



26강 갱신은 효율적으로
•
SQL 의 Q == 질의 Query ⇒ 정보검색이 주요목적
•
UPDATE, DELETE 등 갱신과 관련된 SQL 구문은 비효율적이고 성능이 안좋은 방향으로 작성된다.
•
갱신을 효율적으로 하는 방법을 알아보자
1. NULL 채우기

•
같은 keycol 값이
•
자신보다 작은 seq
•
val 이 NULL 이 아닌 값을 찾아서,
⇒ val 이 null 인 값에 넣는다.

2. 반대로 NULL 작성
•
스칼라 서브쿼리 ⇒ SELECT 절에 포함된 서브쿼리 : 결과는 반드시 하나
27강 레코드에서 필드로의 갱신
Settings
•
ScoreRows 의 항목들을 ScoreCols 에 채워넣기
1. 필드를 하나씩 갱신
UPDATE ScoreCols
SET score_en = (SELECT score
FROM ScoreRows SR
WHERE SR.student_id=ScoreCols.student_id
AND subject='영어')
score_nl = (SELECT score
FROM ScoreRows SR
WHERE SR.student_id=ScoreCols.student_id
AND subject='국어')
score_mt = (SELECT score
FROM ScoreRows SR
WHERE SR.student_id=ScoreCols.student_id
AND subject='수학')
SQL
복사
•
서브쿼리가 3번 실행
•
갱신할 과목이 늘어나면 그만큼 서브쿼리도 증가 → 성능 악화

오라클
⇒ 해결법 - 다중 필드 할당
2. 다중 필드 할당 Multiple Fields Assignment
•
여러 개의 필드를 리스트화 하고 한번에 갱신
UPDATE ScoreCols
SET(score_en, score_nl, score_mt) -- 여러 개의 필드를 리스트화 해서 한꺼번에 갱신
= (SELECT MAX(CASE WHEN subject = '영어'
THEN score
ELSE NULL AND ) AS score_en,
MAX(CASE WHEN subject = '국어'
THEN score
ELSE NULL AND ) AS score_nl,
MAX(CASE WHEN subject = '수학'
THEN score
ELSE NULL AND ) AS score_mt
FROM ScoreRows SR
WHERE SR.student_id = ScoreCols.student_id);
SQL
복사
•
Oracle, DB2 만 사용가능
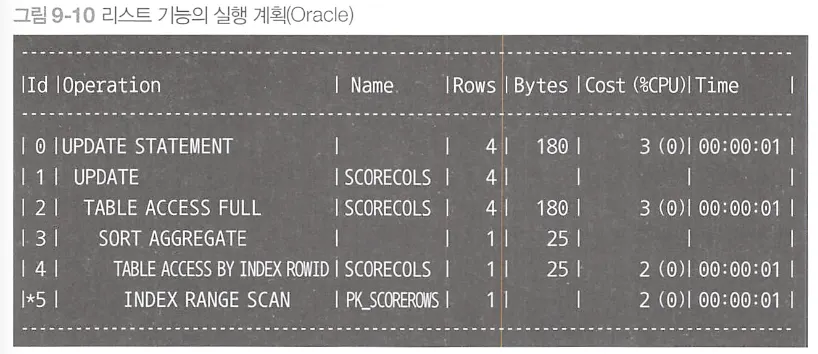
•
성능 관점 ⇒ 상관 서브쿼리가 하나로 정리된 대신, ScoreRows 테이블 접근은 유일 검색 (INDEX UNIQUE SCAN)이 아닌 범위 검색(INDEX RANGE SCAN) 변화, MAX 함수의 정렬 추가 되는 트레이드 오프
•
과목이 많지 않으므로 서브쿼리를 줄이는게 더 이득
•
MySQL 에서는 SET 구에 리스트를 넣는 기능이 지원하지 않는다
(하지만 다중 필드 할당은 표준 SQL 기능)
•
스칼라 서브쿼리
◦
서브쿼리 내부를 보면 CASE 식으로 과목별 점수를 검색 ⇒ 각각의 점수에 MAX 함수를 적용 ⇒ 집약하지 않으면 서브쿼리로 여러개의 레코드가 리턴되기때문에 집약
3. NOT NULL 제약이 걸려있는 경우
•
빈 곳에 0 이 들어가게 된다.
•
UPDATE 구문 사용
◦
제약 상태에서는 앞에서 사용한 NULL 관련 코드 사용 불가
UPDATE ScoreCols
SET score_en = COALESCE((SELECT score_en -- 학생은 있지만, 과목이 없을 때의 NULL 대응
FROM ScoreRows
WHERE student_id = ScoreCols.student_id AND subject = '영어'), 0),
SET score_nl = COALESCE((SELECT score_en -- 학생은 있지만, 과목이 없을 때의 NULL 대응
FROM ScoreRows
WHERE student_id = ScoreCols.student_id AND subject = '국어'), 0),
SET score_mt = COALESCE((SELECT score_en -- 학생은 있지만, 과목이 없을 때의 NULL 대응
FROM ScoreRows
WHERE student_id = ScoreCols.student_id AND subject = '수학'), 0)
-- 처음부터 학생이 존재하지 않는 때의 NULL 대응
WHERE EXISTS(SELECT * FROM ScoreRows WHERE ScoreRows.student_id = ScoreCols.student_id);
SQL
복사
◦
COALESCE : NULL 인걸 제외한 값중 제일 먼저나온 값을 반환
•
MERGE 구문 사용
MERGE INTO ScoreCols
USING (SELECT student_id,
COALESCE(MAX(CASE WHEN subject = '영어' THEN score ELSE NULL END), 0) AS score_en,
COALESCE(MAX(CASE WHEN subject = '국어' THEN score ELSE NULL END), 0) AS score_nl,
COALESCE(MAX(CASE WHEN subject = '수학' THEN score ELSE NULL END), 0) AS score_mt
FROM ScoreRows
GROUP BY student_id) SR
ON (ScoreCols.student_id = SR.student_id)
WHEN MATCHED THEN
UPDATE SET ScoreCols.score_en=SR.score_en,
... 생략
SQL
복사
◦
Oracle, DB2만 사용 가능
•
성능상 ScoreRows의 테이블에 풀스캔 1회 + 정렬 1회 사용
갱신할 필드가 많아져도 변하지 않음
28강 필드에서 레코드로 변경
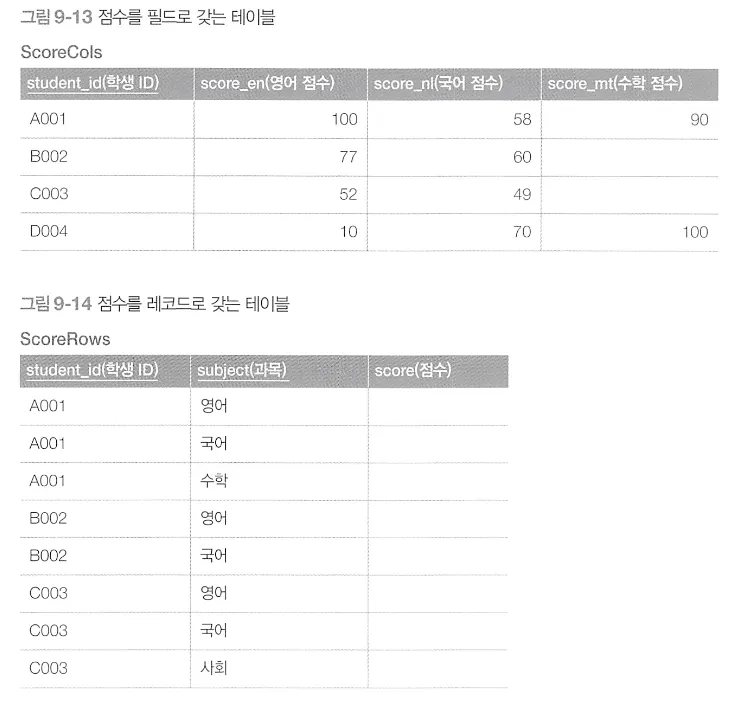
•
필드 기반 테이블의 정보를 레코드 기반 테이블로 갱신
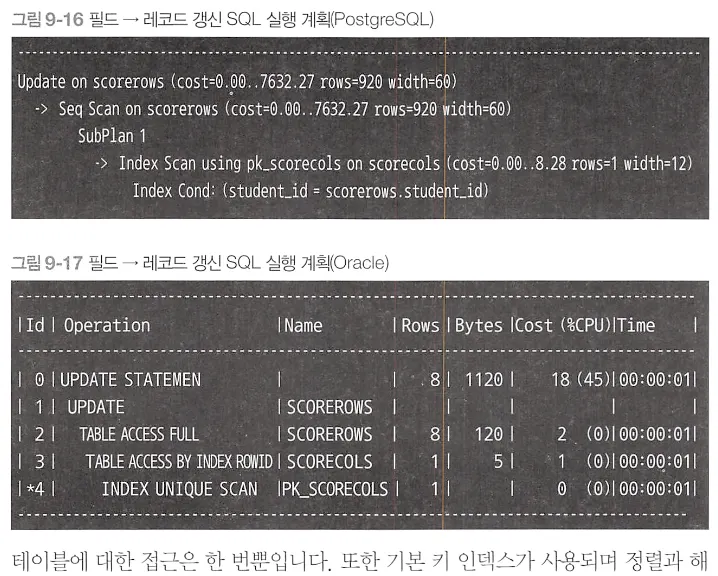
UPDATE ScoreRows
SET score = (SELECT CASE ScoreRows.subject
WHEN '영어' THEN score_en
WHEN '국어' THEN score_nl
WHEN '수학' THEN score_mt
ELSE NULL
END
FROM ScoreCols
WHERE ScoreCols.student_id = ScoreRows.student_id);
SQL
복사
•
테이블에 대한 접근 한번뿐
29강 같은 테이블의 다른 레코드로 갱신
settings
기존에 있었던 테이블에서 컬럼이 추가된 상황
1. 상관 서브쿼리 사용
•
trend 값을 어떻게 넣느냐가 관건
INSERT INTO Stocks2
SELECT brand, sale_date, price,
CASE SIGN(price -
(SELECT price
FROM Stocks S1
WHERE brand = Stocks.brand
AND sale_date =
(SELECT MAX(sale_date)
FROM Stocks S2
WHERE brand = Stocks.brand
AND SALE_date < Stocks.sale_date)))
WHEN -1 THEN 'd'
WHEN 0 THEN 'N'
WHEN 1 THEN 'u'
ELSE NULL
END
FROM Stocks;
SQL
복사
•
SIGN 함수 : 매개변수로 받은 숫자가 양수면 1, 음수면 -1, 0은 0
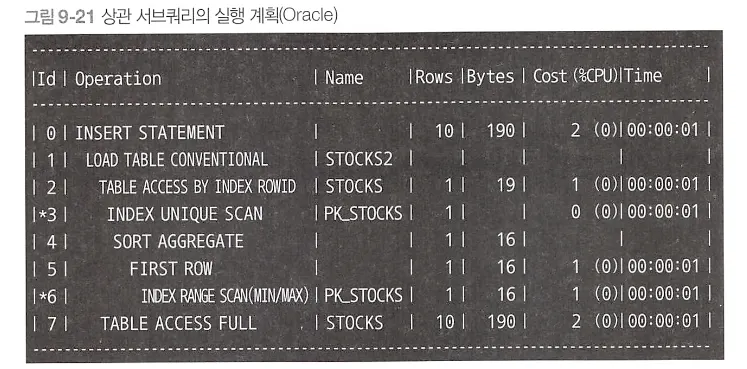
•
Stocks 테이블에 수차례 접근 ( 서브쿼리)
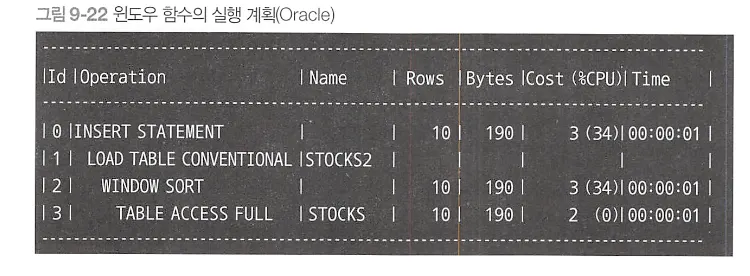
2. 윈도우 함수 사용
INSERT INTO Stocks2
SELECT brand, sale_date, price,
CASE SIGN(price
- MAX(price) OVER(PARTITION BY brand
ORDER BY sale_date
ROWS BETWEEN 1 PRECEDING
AND 1 PRECEDING))
WHEN -1 THEN 'd'
WHEN 0 THEN 'N'
WHEN 1 THEN 'u'
ELSE NULL
END
FROM Stocks s2;
SQL
복사
•
PRECEDING : 기준 행 이전 행들을 가리키는데 사용되는 키워드
•
이전 1개와 비교?
3. INSERT 와 UPDATE 비교
•
INSERT SELECT
◦
장점
◦
UPDATE에 비해 INSERT SELECT가 성능적으로 낫다 ⇒ 고속 처리를 기대할 수 있다
◦
Mysql 처럼 갱신 SQL에서 자기참조가 안되는 경우에 사용 ( 참조 대상 테이블과 갱신 대상 테이블이 서로 다른 테이블)
◦
단점
◦
크기와 구조를 가진 데이터를 두개 만들어야 한다
⇒ 저장소 용량을 2배 이상 소비
30강 갱신이 초래하는 트레이드 오프
•
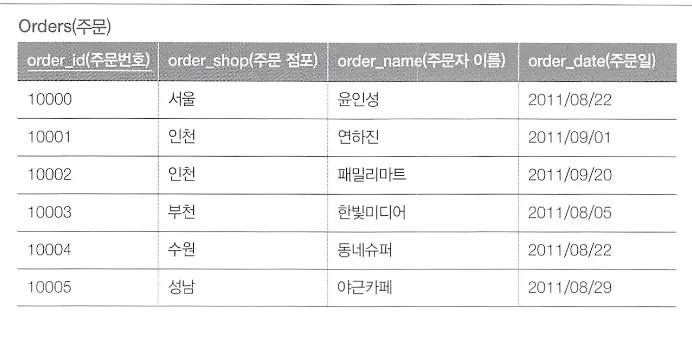
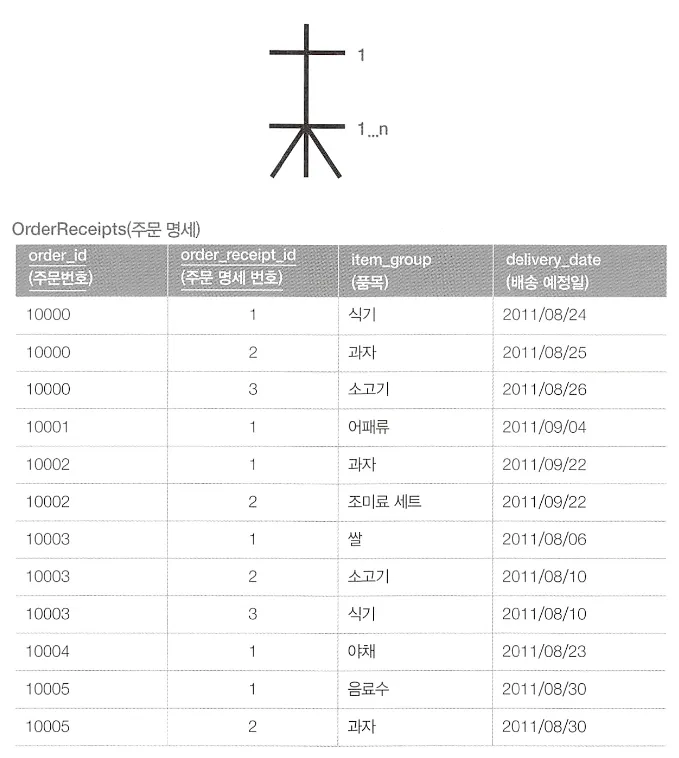
주문과, 주문 명세 테이블
•
주문 명세 테이블에서 배송예정일과, 주문테이블에서의 주문일과 차이가 3일 이상인 레코드를 찾기
SELECT O.order_id,
MAX(O.order_name),
MAX(ORC.delivery_date - O.order_date) AS max_diff_days
FROM Orders O
INNER JOIN OrderREceipts ORC
ON O.order_id = ORC.order_id
WHERE ORC.delivery_date - O.order_date >=3
GROUP BY O.order_id;
SQL
복사
•
order_name 에 MAX를 쓴 이유
order_name 필드는 상수도 아니고 GROUP BY 구에서도 사용하지 않는다. 따라서 그대로 SELECT에 쓰면 에러
이를 방지하고자 집약 함수의 형태로 넣은것( MAX / MIN )
MAX/MIN 은 모든 데이터 자료형에 사용이 가능하므로 유용
order_id와 order_name 필드가 1:1 대응이라면 GROUP BY 구에 order_name 필드 포함 가능 그러면 MAX 없이 사용가능
2. 모델 갱신
•
ER 모델을 바꿀 수 있다면?
•
이렇게도 할 수 있는 방법도 있다
•
만약 바꿀 수 있다면?
31강 모델 갱신의 주의점
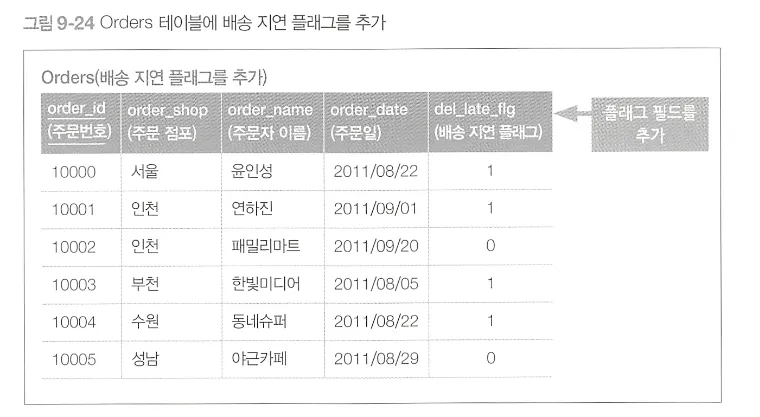
1. 높아지는 갱신 비용
검색 부하를 갱신 부하로 바꾸는 꼴
만약 Orders 테이블에 레코드를 등록할 때 이미 플래그 값이 정해져 있다면 갱신비용은 없다
하지만 개별 상품 배송 예정일ㅇ ㅣ정해져 있지 않을 수 있다. ⇒ 플래그 필드를 UPDATE 하는 비용
2. 갱신까지의 시간 랙Time lag
•
실시간성 문제
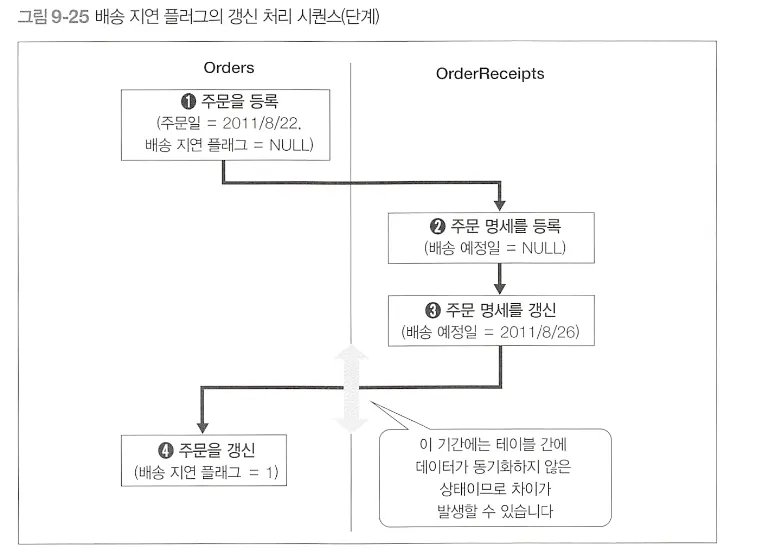
•
배송 예정일이 주문 등록 후에 갱신되는 경우에는 Orders 테이블의 배송 지연 플래그 필드와 OrderReceipts 테이블의 배송 예정일 필드가 실시간으로 동기화되지 않으므로 차이 발생
3. 모델 갱신비용 발생
데이터 모델 갱신은 코드 기반 수정에 비해 대대적인 수정이 필요
32강 시야 협착: 관련문제
•
주문번호
•
주문자 이름
•
주문일
•
상품 수
⇒ 가 포함되어야 한다 결과에
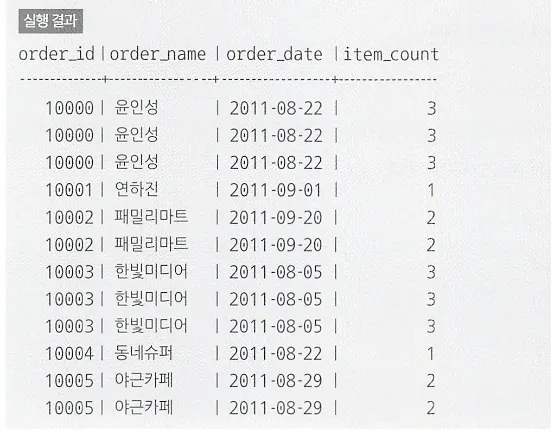
1. SQL을 사용한다면
SELECT O.order_id,
MAX(O.order_name) AS order_name,
MAX(O.order_date) AS order_date,
COUNT(*) AS item_count
FROM Orders O
INNER JOIN OrderReceipts ORC
ON O.order_id = ORC.order_id
GROUP BY O.order_id;
--- 윈도우 함수 사용
SELECT O.order_id,
O.order_name,
O.order_date,
COUNT(*) OVER (PARTITION BY O.order_id) AS item_count
FROM Orders O
INNER JOIN OrderReceipts ORC
ON O.order_id = ORC.order_id;
SQL
복사


2. 모델 갱신을 사용한다면
•
Orders 테이블에 상품 수 라는 정보를 추가해서 모델을 갱신하면?
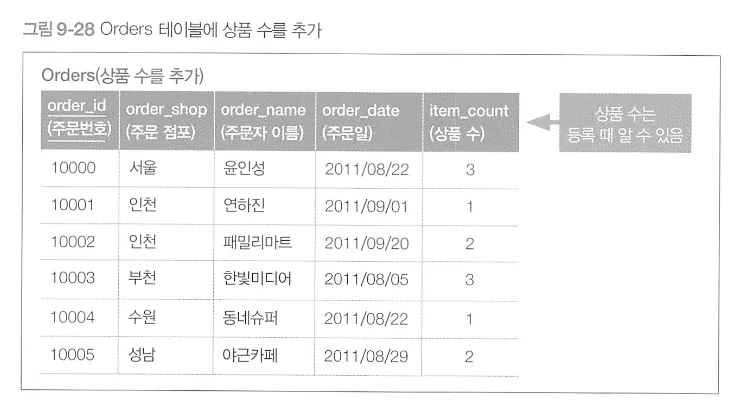
•
상품 수도 바뀔 수 있다 → 동기/비동기 문제 생각
3. 초보자보다 중급자에게 해당되는 문제
우리가 걱정할 단계는 아닌것 같다
33강 데이터 모델을 지배하는 자가 시스템을 지배한다
•
애초에 데이터 모델을 잘 짜놔야 비즈니스 적으로도 해결하기 쉬워질 수 있다
⇒ 하지만 우리가 창업을하거나, 새로운 서비스를 만드는게 아닐경우 바닥부터 짜는일이 잘 없을 것 같다.
•
이러나저러나 테이블 설계할때 잘 해야한다
•
기획 → 데이터모델링 → 데이터설계
•
데이터 모델링에 시간을 많이 쏟는 EU