



34강 - 인덱스와 B-tree
•
RDB에서 사용하는 인덱스는 B-tree 인덱스, 비트맵 인덱스, 해시 인덱스가 있다.
B-tree
데이터를 트리 구조로 저장하는 형태의 인덱스
•
CREATE INDEX 구문을 실행하면 암묵적으로 B-tree 인덱스가 만들어진다.
•
실제 대부분의 데이터베이스(Oracle, PostgreSQL, MySQL)에서는 트리의 리프 노드에만 키 값을 저장하는 B+tree를 사용한다.
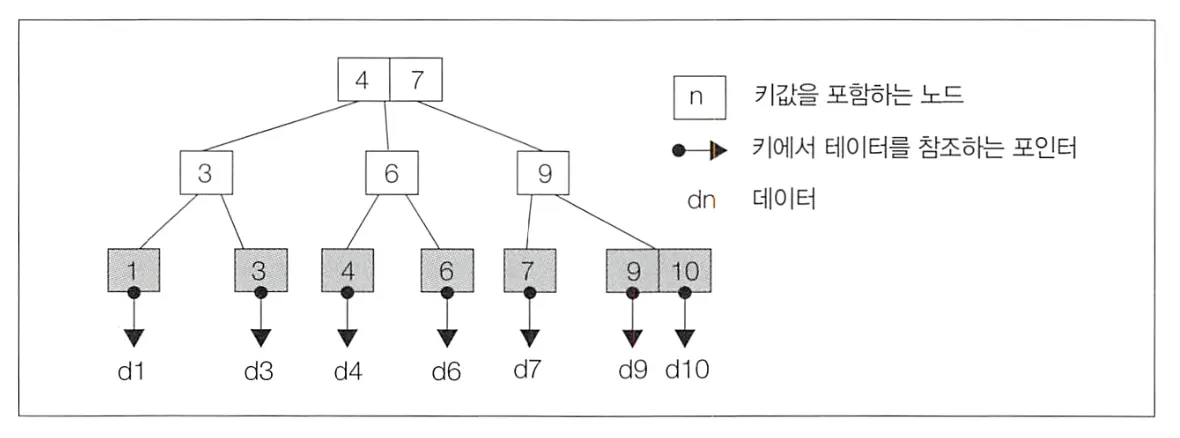
B+tree의 구조. 리프 노드는 링크드 리스트로 저장된다.
•
B+tree의 검색 성능이 뛰어난 이유
◦
루트와 리프의 거리를 가능한 일정하게 유지하려 함 → 균형이 잘 잡혀 검색 성능이 안정적이다.
◦
트리의 깊이가 대부분 3-4 수준으로 일정하며, 데이터가 정렬 상태를 유지함 → 이분 탐색을 통해 검색 비용을 크게 줄일 수 있다.
◦
이미 정렬된 상태이기 때문에 잘 활용하면 집약 함수 등에서 요구되는 정렬을 생략할 수 있다.
비트맵 인덱스
데이터를 비트 플래그로 변환해서 저장하는 형태의 인덱스
•
카디널리티가 낮은 필드의 경우 효과적이다.
•
갱신할 때 오버헤드가 너무 크기 때문에 빈번한 갱신이 일어나지 않는 BI/DWH 용도로 사용된다.
BI/DWH
해시 인덱스
키를 해시 분산해서 등가 검색을 고속으로 실행하고자 만들어진 인덱스
•
등가 검색 외에는 효과가 거의 없고, 범위 검색을 할 수 없음 → 거의 사용되지 않는다.
•
구현하는 DBMS가 거의 없다.
◦
PostgreSQL의 해시 인덱스와 Oracle의 reverse key index가 있지만 둘 다 사용할 일은 거의 없다.
35강 - 인덱스를 잘 활용하려면
B+tree의 장점은 범용성이다. 인덱스를 잘 활용하려면 몇 가지 포인트를 고려해야 한다.
카디널리티와 선택률
카디널리티가 높고, 선택률이 낮으면 인덱스를 생성하는 것이 좋다. 최근 DBMS에서는 대체로 5~10% 이하의 선택률이 기준이다.
•
카디널리티
◦
값의 균형을 나타내는 개념
◦
카디널리티가 가장 높은 필드는 모든 레코드에 다른 값이 들어가있는 유일 키 필드이다.
•
선택률
◦
특정 필드값을 지정했을 때 테이블 전체에서 몇 개의 레코드가 선택되는지를 나타내는 개념
◦
100개의 레코드를 가진 테이블에서 한 개의 레코드만 선택된다면 선택률은 1%이다.
36강 - 인덱스로 성능 향상이 어려운 경우
특정 SQL에 적절한 인덱스를 작성하려면, SQL의 검색 조건과 결합 조건을 바탕으로 데이터를 효율적으로 압축할 수 있는 조건을 찾아야 한다. 이를 위해서는 SQL 구문과 검색 키 필드의 카디널리티를 알아야 한다.
데이터를 압축할 조건이 해당 SQL 구문에 존재하지 않을 경우에 대해 알아보자.
압축 조건이 존재하지 않음
SELECT order_id
FROM Orders;
SQL
복사
레코드를 압축하는 WHERE 구가 없으므로 인덱스를 작성할 만한 필드도 존재하지 않는다. 실무에서도 이런 극단적인 경우는 잘 없다.
레코드를 제대로 압축하지 못하는 경우
SELECT order_id
FROM Orders
WHERE process_flg=5;
SQL
복사
process_flg가 5인 레코드가 전체 레코드의 80%라고 하자. 이 경우 선택률이 80%이므로 process_flg 필드에 인덱스를 만들어서 사용하더라도 풀 스캔보다 느릴 수 있다.
인덱스가 제대로 작동하려면 레코드를 크게 압축할 수 있는 검색 조건이 있어야 한다.
•
입력 매개변수에 따라 선택률이 변동하는 경우
SELECT order_id
FROM Orders
WHERE receive_date BETWEEN :start_date AND :end_date;
SQL
복사
검색 범위가 1일이 될 수도 있지만, 1년이 될 수도 있다. 검색 조건이 매개변수화 되어 있는 SQL은 입력에 따라 선택률이 크게 달라진다.
인덱스를 사용하지 않는 조건
압축할 검색 조건이 있으면서도 인덱스를 사용할 수 없는 경우가 있다.
•
중간 일치, 후방 일치의 LIKE 연산자
WHERE shop_name LIKE '%대공원%';
SQL
복사
LIKE 연산자를 사용하는 경우 인덱스는 전방 일치(대공원%)에만 적용할 수 있다.
•
인덱스 필드로 연산하는 경우
WHERE col_1 * 1.1 > 100; // 인덱스 사용 불가
SQL
복사
검색 조건의 우변에 식을 사용하면 인덱스가 사용된다.
WHERE col_1 > 100 / 1.1;
SQL
복사
•
IS NULL을 사용하는 경우
일반적으로 인덱스 필드의 데이터에 NULL이 존재하지 않기 때문에, IS NULL을 사용하는 경우 인덱스를 사용할 수 없다.
•
부정형을 사용하는 경우
부정형(<>, !=, NOT IN)은 인덱스를 사용할 수 없다.
37강 - 인덱스를 사용할 수 없는 경우 대처법
외부 설정
•
UI 설계로 처리
애플리케이션에서 검색에 제한을 둠으로써 선택률을 낮게 할 수 있다. 점포 ID와 주문일을 반드시 함께 입력해야 검색 버튼을 누를 수 있게 하거나, 기간 검색의 범위에 제한 조건을 둔다면 인덱스를 사용할 수 있다.
성능과 사용성의 트레이드오프가 발생한다.
데이터마트
특정한 쿼리(군)에서 필요한 데이터만을 저장하는, 상대적으로 작은 크기의 테이블. 원래 테이블의 부분 집합(서브셋)이다.
•
접근 대상 테이블의 크기를 작게 해서 I/O 양을 줄이는 것이 데이터 마트의 목적이다.
CREATE TABLE OrderMart
(order_id CHAR(4) NOT NULL,
receive_date DATE NOT NULL);
SQL
복사
SELECT order_id, receive_date
FROM OrderMart;
SQL
복사
•
압축 조건이 존재하지 않는 경우에도 성능이 보장된다.
•
주의점
◦
데이터 신선도
특정한 시점마다 원본 테이블에서 데이터를 동기화해야 한다. 데이터 신선도가 중요한 경우라면 데이터 마트를 사용하기 어렵다.
◦
데이터 마트 크기
원래 테이블에서 크기를 딱히 줄일 수 없다면, 데이터 마트를 만들어도 빨라지지 않는다. 단, GROUP BY 절을 미리 사용해서 집계를 마치고 데이터 마트를 만들면 필드 수와 레코드 수를 크게 줄일 수 있다.
◦
데이터 마트 수
데이터 마트의 수가 늘어나면 그만큼 저장소 용량을 압박하고, 백업 또는 스냅샷을 할 때의 시간이 오래 걸린다.
◦
배치 윈도우
만들어진 데이터 마트는 어느 정도 규모의 갱신이 발생할 때 통계 정보도 다시 수집해야 한다. 이러한 처리를 여유롭게 수행하기 위한 배치 윈도우와 Job Net도 고려해야 한다.
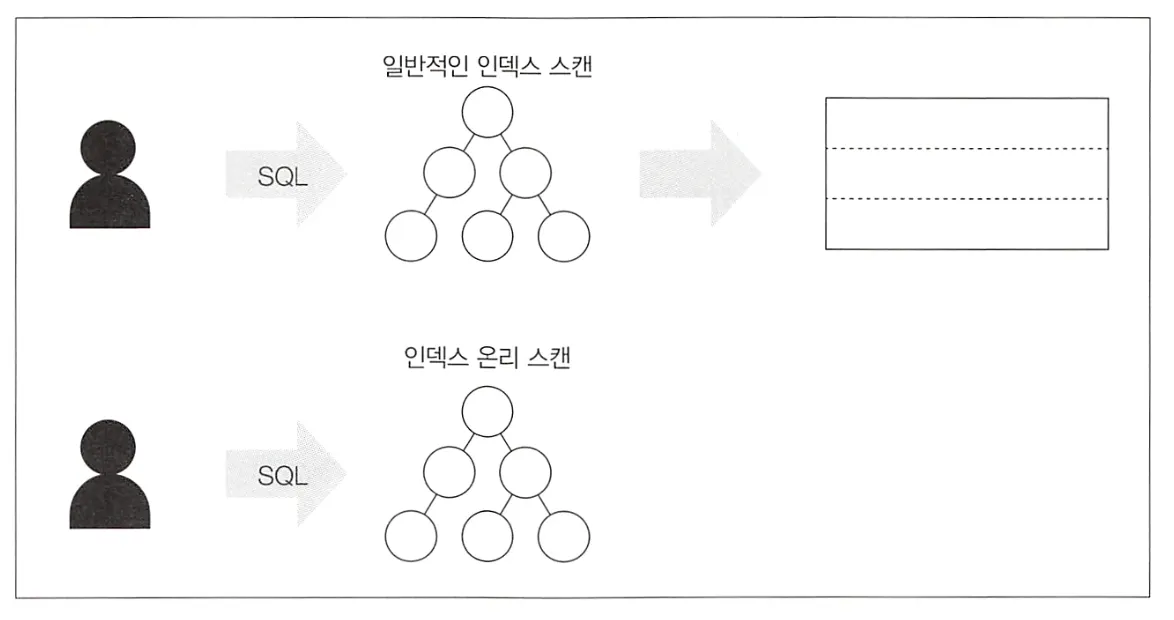
인덱스 온리 스캔
SQL 구문에서 필요한 필드를 인덱스만으로 커버할 수 있는 경우 테이블 접근을 생략하는 기술
CREATE INDEX CoveringIndex ON Orders (order_id, receive_date);
SQL
복사
•
Covering Index: 인덱스의 필드 후보가 아닌 필드를 커버하는 인덱스. 커버링 인덱스를 통해 인덱스 온리 스캔을 사용할 수 있게 된다.
•
장점
◦
I/O 비용을 줄일 수 있다.
◦
테이블 필드의 부분 집합만 저장 → 크기가 작다.
◦
애플리케이션을 수정하지 않는다.
•
로우 지향 데이터베이스에서 컬럼 지향 데이터베이스를 유사하게 실현한다.
•
주의점
◦
DBMS에 따라 사용할 수 없는 경우도 있다.
오래된 버전의 DBMS에서는 지원하지 않는다. 하지만 2015년 8월 기준 최신판에서는 모든 DBMS에서 인덱스 온리 스캔을 지원한다.
◦
한 개의 인덱스에 포함할 수 있는 필드 수에 제한이 있다.
인덱스의 크기는 무제한이 아니며, 포함할 수 있는 필드 수 또는 크기에 제한이 있다.
◦
갱신 오버 헤드가 커진다.
검색을 고속으로 만들 수 있는 대신, 갱신 성능이 떨어지는 트레이드오프가 발생한다.
◦
정기적인 인덱스 리빌드가 필요
인덱스에만 접근한다는 것은 곧, 검색 성능 자체가 인덱스의 크기에 의존한다는 것이다. 따라서 커버링 인덱스의 정기적인 크기 모니터링과 리빌드를 운용에 포함시켜야 한다.
◦
SQL 구문에 새로운 필드가 추가된다면 사용할 수 없다.
일반적인 인덱스에 비해 애플리케이션 유지 보수에 약한 타입의 튜닝이다.