEntities(building, floor);
Map<Cabinet, List<LentHistory>> cabinetLentHistories = activeCabinetInfos.stream().
collect(groupingBy(ActiveCabinetInfoEntities::getCabinet,
mapping(ActiveCabinetInfoEntities::getLentHistory, Collectors.toList())));
List<Cabinet> allCabinetsOnSection =
cabinetQueryService.findAllCabinetsByBuildingAndFloor(building, floor);
Map<Long, List<ClubLentHistory>> clubLentMap =
clubLentQueryService.findAllActiveLentHistoriesWithClub().stream()
.collect(groupingBy(ClubLentHistory::getCabinetId));
Map<String, List<CabinetPreviewDto>> cabinetPreviewsBySection = new LinkedHashMap<>();
allCabinetsOnSection.stream()
.sorted(Comparator.comparing(Cabinet::getVisibleNum))
.forEach(cabinet -> {
String section = cabinet.getCabinetPlace().getLocation().getSection();
if (cabinet.getLentType().equals(LentType.CLUB)) {
if (!clubLentMap.containsKey(cabinet.getId())) {
cabinetPreviewsBySection.computeIfAbsent(section,
k -> new ArrayList<>())
.add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, null));
} else {
clubLentMap.get(cabinet.getId()).stream()
.map(c -> c.getClub().getName())
.findFirst().ifPresent(clubName -> cabinetPreviewsBySection
.computeIfAbsent(section, k -> new ArrayList<>())
.add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, clubName)));
}
return;
}
List<LentHistory> lentHistories =
cabinetLentHistories.getOrDefault(cabinet, Collections.emptyList());
String title = getCabinetTitle(cabinet, lentHistories);
cabinetPreviewsBySection.computeIfAbsent(section, k -> new ArrayList<>())
.add(cabinetMapper.toCabinetPreviewDto(cabinet, lentHistories.size(),
title));
});
return cabinetPreviewsBySection.entrySet().stream()
.map(entry -> cabinetMapper.toCabinetsPerSectionResponseDto(entry.getKey(),
entry.getValue()))
.collect(Collectors.toList());
Java
복사
•
PendingCabinet 조회 로직
final LocalDateTime now = LocalDateTime.now();
final LocalDateTime yesterday = now.minusDays(1).withHour(13).withMinute(0).withSecond(0);
List<Cabinet> pendingCabinets =
cabinetQueryService.findPendingCabinetsNotLentTypeAndStatus(
building, LentType.CLUB, List.of(AVAILABLE, PENDING));
List<Long> cabinetIds = pendingCabinets.stream()
.filter(cabinet -> cabinet.isStatus(PENDING))
.map(Cabinet::getId).collect(Collectors.toList());
Map<Long, List<LentHistory>> lentHistoriesMap;
if (now.getHour() < 13) {
lentHistoriesMap = lentQueryService.findPendingLentHistoriesOnDate(
yesterday.toLocalDate(), cabinetIds)
.stream().collect(groupingBy(LentHistory::getCabinetId));
} else {
lentHistoriesMap = lentQueryService.findCabinetLentHistories(cabinetIds)
.stream().collect(groupingBy(LentHistory::getCabinetId));
}
Map<Integer, List<CabinetPreviewDto>> cabinetFloorMap =
cabinetQueryService.findAllFloorsByBuilding(building).stream()
.collect(toMap(key -> key, value -> new ArrayList<>()));
pendingCabinets.forEach(cabinet -> {
Integer floor = cabinet.getCabinetPlace().getLocation().getFloor();
if (cabinet.isStatus(AVAILABLE)) {
cabinetFloorMap.get(floor).add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, null));
}
if (cabinet.isStatus(PENDING)) {
lentHistoriesMap.get(cabinet.getId()).stream()
.map(LentHistory::getEndedAt)
.max(LocalDateTime::compareTo)
.ifPresent(latestEndedAt -> cabinetFloorMap.get(floor)
.add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, null)));
}
});
return cabinetMapper.toCabinetPendingResponseDto(cabinetFloorMap);
Java
복사
CQRS를 적용하면 이처럼 복잡한 조회 로직들을 개선하고, Join 연산을 줄여 성능적 측면이나 유지보수성, 코드 재활용성에서 더 좋아질 것으로 예상된다.
Lock 경쟁 최소화 및 조회 성능 최적화
현재 Cabi 정책상 티켓팅 방식을 적용하고 있기 때문에, Lock 경쟁이 자주 발생할 수 밖에 없는 상황이다. CQRS를 적용하면 조회는 별도의 DB에서 수행하게 되기 때문에, 명령 간의 Lock 경쟁은 발생해도 조회와 명령 간의 Lock 경쟁은 발생하지 않는다. 또한 별도의 조회용 DB 사용으로 인해, 조회에 필요한 데이터만 가공하여 저장해 조회 성능 극대화할 수 있다.
CQRS의 단점
그럼 CQRS를 적용함으로 인해 발생하는 단점들에 대해 알아보자.
•
복잡한 구조
MSA가 적용되지 않았기 때문에, 전체 구조에서 조회 모델과 명령 모델이 분리되는 수준으로 크게 복잡해지지 않는다. 그에 더해 구조가 복잡해져 이해하기 어려워지는 것보다 CQRS로 인한 장점이 더 크기 때문에 충분히 감수할만한 단점인 것 같다.
•
이벤트 실패
MSA는 서버 간 이벤트 전송을 API로 호출하기 때문에, 이벤트 유실 혹은 실패 시 대책이 필요하다. 하지만 Cabi는 MSA가 적용이 되어있지 않기 때문에 이벤트 유실 가능성 낮고, spring에서 여러 이벤트 관련 트랜잭션 기능을 지원하기 때문에 이벤트가 실패하더라도 그리 어렵지 않게 복구할 수 있다. 때문에 추후 MSA가 도입되는 것이 아니라면, 굳이 이벤트 소싱 패턴까지 적용할 필요는 없어 보인다.
•
명령 처리 시 데이터 일관성 지연 반영
티켓팅에서는 실시간으로 정보를 확인할 필요가 있지만, MSA를 통한 API 호출로 이벤트를 처리하는 것이 아니라서 지연이 그리 크지 않을 것이다. 또한 명령 자체는 X Lock을 잠그고 대여 가능한지 검증 후 수행하기 때문에, 대여에 실패한 것을 확인 시켜줄 수 있다. 대여를 누른 이후 백엔드에 새로운 데이터를 요청해 렌더링을 다시하기 때문에, CQRS 구현 후 확인 해봐야하지만 대여에 실패하는 경우 X Lock을 대기하는 시간동안 충분히 조회 DB에 변경사항이 반영될 것으로 예상한다.
이와 같이 CQRS를 적용하면 얻을 수 있는 장점과 단점을 비교해보았을 때, 불필요한 데이터 조회를 막고 복잡한 조회 로직을 개선하며 조회 성능을 극대화하는 장점이 단점에 비해 명확하여 Cabi 서비스에 CQRS를 적용해보고자 한다.
CQRS 구조 설계하기
적용할 CQRS 구조
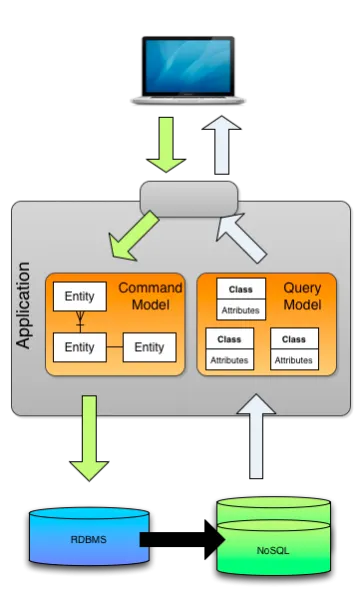
전체 구조는 위 그림과 같이 기존의 Cabi 서비스에서 조회 모델과 명령 모델을 분리하고, Redis를 조회 모델에서 사용하는 조회용 NoSQL DB로 사용한다. RDBMS와 NoSQL의 동기화는 별도의 Broker 없이, Hibernate EventListener를 통해 동기화하여 데이터 일관성을 유지한다.
조회 데이터 구조
사실 CQRS를 하면 대부분 역정규화를 통해 조회 속도를 높이도록 개선한다. 하지만 Cabi에서는 역정규화를 적용하기엔 몇 가지 문제가 있다.
•
8개의 1:N 연관관계 결합
현재 Cabi에는 User - Cabient / Cabinet - Club / Club - User가 서로 맞물려서 ManyToMany 구조로 중간 테이블을 두고 있다. 이 중간 테이블들을 역정규화하게 되면 수많은 데이터를 저장하고 관리해야한다. 단편적인 예시로 User 1000개 * LentHistory 10000개로, User - LentHistory를 역정규화를 적용하는 순간 데이터 천만 개를 저장하고 관리해야하는 것이다. 이런 역정규화로 인한 카르테시안 곱만큼 데이터를 저장하고 관리해야하기 때문에, 역정규화를 적용하기에는 무리가 있다.
•
다양한 조회 데이터
Cabi에서 조회되는 데이터를 분석하며 필요한 데이터를 살펴보았을 때, userId에 따라 User → LenHistory → Cabinet 순으로 조회가 수행되는 경우도 있고 반대로 cabinetId에 따라 Cabinet → LentHistory → User 순으로 조회가 수행되는 경우도 있다. 이런 다양한 조회 데이터를 유연하게 사용하기 위해서는 역정규화 없이 각 테이블별로 Id를 key로 두고 관리해야할텐데, 그렇게 사용한다면 사실상 RDBMS를 사용하는 것과 큰 차이가 없다.
이런 이유들로 역정규화를 적용할 수 없으니, 각 조회 시 응답으로 보내는 데이터의 양식에 맞추어 조회 데이터를 저장해두는 것이 좋아보인다. 다만 이렇게 관리할 경우, CUD 명령 수행 시 조회 데이터의 여러 부분을 반복적으로 데이터를 수정해야하는 문제가 생긴다. 이 부분은 조회 성능을 떨어뜨리지 않는 선에서 최대한 중복되는 데이터는 하나의 조회 데이터에 뭉쳐두고, 조회 시에 필요 없는 부분만 쳐내는 식으로 구현해보고자 한다.
Redis 메모리 사용량 분석 및 용량 확인
현재 Redis로 공유 사물함 세션, FCM 디바이스 토큰, Swap 만료 기한, 이전 사물함 이용자 이름을 저장하고 있다.
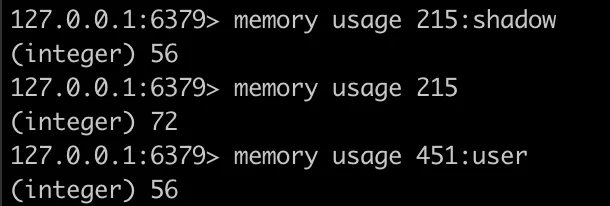
•
공유 사물함 session : 세션 한 개당 다 합쳐 대략 200~300byte 정도로, 10분간만 유지되는 세션 특성상 최대 3KB를 넘지 않을 것으로 예상된다.
•
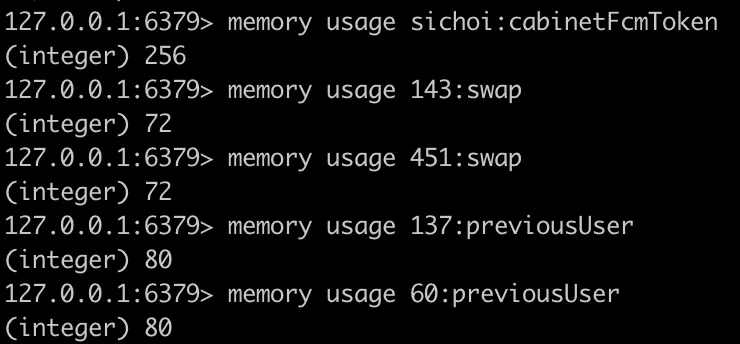
FCMToken : 개당 256byte로 최대 400명 사용 시 대략 100KB 정도 예상된다.
•
swap : 개당 72byte로 최대 400명 사용 시 28KB 정도 예상된다.
•
perviousUser : 개당 80byte로 최대 사물함 400개 사용 시 31KB 정도 예상된다. 하지만 이는 캐싱 용도로, CQRS 적용 시 불필요하게되어 삭제되고 다른 형태로 저장될 예정이다.
현재 사용 중인 메모리 용량을 확인했으니, 조회용 DB로 사용하게 될 경우 메모리를 얼마나 차지할 것인지 예상해보자. 사물함을 눌렀을 때, 해당 사물함에 대한 정보를 조회하는 로직의 데이터를 직접 입력하여 메모리 사용량을 확인해보았다.
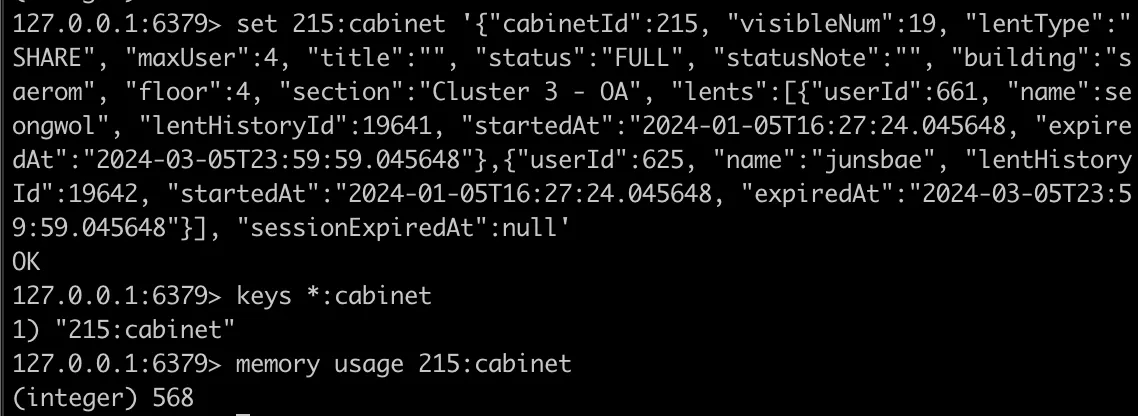
공유 사물함의 경우 현재 대여 중인 lenthistory까지 포함하여 저장하는데 400~600 byte 정도로, 사물함 400개 정보를 전부 저장해도 160KB 정도 사용한다.

DB에서 레코드가 가장 많은 대여기록의 경우에는 한 개당 256byte로, 최대 11000개를 저장하면 2.7MB 정도 사용한다.
현재 사용 중인 메모리 200KB 이하 + CQRS 적용 시 5~8MB 추정으로 최종적으로 10MB를 넘지 않을 것으로 예상된다. Redis에 적용된 maxmemory는 1GB로, CQRS를 적용하더라도 메모리가 굉장히 넉넉할 것으로 예상된다.
이벤트 처리
CQRS에서는 명령 처리 후 데이터 동기화를 Broker나 이벤트 소싱을 통해 수행한다. Cabi에서는 Spring에서 지원하는 여러 이벤트 API를 통해, 이벤트 소싱 패턴을 적용하여 CQRS 데이터 동기화를 수행하고자 한다.
기존 Cabi에서는 알람 작업 등에서 ApplicationEventPublisher와 EventListener 애노테이션을 통해 이벤트 처리했다. 하지만 이러한 방식을 CQRS에 그대로 적용하면 십수 개의 모든 명령 API 요청마다 이벤트를 publish 해야하고 또한 각 요청마다 이벤트를 받을 클래스를 만들고 EventListener 애노테이션을 달아둬야하는 번거로움과 복잡함이 발생한다.
이러한 이유로 이번 CQRS에서 JPA EventListener와 Hibernate EventListener 중에 하나를 선택하여 사용하고자 한다. JPA EventListener의 경우 간편하고 쉽게 구현이 가능하지만, 그만큼 기능이 한정적이고 데이터의 변화를 추적하기 어렵다. Hibernate EventListener의 경우 사용이 어렵지만, 다양한 이벤트를 지원하고 데이터의 변화를 추적할 수 있다.
Cabi에는 몇 가지 이유로 JPA EventListener를 적용하기로 결정했다.
•
첫 번째 이유로 확장성을 고려한다 하더라도 Hibernate에서 제공하는 많은 기능들을 활용할만큼 다양한 상황에 대처할 필요가 없을 것으로 예상되기 때문이다.
•
두 번째 이유로는 데이터의 변화 추적을 통해 변화하는 데이터만 수정하더라도, 결국 key-value로 저장하는 redis 특성상 key 단위로 조회 - 파싱 - 수정 - 저장이 일어날 것이다. 그러므로 이전의 데이터가 있고 없고는 수정하여 저장하는 용량에 전혀 영향을 미치지 않는다.
•
세 번째 이유로는 Cabi라는 동아리 특성상 상대적으로 공부를 많이한 사람들은 취업해서 나갈 확률이 높고, 새로 동아리에 들어오는 사람들은 공부를하기 위해서 들어오는 경우가 많아, 이해하기 쉽고 사용하기 간편한 쪽이 유리하기 때문이다. 두 EventListener의 몇 가지 기능을 직접 사용해보았을 때, JPA EventListenr 쪽이 직관적으로 이해하기 쉽고 사용하는 입장에서도 더 간편하게 사용할 수 있었다.
조회 API 데이터 정리
Admin 패키지
/v4/admin/cabinets/status/{status}
/v4/admin/cabinets/{cabinetId}/lent-histories
/v4/admin/clubs
/v4/admin/search/cabinets-simple
/v4/admin/search/cabinets
/v4/admin/search/users-simple
/v4/admin/search/users
/v4/admin/statistics/buildings/floors/cabinets
/v4/admin/statistics/lent-histories
/v4/admin/statistics/users/banned
/v4/admin/statistics/users/overdue
/v4/admin/users/{userId}/lent-histories
Cabinet 패키지
/v4/cabinets/buildings/floors
/v4/cabinets/buildings/{building}/floors
/v4/cabinets/buildings/{building}/floors/{floor}
/v4/cabinets/{cabinetId}
/v4/cabinets/buildings/{building}/available
Club 패키지
/v4/clubs
/v4/clubs/{clubId}
Lent 패키지
/v4/lent/me
/v4/lent/me/histories
User 패키지
/v4/users/me
명령 이벤트 처리
이벤트 처리 시 데이터를 RDB에서 조회 → 변경사항 발생한 부분 전부 조회 DB 업데이트 처리
Admin 패키지
/v4/admin/cabinets/{cabinetId}/status-note
/v4/admin/cabinets/{cabinetId}/title
/v4/admin/cabinets
/v4/admin/cabinets/{cabinetId}/grid
/v4/admin/cabinets/{cabinetId}/visible-num
/v4/admin/clubs
/v4/admin/clubs/{clubId}
/v4/admin/clubs/{clubId}
/v4/admin/clubs/{clubId}/cabinets/{cabinetId}
/v4/admin/clubs/{clubId}/cabinets/{cabinetId}
/v4/admin/return-cabinets
/v4/admin/return-users
/v4/admin/users/{userId}/ban-history
Club 패키지
/v4/clubs/{clubId}/users
/v4/clubs/{clubId}/users/{userId}
/v4/clubs/{clubId}/mandate
Lent 패키지
/v4/lent/cabinets/{cabinetId}
/v4/lent/cabinets/share/{cabinetId}
/v4/lent/cabinets/share/cancel/{cabinetId}
/v4/lent/return
/v4/lent/return-memo
/v4/lent/me/cabinet
/v4/lent/swap/{cabinetId}
User 패키지
/v4/users/me/lent-extensions
/v4/users/me/alarms
그 외
블랙홀 스케줄링
연체 스케줄링
공유 사물함 상태 변경 스케줄링
데이터 일괄 동기화 로직
CQRS 패턴 적용하기 - 1차
JPA EventListener
이처럼 JPA EventListener를 사용하면 Entity 내에 여러 애노테이션을 통해 생명주기와 관련하여 이벤트를 처리할 수 있다. 하지만 Cabi 구조에서는 LentHistory 엔티티 자체는 Domain 레벨로, 엔티티 자체에서 Service 로직을 불러서 사용하거나 Repository를 호출하는 것이 구조에 맞지 않게 느껴졌다.
이를 해결하기 위해 찾아보니,
// Entity Wrapping EventListener
@Component
@NoArgsConstructor
public class CqrsEventListener {
...
}
// Entity
@Entity
...
@EntityEventListener(value = CqrsEventListener.class)
public class LentHistory {
...
}
Java
복사
위처럼 별도의 Entity Listener로 등록할 클래스를 만들어두고 엔티티를 @EntityEventListener 애노테이션을 통해 이벤트 리스너에 등록해두면, 해당 엔티티의 업데이트 콜백을 이벤트 리스너에서 처리할 수 있다고 한다. 추가적으로 이 방법을 사용하면, 여러 엔티티에 동일한 콜백을 코드 중복 없이 간단하게 적용할 수 있다.
Redis 설정하기
이전에 Redis를 설정할 때 작성했던 글을 참고하여, Redis를 Repository로 사용하기 위한 설정들을 추가해주었다.
@Component
@Logging(level = LogLevel.DEBUG)
public class CqrsRedis {
private final RedisTemplate<String, String> redisTemplate; // expire 같은 조금 더 많은 기능을 지원
private final HashOperations<String, String, String> hashTemplate; // hash 사용 가능
private final ValueOperations<String, String> valueTemplate;
private final ObjectMapper objectMapper;
@Autowired
public CqrsRedis(RedisTemplate<String, String> redisTemplate,
RedisTemplate<String, String> hashTemplate,
RedisTemplate<String, String> valueTemplate,
ObjectMapper objectMapper) {
this.redisTemplate = redisTemplate;
this.hashTemplate = hashTemplate.opsForHash();
this.valueTemplate = valueTemplate.opsForValue();
this.objectMapper = objectMapper;
}
}
Java
복사
이벤트 처리 구조에 대한 고민
CQRS 패턴을 적용하려면 RDBMS에 있는 데이터들을 Redis의 조회 데이터와 동기화 시키는 로직과 이벤트를 통한 엔티티 수정 시 조회 데이터 수정이 필요하다. 해당 로직에서 어떤 방법을 사용하더라도 각 조회 데이터들을 순회하며 해당하는 값을 고쳐야만 하는 과정이 불편하게 느껴졌다. 구조적으로 가독성과 유지보수성을 지키면서, 이렇게 명령 이벤트 처리 시마다 조회 데이터들을 순회하는 로직을 줄일 수 없을까 고민하게 되었다.
각 엔티티마다 수정사항 발생 시 수정해야하는 조회 데이터들을 저장하는 방법도 생각했는데, 확인하는 조회 데이터만 줄어들 뿐 근본적인 문제가 해결되지 않고 오히려 처음 이 구조를 공부하는 사람 입장에서는 가독성이 줄어들 것 같다는 의견을 받았다.
같이 공부하는 wchae님, eunbikim님과 함께 이 문제를 고민해봤지만 이에 대한 마땅한 해결책을 찾지 못했다. 어떤 문제든 실제 해보고 나면 느끼는 바가 달라지기 때문에, 전체적인 CQRS 패턴 적용보다는 위에서 언급한 가장 자주 조회되면서도 복잡한 로직을 가지고 있는 로직 2개 위주로 우선적으로 적용해보고 나머지 조회 로직들에 대한 CQRS 패턴 적용은 그 이후에 다시 고민해보기로 결정했다.
구현 예시 - PendingCabinet 조회 로직 CQRS 패턴 적용
•
Redis 조회, 삭제 기능 구현
private <T> String dtoToString(T dto) {
if (dto == null) {
return null;
}
try {
return objectMapper.writeValueAsString(dto);
} catch (JsonProcessingException e) {
log.error("DTO to JSON Parse Error : {}, {}", dto, e.toString());
throw ExceptionStatus.INTERNAL_SERVER_ERROR.asDomainException();
}
}
private <T> T stringToDto(String value) {
if (value == null) {
return null;
}
try {
//@formatter:off
return objectMapper.readValue(value, new TypeReference<>() {});
//@formatter:on
} catch (JsonProcessingException e) {
log.error("String to JSON Parse Error : {}, {}", value, e.toString());
throw ExceptionStatus.INTERNAL_SERVER_ERROR.asDomainException();
}
}
Java
복사
Redis에서는 Redis에서 DTO 데이터-문자열 간의 변환과 데이터를 꺼내고 저장하는 기능을 구현하였다. objectMapper를 통해 조회 DTO 형태로 저장하거나 조회하기 위해, 위와 같이 일괄적으로 데이터 변환과 예외를 처리하는 메서드를 만들었다.
•
Service 작성
public void addPendingCabinet(Cabinet cabinet) {
Location location = cabinet.getCabinetPlace().getLocation();
String floor = location.getFloor().toString();
List<CabinetPreviewDto> pendingCabinets = cqrsRedis.getPendingCabinets(floor);
pendingCabinets.add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, null));
pendingCabinets.sort(Comparator.comparing(CabinetPreviewDto::getVisibleNum));
cqrsRedis.setPendingCabinet(floor, pendingCabinets);
}
Java
복사
Service에서는 이처럼 Redis에서 조회한 DTO 데이터를 추가 혹은 삭제의 가공하는 단일 책임을 기준으로 작성하였다.
•
Manager 작성
@Transactional(readOnly = true)
public void synchronizeCabinet(Cabinet cabinet) {
List<LentHistory> cabinetLentHistories =
lentQueryService.findCabinetLentHistoriesWithUserAndCabinet(cabinet.getId());
this.syncAll(cabinet, cabinetLentHistories);
}
private void syncAll(Cabinet cabinet, List<LentHistory> cabinetLentHistories) {
this.syncPendingCabinet(cabinet, cabinetLentHistories);
// this.syncCabinetPerSection(cabinet, cabinetLentHistories);
}
private void syncPendingCabinet(Cabinet cabinet, List<LentHistory> cabinetLentHistories) {
if (cabinet.isStatus(AVAILABLE)) {
cqrsService.addPendingCabinet(cabinet);
} else if (cabinet.isStatus(PENDING)) {
LocalDate yesterday = LocalDateTime.now().minusDays(1).toLocalDate();
LentHistory recentLentHistory = cabinetLentHistories.stream()
.max(Comparator.comparing(LentHistory::getEndedAt)).orElse(null);
if (recentLentHistory != null && recentLentHistory.isSameEndedAtDate(yesterday)) {
cqrsService.addPendingCabinet(cabinet);
}
}
}
Java
복사
이처럼 Manager는 특정 엔티티를 받아 해당 엔티티의 여러 조건들을 따져 DTO에 수정 내용이 반영되어야 하는 지점을 찾아 호출하는 기능을 책임으로 작성하였다.
•
EventListener에서 호출
@PostUpdate
public void onPostPersist(Object object) {
log.info("onPostPersist {}", object.toString());
if (object instanceof Cabinet) {
Cabinet cabinet = (Cabinet) object;
cqrsManager.synchronizeCabinet(cabinet);
}
...
}
Java
복사
EventListener는 업데이트 콜백 호출 시 어떤 엔티티의 콜백이 호출되었는 지 구분하고, 그에 맞춰 동기화 기능을 수행하도록 작성하였다.
성능 비교
조회 로직 비교
•
조회 모델 적용 전
public AvailableCabinetResponseDto getPendingCabinet(String building) {
final LocalDateTime now = LocalDateTime.now();
final LocalDateTime yesterday = now.minusDays(1).withHour(13).withMinute(0).withSecond(0);
List<Cabinet> pendingCabinets =
cabinetQueryService.findPendingCabinetsNotLentTypeAndStatus(
building, LentType.CLUB, List.of(AVAILABLE, PENDING));
List<Long> cabinetIds = pendingCabinets.stream()
.filter(cabinet -> cabinet.isStatus(PENDING))
.map(Cabinet::getId).collect(Collectors.toList());
Map<Long, List<LentHistory>> lentHistoriesMap;
if (now.getHour() < 13) {
lentHistoriesMap = lentQueryService.findPendingLentHistoriesOnDate(
yesterday.toLocalDate(), cabinetIds)
.stream().collect(groupingBy(LentHistory::getCabinetId));
} else {
lentHistoriesMap = lentQueryService.findCabinetLentHistories(cabinetIds)
.stream().collect(groupingBy(LentHistory::getCabinetId));
}
Map<Integer, List<CabinetPreviewDto>> cabinetFloorMap =
cabinetQueryService.findAllFloorsByBuilding(building).stream()
.collect(toMap(key -> key, value -> new ArrayList<>()));
pendingCabinets.forEach(cabinet -> {
Integer floor = cabinet.getCabinetPlace().getLocation().getFloor();
if (cabinet.isStatus(AVAILABLE)) {
cabinetFloorMap.get(floor).add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, null));
}
if (cabinet.isStatus(PENDING)) {
lentHistoriesMap.get(cabinet.getId()).stream()
.map(LentHistory::getEndedAt)
.max(LocalDateTime::compareTo)
.ifPresent(latestEndedAt -> cabinetFloorMap.get(floor)
.add(cabinetMapper.toCabinetPreviewDto(cabinet, 0, null)));
}
});
return cabinetMapper.toCabinetPendingResponseDto(cabinetFloorMap);
}
Java
복사
•
조회 모델 적용 후
public AvailableCabinetResponseDto getPendingCabinet(String building) {
return cqrsService.getAvailableCabinet(building);
}
Java
복사
Redis에서 조회 후 objectMapper로 변환만 수행하여 반환하기 때문에, 확실하게 로직이 단순해졌다.
Redis 메모리 사용량
•
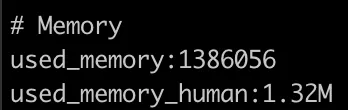
데이터 추가 전
•
데이터 추가 후
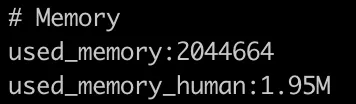
Admin 측을 제외한 Cabinet과 LentHistory 쪽 데이터만 추가했을 때, 대략 6.3MB 정도를 사용하였다.
조회 속도 비교
조금 더 동일한 조건에서 비교하기 위해 전과 후 모두 로컬환경에서 테스트하였다.
•
조회 모델 적용 전



100회씩 평균을 구하여 총 300회 테스트 하였고, 각각 17ms / 25ms / 17ms로 300회 총 평균 19ms정도 소요된다.
•
조회 모델 적용 후



마찬가지로 100회씩 평균을 구하여 총 300회 테스트 하였고, 각각 14ms / 16ms / 12ms로 300회 총 평균 14ms정도 소요된다.
결과만 놓고 비교해보자면 속도가 조금 빨라졌고, dev나 main 환경에서는 데이터베이스가 RDS에 올라가 있어 추가적인 네트워크 비용이 발생할 것이라 조금 더 차이가 날 것으로 예상된다.
명령 속도 비교
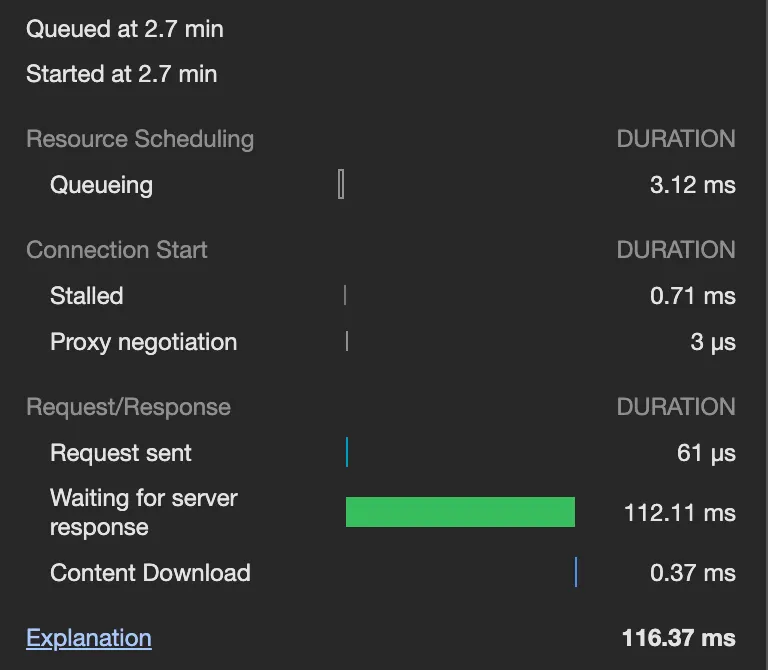
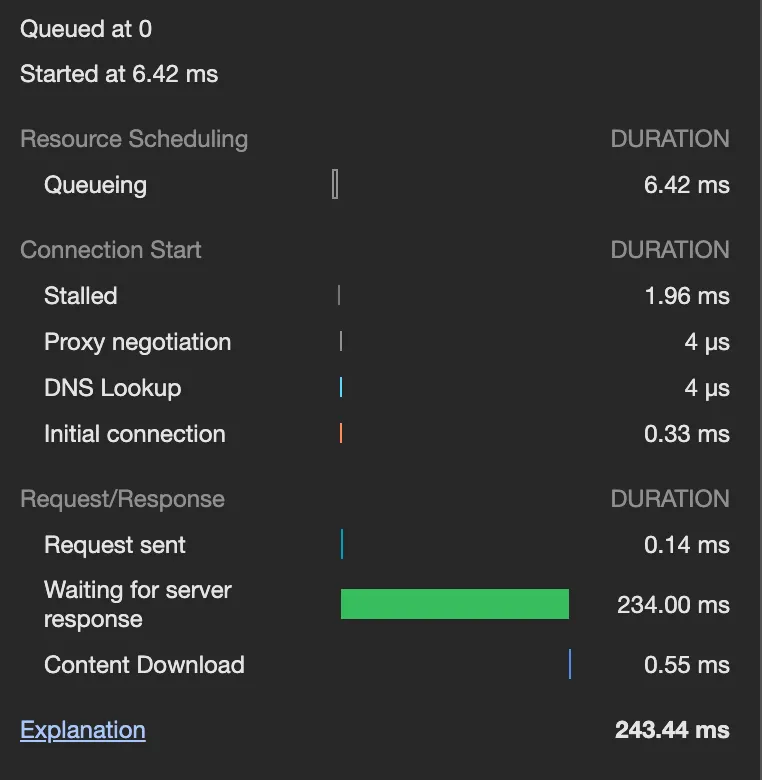
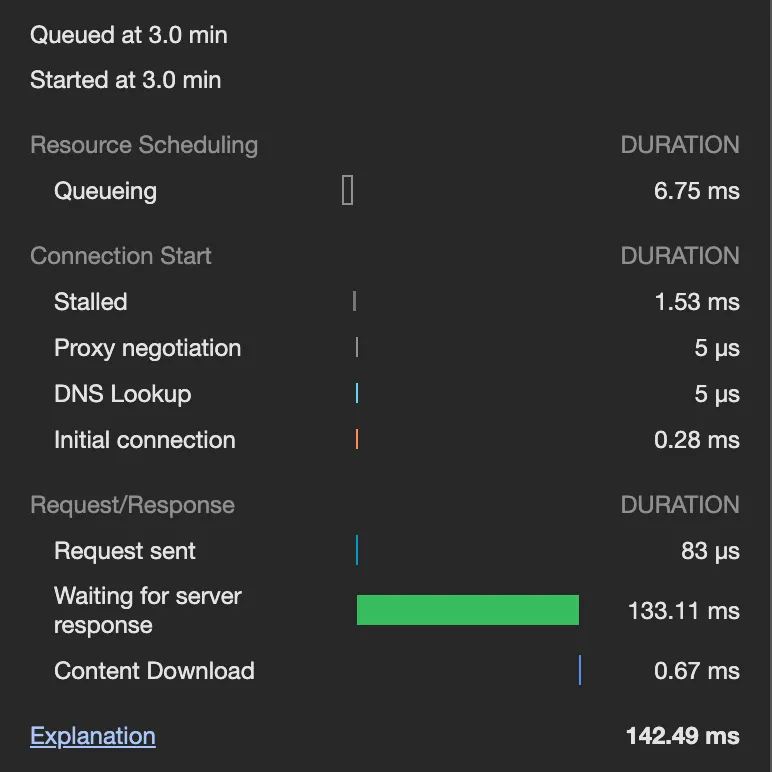
•
조회 모델 적용 전
◦
대여
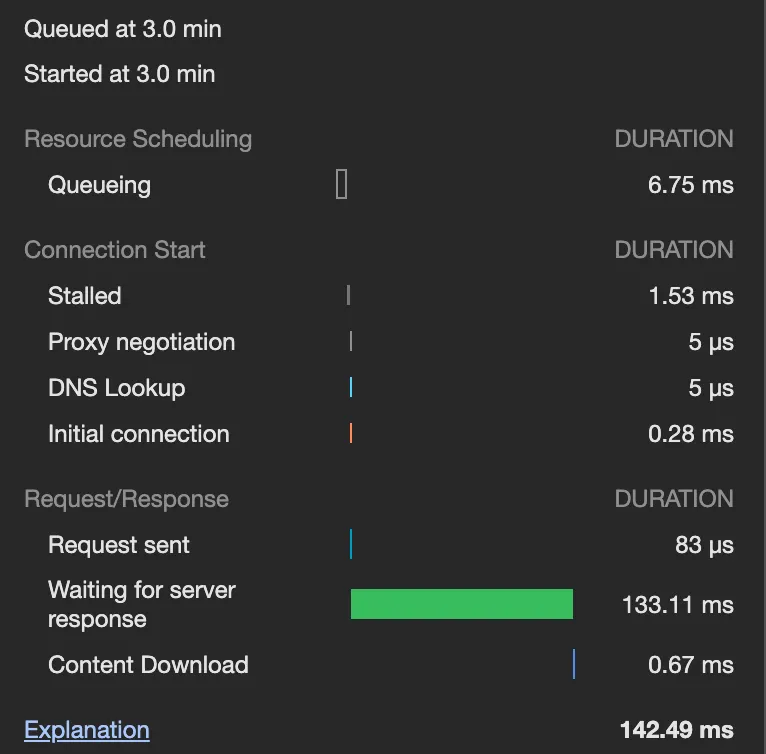
◦
반납
•
조회 모델 적용 후
◦
대여
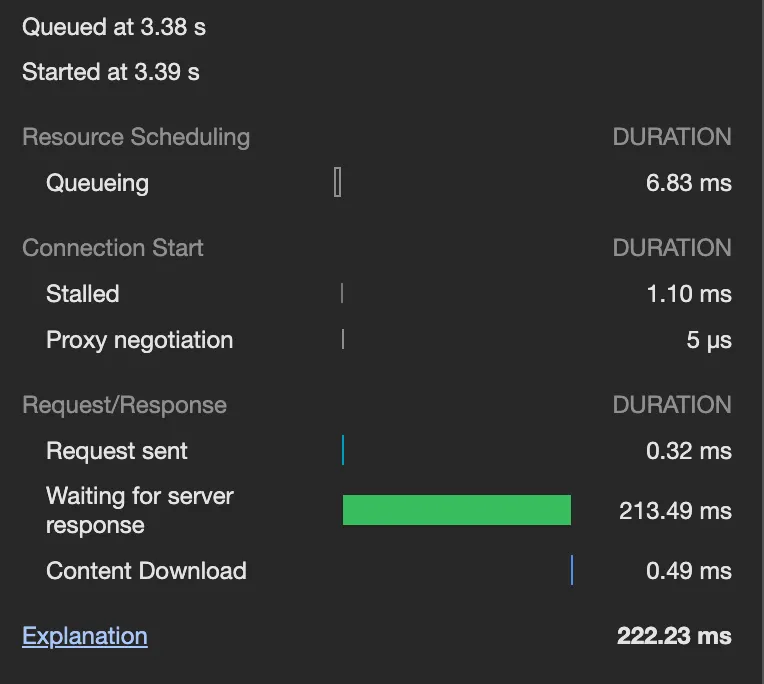
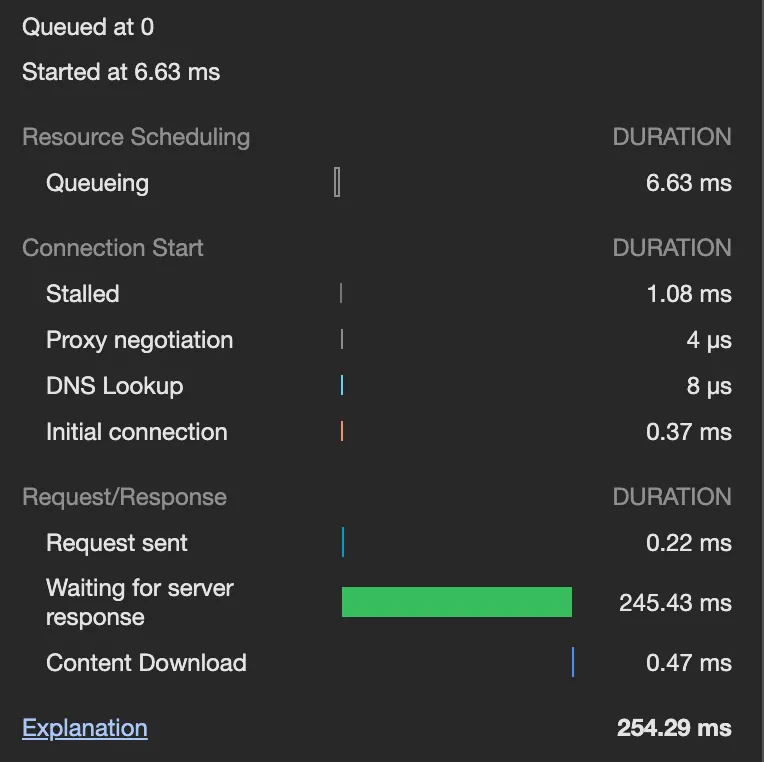
◦
반납
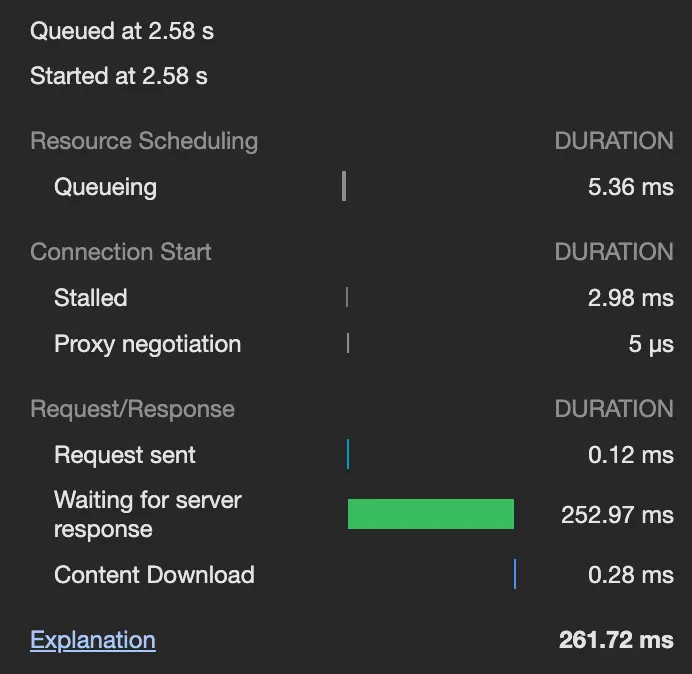
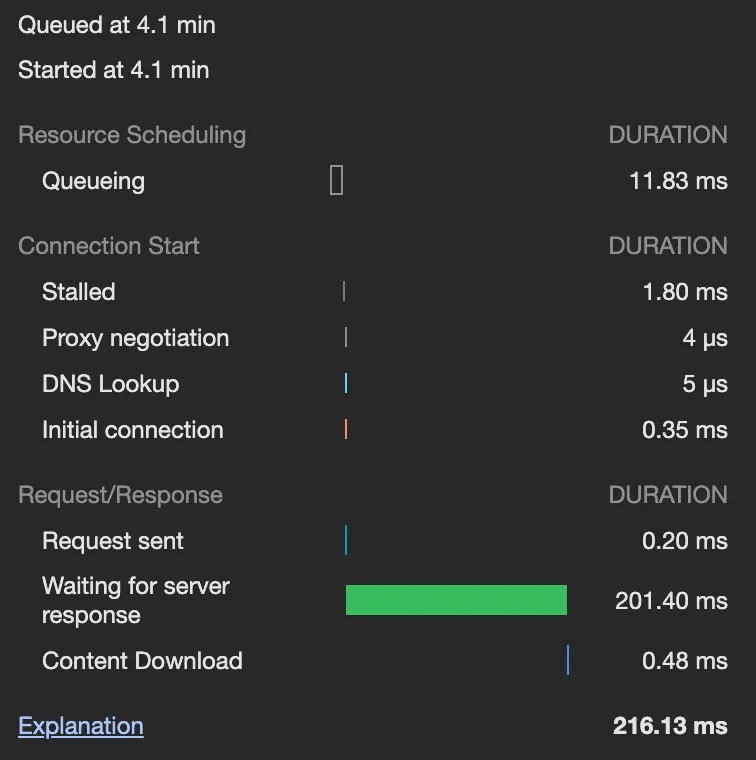
CQRS 적용 전에는 대여, 반납은 150~200ms 정도 소요되지만, CQRS 적용 후에는 200~250ms 정도 소요된다. 소요 시간이 어느 정도 늘어났는데, 이는 PendingCabinet 로직 하나에만 적용된 것임을 감안하면 앞으로도 계속 추가 시간이 소요될 것으로 보인다.
문제점 및 개선
명령 모델 성능
하나의 명령 모델만 테스트 해보았지만, 대략 50ms라는 유의미한 시간 증가가 있었다. 지금은 큰 차이를 못 느끼지만, 이는 이후에 다른 조회 모델의 추가로 인해 명령 하나당 수행해야하는 추가적인 로직이 증가하여 점점 증가할 것으로 예상된다. 이를 개선하지 않으면 사용자 편의 측면에서 불편함을 느낄만큼 시간이 늘어날수도 있고, 추후 CQRS 패턴을 적용하기에는 단점이 너무 커지기 때문에 이를 반드시 개선해야한다는 생각이 들었다.
비동기 처리 적용
이러한 결과를 두고 CQRS에 대해 조금 더 고민을 해본 결과, 핵심은 비동기 처리에 있을 것 같아서 @Async 애노테이션을 통해 비동기 적용을 해보았다.
@PostPersist
@PostUpdate
public void onPostUpdate(Object object) {
if (object instanceof LentHistory) {
LentHistory lentHistory = (LentHistory) object;
cqrsManager.changeCabinetLentHistory(lentHistory);
} else if (object instanceof Cabinet) {
cqrsManager.changeCabinet((Cabinet) object);
}
}
Java
복사
이와 같이 JPA EventListener가 호출되면,
@Async
@Transactional(readOnly = true)
public void changeCabinet(Cabinet cabinet) {
// 영속화(연관관계를 가지는 엔티티 포함)
Cabinet findCabinet = cabinetQueryService.getCabinet(cabinet.getId());
this.changeAvailableCabinet(findCabinet);
this.changeCabinetPerSection(findCabinet);
this.changeCabinetInfo(findCabinet);
this.changeUserLentInfo(cabinet);
}
@Async
@Transactional(readOnly = true)
public void changeCabinetLentHistory(LentHistory lentHistory) {
// LentHistory PostPersist 경우 DB에서 찾으면 없기 때문에 비영속 상태 유지 + 연관관계를 가지는 엔티티 영속화
Cabinet cabinet = cabinetQueryService.getCabinet(lentHistory.getCabinetId());
User user = userQueryService.getUser(lentHistory.getUserId());
this.changeCabinetPerSection(lentHistory, cabinet, user);
this.changeCabinetInfo(lentHistory);
this.changeUserLentInfo(cabinet, lentHistory);
}
Java
복사
비동기로 Cabinet과 LentHistory의 데이터 동기화 작업을 수행한다.

출력 로그를 보면, http-nio-2424-exec-10 스레드와 task-2 스레드로 별도의 작업에서 수행되는 것을 볼 수 있다.
추가적으로 별도의 설정이 없다면 매번 스레드를 새로 생성해서 사용하느라 오버헤드가 발생하기 때문에, 스레드 풀에 관련된 설정을 추가했다.
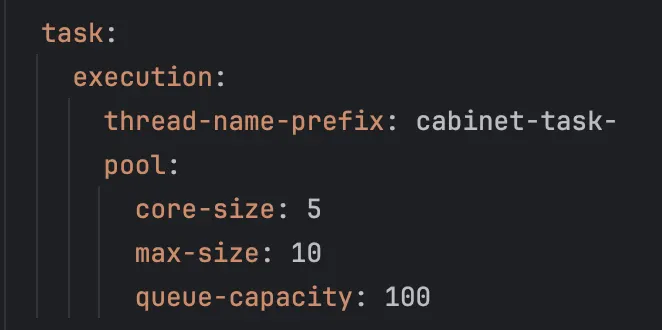
이와 같이 코어 스레드 수 5개, 최대 스레드 수 10개, 요청이 많을 시 최대 100개의 요청까지 Queue에 넣어서 대기하도록 설정했다.

이와 같이 설정한 prefix로 스레드 풀에 스레드를 생성하여 저장해두고 사용한다.
명령 비동기 처리 후 성능 비교
•
대여
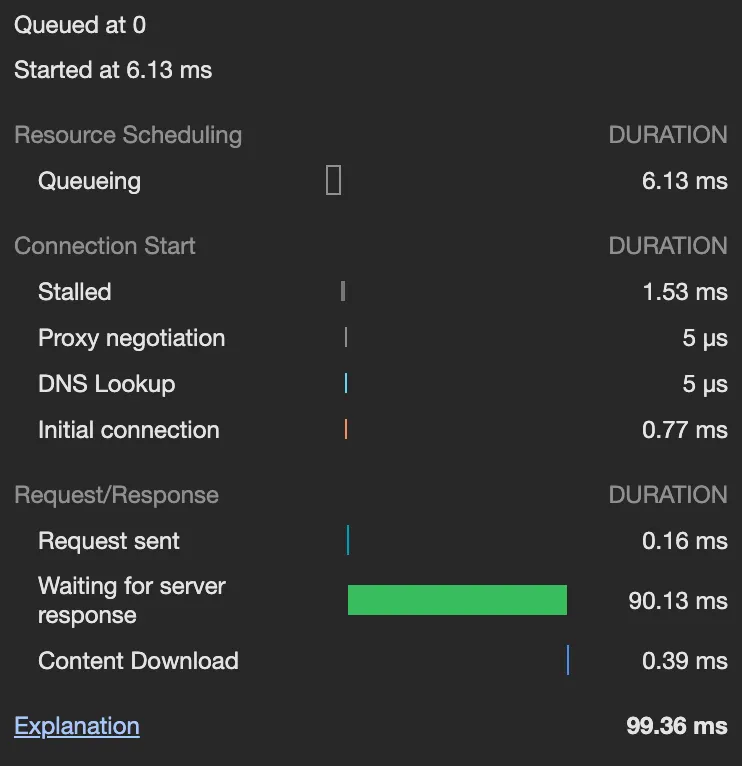
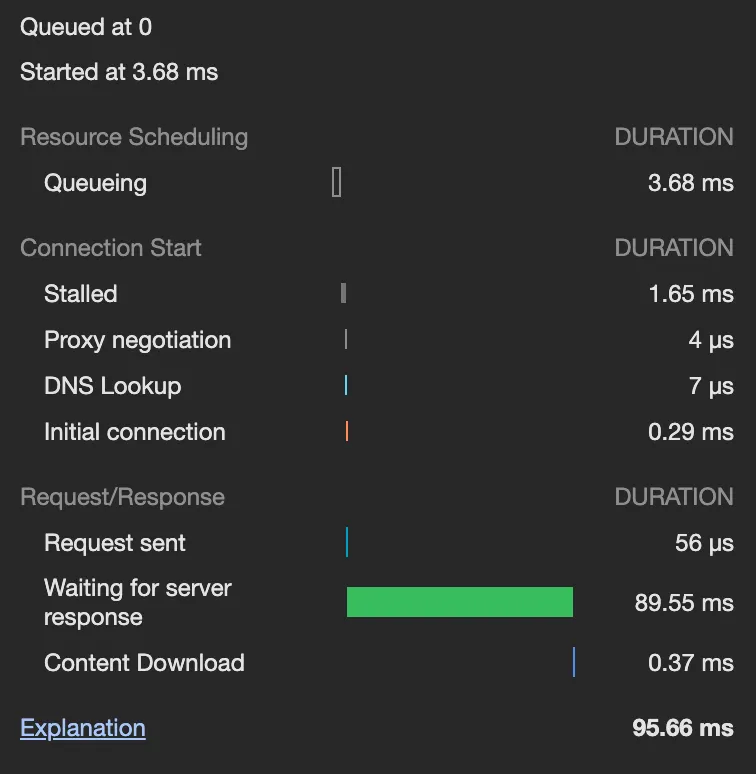
•
반납
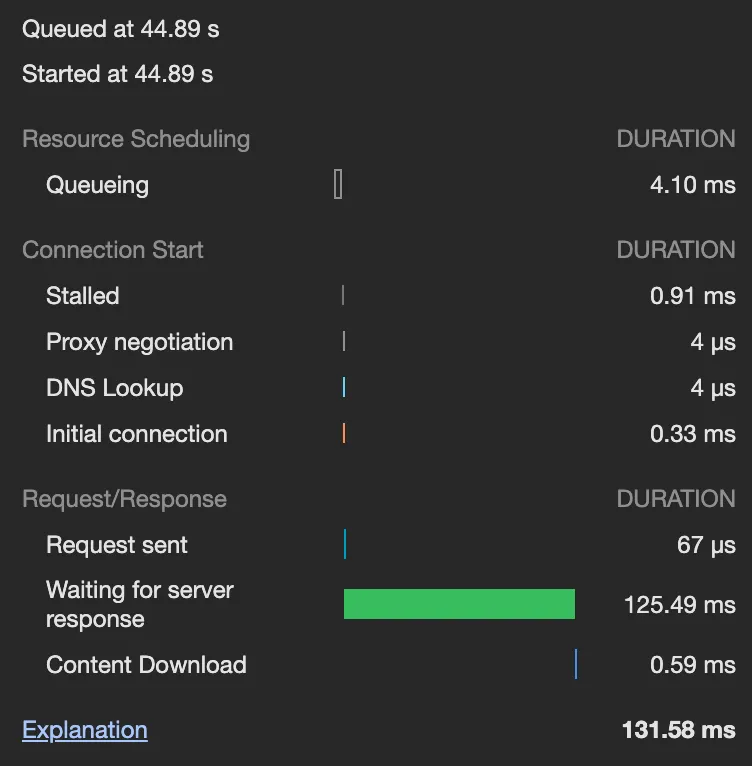
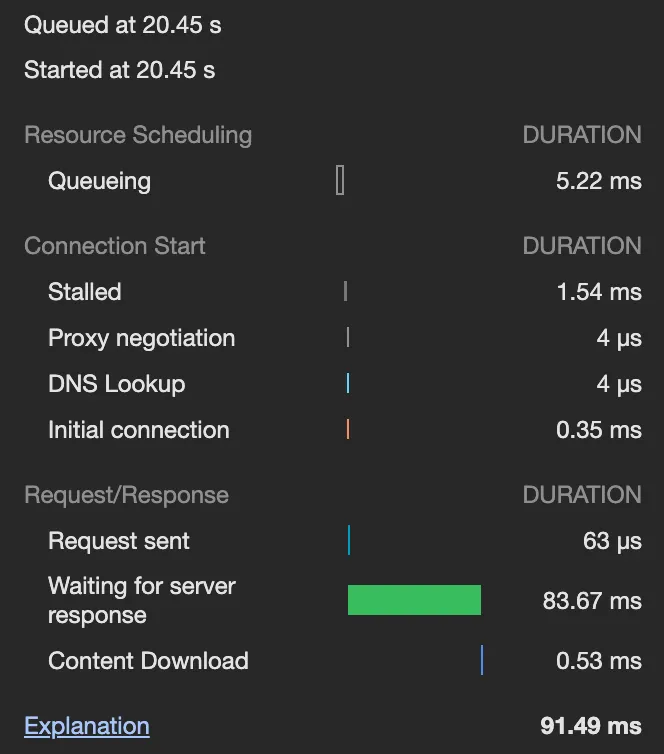
대여와 반납 모두 90~130ms로 조회 전보다 오히려 더 빨라졌다.
CQRS를 구현하며 느낀 점 및 결론
일단 PendingCabinet을 만들 때 구조 설계한다고 고생을 많이 했는데, 다 만들고 나니 이후의 작업이 생각보다 쉽게 구현이 되어서 결국 Cabinet과 관련된 조회 쪽은 전부 CQRS를 구현하였다.
이 정도 만들고 나서 CQRS를 적용 이후 좋아진 점들을 되돌아보자면,
•
그 동안 PendingCabinet이나 CabinetPerSection의 조회 로직이 무척 복잡해서 로직 읽는 시간부터 오래 걸렸었는데, CQRS 적용 이후 해당 조회 로직들이 매우 간단해졌다.
•
조회 속도가 개선 되었다. 위 테스트 결과에서는 4~6ms 정도의 미미한 개선이 이루어졌지만, 실제 RDS에 DB가 올라가있는데 dev나 production 환경을 생각해보면 나름 유의미한 개선일 수 있다. 또한 이번 정책 변경으로 대여와 반납이 이전보다 확연하게 줄고, 빈 사물함이 있는지 확인하는 사용자가 많아져 조회가 더 자주 발생하는 점을 생각하면 충분히 의미가 있는 리팩토링이라고 생각한다.
반대로 오히려 안 좋아진 점들은,
•
데이터베이스 동기화 작업이 오래 걸린다. 일단 CQRS 패턴을 구현하기에 앞서 데이터베이스의 데이터를 조회용 데이터로 가공하여 Redis에 저장하는 작업을 구현했었다. 현재 사물함이 398개가 있는데, 각 사물함마다 Cabinet + LentHistory + User를 Join하여 불러오기 때문에 총 398+@개의 쿼리가 발생한다. 전체 동기화 작업도 비동기로 실행하긴 하지만, 동기화 작업이 수행되는 약 1분 간의 발생하는 쿼리와 사용되는 메모리를 생각하면 동기화 스케줄링을 신중하게 선택해야 할 것 같다.
•
명령 로직 작성이 어려워졌다. 비즈니스 로직 작성 + 명령 처리에 따른 동기화 로직 작성으로 구현해야하는 로직이 늘었고, JPA EventListener에서 전달 받는 엔티티가 한 개씩 받기 때문에 이를 고려하여 동기화 로직을 작성할 때 많은 고민이 필요해졌다. 추가적으로 스케줄링이나 DB에 저장하지 않고 임시로 보관하는 공유 사물함 세션 정보와 같이, 예상치 못한 부분에서 오류가 발생하기도 해서 확실히 구현하는데 드는 품이 많이 늘었다.
•
가끔 리랜더링이 안되는 문제 발생한다. 이는 비동기로 인해 발생하는 문제인데, Cabi는 명령 요청 이후 응답이 오면 프론트에서 리랜더링을 위해 해당 사물함이나 층 정보에 대한 조회 요청을 다시 수행한다. 응답이 먼저 끝나고 비동기로 수행되는 조회 DB 동기화 작업이 늦게 끝나는 상황이 가끔 발생하는데, 조회 DB 동기화가 되기 전에 조회를 수행하여 리랜더링이 정상적으로 수행되지 못한다.
리랜더링 문제는 프론트에서 딜레이를 약간 주거나 정보를 못 받아오면 새로 요청하면 되지만, 이렇게 되면 비동기를 적용하여 얻은 명령 로직 처리 시간 단축의 이점을 잃어버리는 느낌이라 조금 아쉽긴하다. 하지만 애초에 기대하지 않았던 부분의 성능 개선이니, 프론트 분들과 이야기를 나누어보고 개선하려 한다.
추가적으로 현재는 Cabinet에 관련된 쪽만 CQRS 패턴을 적용해두었는데, User와 Club에 관련된 조회도 몇 개 없긴 하지만 남아있는 상황이다. User 쪽 데이터는 자주 불리는 요청이긴 하지만, Cabinet과 달리 현재 잠재적 이용 가능한 사용자를 포함하여 930명 정도로 이를 추가하기 위해서는 동기화 작업 시 930+@의 쿼리가 추가적으로 발생한다. 이러한 상황이라 일단 보류해두었고, 같이 작업하시는 분들과 충분히 이야기를 나누어보고 현재 상태로 적용하거나 추가적으로 구현하거나 적용하지 않겠다는 결정을 내려야 할 것 같다.
개인적인 의견으로는 이러한 단점들을 충분히 감수하고 쓸 만하다고 생각하지만, Cabi의 새로 오신 분들이 과연 어려운 동기화 로직을 이해하고 직접 작성할 수 있을까에 대한 의문이 들기도 한다.
사실 CQRS 패턴을 직접 구현하면서 로직을 서로 의존하지 않게 관심사를 잘 분리할 수 있을까 고민도 정말 많이하고, 그 동안 작성해보지 않았던 코딩 스타일이여서 구현도 꽤나 힘들었다. 직접 엔티티 별로 관심사를 분리하고 동기화 로직을 구현해보니, MSA와 DDD가 어려운 패턴임에도 애플리케이션이 커지면 왜 도입을 고려해보아야 하는지 대충 알 것 같았다.















