
.gif&collectionId=dcb50d88-6307-4897-975e-13c151621a8a)
자바의 동기화
•
자바는 기본적으로 멀티 스레드 환경을 고려한 프로그래밍 언어로, 자바스크립트와 같은 웬만한 인터프리터 언어보다 성능이 좋다.
•
자바 역시 Thread가 변수에 접근할 때 멀티 스레딩 환경에서 발생하는 경쟁 상태(race condition) 문제가 발생하는데, 주로 synchronized 키워드나 Atomic 타입을 이용해 동기화 처리하여 동시 접근을 막아 경쟁 상태 문제를 해결한다.
•
그 외에도 volatile 키워드를 이용하여 동기화 처리할 수도 있다.
volatile 키워드
•
스레드는 실행되고 있는 CPU 메모리 영역에서 데이터를 캐싱하는데, 멀티 스레딩 환경에서는 같은 변수를 공유하면 캐싱된 시점에 따라 캐시 데이터와 메모리에 저장된 데이터가 다를 수 있다.
•
volatile 키워드는 CPU 메모리 영역에 캐싱된 데이터를 읽어오는 것이 아니라, 항상 메인 메모리 영역에서 값을 참조해 최신의 값을 가져온다.
•
이 때문에 volatile을 사용하면 동일 시점에 모든 스레드가 동일한 값을 가지도록 동기화되고, 이런 동기화를 통신-동기화 혹은 메모리-동기화라고 한다.
volatile을 사용한 동기화의 한계
•
volatile은 말 그대로 캐시 없이 메모리에서 최신의 값을 읽어오게만 할 뿐, 경쟁 상태를 해결해주는 것이 아니다.
•
그렇기 때문에 volatile은 원자적 연산에서만 동기화를 보장한다.
원자적 연산
원자적 연산이란 a = 13 이나 b = a 와 같이 변수에 딱 한 번만 접근하는 것을 의미한다. a = a + 1 의 연산을 수행한다면 a를 읽고 → a에 1을 더하고 → 다시 a에 쓰는 세 번의 접근이 발생하기 때문에, 원자적 연산이 아니다.
public class RunNStopTest {
private static volatile boolean stop = false;
public static void main(String[] args) throws InterruptedException {
for (int i = 0 ; i < 10; i++) {
Thread backgroundThread = new Thread(() -> {
int j = 0;
while (!stop) { //읽기
j++;
}
});
backgroundThread.start();
}
TimeUnit.SECONDS.sleep(5);
stop = true;//쓰기
}
}
Java
복사
•
위 코드는 스레드에서 접근하는 변수(stop)가 원자적 연산으로만 이루어져있기 때문에, stop 변수에 volatile을 붙여준 것만으로도 동기화가 된다.
public class RunNStopTest {
private static volatile int stop = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0 ; i < 10; i++) {
Thread backgroundThread = new Thread(() -> {
while (stop + 1 < 100) { // 읽기 + 더하기
stop++; // 읽기 + 쓰기
}
});
backgroundThread.start();
}
}
}
Java
복사
•
다만 이렇게 원자적 연산이 아닌 경우에는 동기화를 보장할 수 없다.
synchronized 키워드
•
자바의 synchronized는 특정 구간을 임계 영역으로 설정하고 lock을 걸어 여러 스레드에서 해당 임계 구역에 동시에 접근하지 못하게 만드는 것이다.
•
synchronized는 단일 스레드만 진입하도록하는 배타적 실행뿐만 아니라, volatile이 하는 역할인 메인 메모리에서 가장 최근 값을 가져오도록 하는 통신 동기화 기능도 같이 수행한다.
•
synchronized의 사용 방법은 메서드 앞에 synchronized를 붙여 해당 메서드 전체를 임계 구역으로 만드는 방법과, 코드블록을 synchronized로 지정하는 방법이 있다.
◦
메서드 이름 앞에 synchronized 키워드를 붙이면 해당 메서드 전체를 임계영역으로 설정할 수 있다.
synchronized void increase() {
count++;
System.out.println(count);
}
Java
복사
◦
synchronized를 참조변수 객체와 같이 사용하여 코드 블록에 사용하여 해당 블록을 임계 영역으로 설정할 수 있다. 참조변수 객체의 lock을 사용하게 된다.
void increase() {
synchronized(this) {
count++;
}
System.out.println(count);
}
Java
복사
•
임계영역에 lock을 걸어 동기화를 진행하면 해당 임계영역에서는 멀티 스레딩 환경을 사용하지 못하는 것으로, 임계 영역이 넓을수록 효율이 떨어진다. 따라서 메서드 전체를 synchronized로 걸어 사용하기보다는 코드 블록을 사용하는 것이 권장된다.
•
메서드 동기화보다 코드 블록 동기화를 사용해야하는 또다른 이유는, 참조변수를 설정하는 것 때문이다. 코드 블록의 경우에는 this나 다른 객체를 넣어 해당 객체의 lock을 사용할 수 있는데, 메서드 동기화 방식에는 해당 메서드가 포함된 객체의 lock만을 사용한다.
public class MyHero {
private String mHero;
public static void main(String[] agrs) {
MyHero tmain = new MyHero();
System.out.println("Test start!");
new Thread(() -> {
for (int i = 0; i<1000000; i++) {tmain.batman();}
}).start();
new Thread(() -> {
for (int i = 0; i<1000000; i++) {tmain.superman();}
}).start();
System.out.println("Test end!");
}
public synchronized void batman() {
mHero= "batman";
try {
long sleep = (long) (Math.random()*100);
Thread.sleep(sleep);
if ("batman".equals(mHero) == false) {
System.out.println("synchronization broken");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public synchronized void superman() {
mHero = "superman";
try {
long sleep = (long) (Math.random()*100);
Thread.sleep(sleep);
if ("superman".equals(mHero) == false) {
System.out.println("synchronization broken");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Java
복사
•
위 코드를 보면 batman 메서드와 superman 메서드 모두 메서드 동기화 방식을 사용하는데, 둘 다 MyHero 클래스의 tmain 객체 기준으로 lock을 사용하기 때문에 batman 메서드에서 접근 중일 때 superman 메서드에서는 접근할 수 없다.
•
사실 이는 synchronized(this)를 사용한 코드 블록과 동일한데, 코드 블록 동기화에서는 아래처럼 this 대신 다른 객체를 넣어 각기 다른 lock을 걸도록 설정해줄 수 있다.
public class MyHero {
private String mHero;
private final Object lockObject1;
private final Object lockObject2;
public static void main(String[] agrs) {
MyHero tmain = new MyHero();
System.out.println("Test start!");
new Thread(() -> {
for (int i = 0; i<1000000; i++) {tmain.batman();}
}).start();
new Thread(() -> {
for (int i = 0; i<1000000; i++) {tmain.superman();}
}).start();
System.out.println("Test end!");
}
public void batman() {
synchronized(lockObject1) {
mHero= "batman";
try {
long sleep = (long) (Math.random()*100);
Thread.sleep(sleep);
if ("batman".equals(mHero) == false) {
System.out.println("synchronization broken");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void superman() {
synchronized(lockObject2) {
mHero = "superman";
try {
long sleep = (long) (Math.random()*100);
Thread.sleep(sleep);
if ("superman".equals(mHero) == false) {
System.out.println("synchronization broken");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Java
복사
•
메서드 동기화 방식이 더 깔끔하고 가독성이 좋기 때문에, 해당 클래스 객체에서 다른 메서드가 동기화를 시도하지 않는다면 메서드 동기화 방식을 사용하고 아니라면 코드 블록 동기화 방식을 사용하자.
싱글톤 객체에서의 synchronized
•
싱글톤 객체에서의 synchronized 키워드를 사용하는 것은, 동작 자체는 일반 클래스에서 사용하는 것과 별반 다르지 않다.
•
다만 싱글톤 객체에서 synchronized 키워드는 단일 스레드처럼 동작하기 때문에, synchronized 키워드가 많을수록 병목현상이 심해져 성능과 효율이 떨어진다.
•
따라서 멀티 스레딩 환경에서는 싱글톤 객체는 가급적 사용하지말고, 공유할 객체가 아니라면 객체를 새로 생성해서 쓰고 버리는 방식을 사용하는 것이 좋다.
static synchronized 메서드
•
메서드 동기화는 해당 클래스의 객체의 lock을 사용한다고 언급했었는데, 클래스의 객체가 없는 static 메서드의 경우에 synchronized 키워드를 사용하면 해당 클래스 자체 lock을 사용한다.
•
때문에 static synchronized 메서드들 간에 lock이 공유되어 동기화를 처리할 수 있다.
•
일반적인 synchronized 메서드와 static synchronized 메서드를 혼용해서 사용하면 조금 복잡해진다.
•
일반 synchronized 메서드는 생성된 객체 기준으로 lock을 걸지만, static synchronized 메서드는 해당 클래스 자체 기준으로 lock을 걸어 서로 다른 lock으로 인식해 따로 놀게 된다.
public class StaticFunction {
private static String HERO;
public static void main(String[] agrs) {
System.out.println("Test start!");
new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
StaticFunction.batman();
}
}).start();
new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
StaticFunction.superman();
}
}).start();
StaticFunction sfunction = new StaticFunction();
new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
sfunction.ironman();
}
}).start();
System.out.println("Test end!");
}
public static synchronized void batman() {
HERO = "batman";
try {
long sleep = (long) (Math.random() * 100);
Thread.sleep(sleep);
if ("batman".equals(HERO) == false) {
System.out.println("synchronization broken - batman");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static synchronized void superman() {
HERO = "superman";
try {
long sleep = (long) (Math.random() * 100);
Thread.sleep(sleep);
if ("superman".equals(HERO) == false) {
System.out.println("synchronization broken - superman");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public synchronized void ironman() {
HERO = "ironman";
try {
long sleep = (long) (Math.random() * 100);
Thread.sleep(sleep);
if ("ironman".equals(HERO) == false) {
System.out.println("synchronization broken - ironman");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Java
복사
•
위 코드에서는 synchronization broken이 계속해서 출력하게 된다.
•
이렇게 혼용해서 사용하게되면 동기화가 깨지는데, 실제 코드에서는 코드라인이 길고 스레드마다 호출하는 메서드가 제각각이라 동기화가 깨지는 원인을 찾기가 무척 힘들어진다.
Atomic Type
•
java.util.concurrent.atomic 라이브러리에서 제공하는 동기화 타입으로, CAS 방식에 기반하여 동기화 문제를 해결한다.
•
CAS(Compare And Swap / Compare And Set) 방식은 변수의 값을 변경하기 전에 기존에 가지고 있던 값이 내가 예상하던 값과 같을 경우에만 새로운 값으로 할당하여, CPU 캐시가 잘못된 값을 참조하는 가시성 문제를 해결한 알고리즘이다.
public class AtomicExample {
int val;
public boolean compareAndSwap(int oldVal, int newVal) {
if(val == oldVal) {
val = newVal;
return true;
} else {
return false;
}
}
}
Java
복사
•
일반적으로 CPU가 하나의 CAS만 처리하도록 보장되어 있어, CAS 방식을 사용하면 별도의 동기화 필요 없이 한 번에 하나의 스레드만 값을 변경할 수 있다.
•
CAS 방식은 하드웨어의 도움을 받기 때문에 일반적인 동기화보다 속도가 빠르고 효율이 좋다.
•
구체적인 이유는 아래의 첫 번째 그림처럼 일반 동기화의 경우 block이 풀리더라도 바로 다음 동기화가 진행되지 않지만, CAS 방식은 아래의 두 번째 그림처럼 접근 가능할 때까지 CompareAndSwap을 실행하기 때문에 바로 다음 동기화가 진행 될 수 있다.
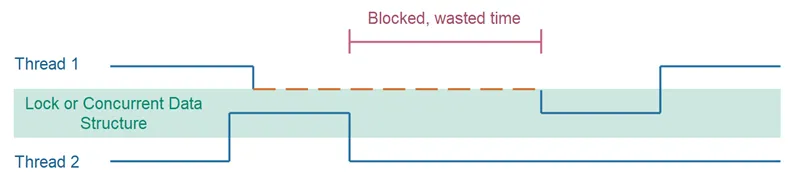
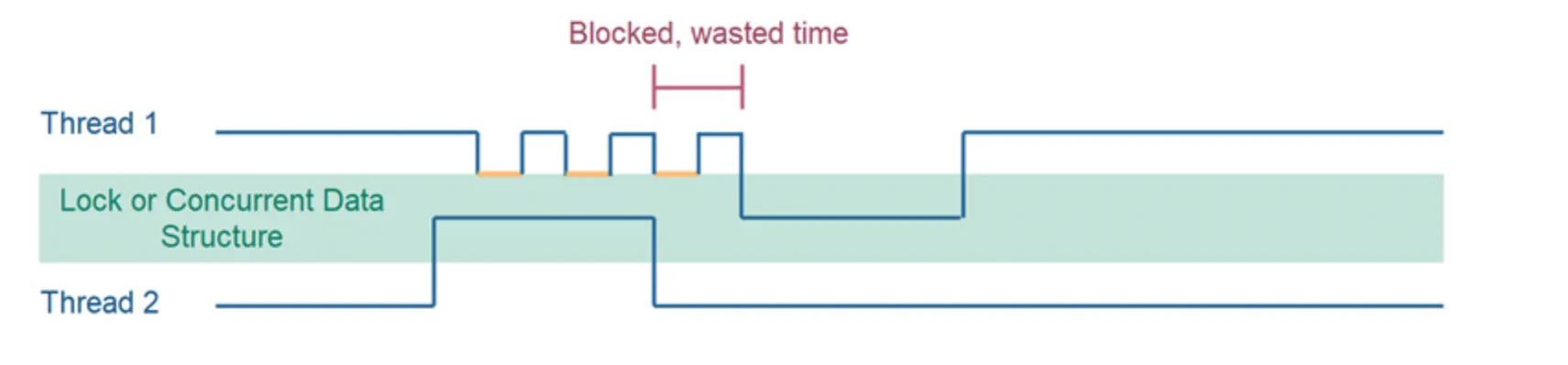
•
Java에서는 이를 구현한 여러 Atomic Type을 제공한다.(AtomicBoolean, AtomicInteger, AtomicLong)
Atomic Type의 여러 메서드들
•
각 Type마다 여러 메서드들을 포함하고 있지만, 아래의 예시들은 모든 Type에 포함되는 메서드들이다.
AtomicLong a1 = new AtomicLong();
a.set(100);
a.get(); // 100
Systme.out.prinln(a.getAndSet(5)); // 100
Systme.out.prinln(a.get()); // 5
Java
복사
◦
set() : 값 쓰기
◦
get() : 값 읽기
◦
getAndSet() : 현재 값을 반환하고 새로운 값으로 업데이트
int expect = 10;
int update = 1000;
AtomicLong a = new AtomicLong(10);
System.out.println(a.compareAndSet(expect,update)); // true
System.out.println(a); // 1000
Java
복사
◦
compareAndSet() : 현재 값이 예상하는 값(expect)과 동일하다면, update 값으로 변경하고 true를 반환한다.
멀티 스레딩 환경의 ArrayList와 Vector
•
ArrayList와 Vector 모두 배열(Array)를 기반으로한 컬렉션으로, 기능상으로는 동일하다.
•
하지만 아래 그림처럼 ArrayList에서는 동기화가 없지만, Vector에는 synchronized 키워드가 붙어있어 동기화를 제공한다.
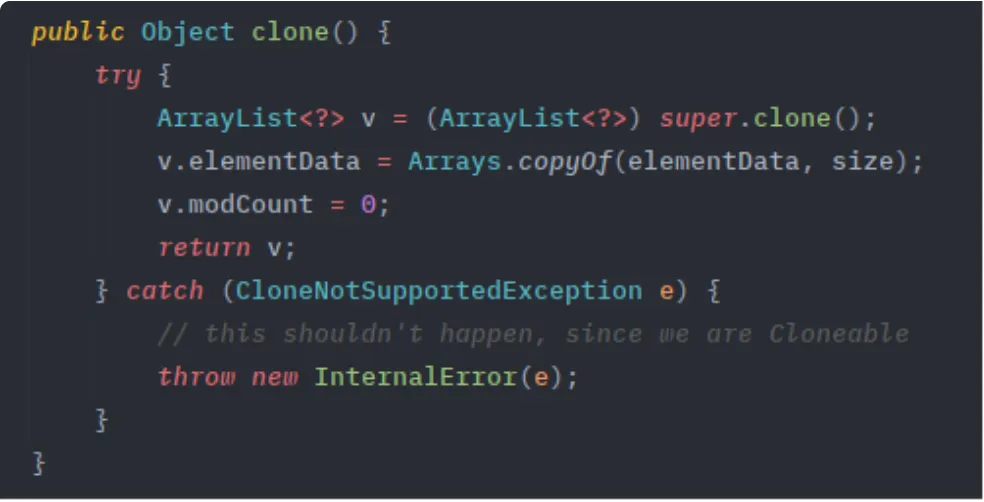
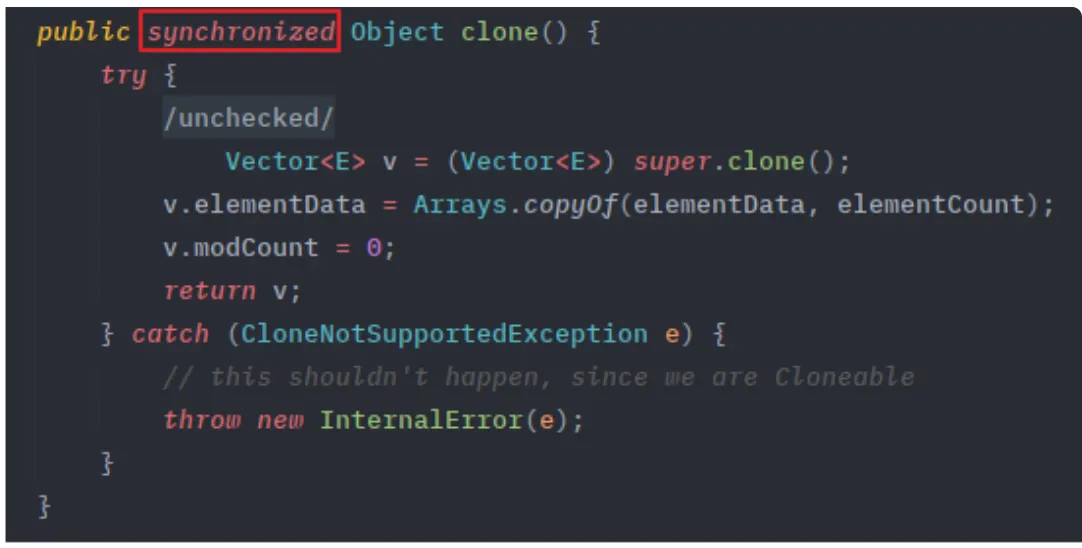
•
다시말해, Vector는 스레드-안전하지만 ArrayList는 동기화 되지 않아 스레드-안전하지 않다.
•
하지만 Vector는 메서드들이 기본적으로 synchronized가 걸려있기 때문에, 경쟁 상태를 따지지 않아도 되는 상황에서도 메서드 동기화 여부를 따지느라 일반 메서드보다 훨씬 느려진다(오버헤드).
•
또한 Vector의 동기화는 메서드에 대해서는 synchronized 처리가 되어있지만, 인스턴스 자체에 대해서는 동기화 처리가 되어있지 않기 때문에 아래와 같은 동시 엑세스에 한해 스레드-안전하지 않다.
public class Main {
public static void main(String[] args) {
Vector<Integer> vec = new Vector<>();
new Thread(() -> {
vec.add(1);
vec.add(2);
vec.add(3);
System.out.println(vec.get(0));
System.out.println(vec.get(1));
System.out.println(vec.get(2));
}).start();
new Thread(() -> {
vec.remove(0);
vec.remove(0);
vec.remove(0);
}).start();
// 출력
new Thread(() -> {
try {
Thread.sleep(1000); // 쓰레드가 다 돌때까지 1초 대기
System.out.println("Vector size : " + vec.size());
} catch (InterruptedException ignored) {
}
}).start();
}
}
Java
복사
•
이 코드를 실행시키면 ArrayIndexOutOfBoundsException이 발생하는데, 그 이유는 메서드 자체 실행은 스레드-안전하지만 Vector 인스턴스 객체 자체에는 동기화가 되어있지 않기 때문이다. 두 개의 스레드에서 동시에 접근해 각기 다른 메서드를 호출하였기 때문에 추가와 삭제를 동시에 진행하는 것이다.
•
이런 Vector를 동기화하기 위해서는 synchronized 블록을 통해 Vector 객체 자체를 따로 동기화 처리해야한다.
•
반면 ArrayList의 경우에는 아래처럼 Collections 클래스의 synchronizedList() 메서드를 통해 동기화 처리가 되어있는 리스트를 사용할 수 있다.
/* ArrayList 동기화 처리 */
List<String> l1 = Collections.synchronizedList(new ArrayList<>());
/* LinkedList 동기화 처리 */
List<String> l2 = Collections.synchronizedList(new LinkedList<>());
/* HashSet 동기화 처리 */
Set<String> s = Collections.synchronizedSet(new HashSet<>());
/* HashMap 동기화 처리 */
Map<String> m = Collections.synchronizedMap(new HashMap<>());
Java
복사
•
사실 Vector는 자바에 컬렉션 프레임워크가 생기기 전부터 존재하던 오래된 클래스로, deprecated 되어 더 이상 사용이 권장되지 않는다.
•
또한 위에 언급했듯 성능도 ArrayList에 비해 크게 떨어지므로, 사용하던대로 ArrayList를 사용하면 된다.
동기화 성능 개선 기법
1.
락 경쟁 줄이기
•
락을 놓고 경쟁하는 상황이 발생하면 순차적으로 처리함과 동시에 컨텍스트 스위칭도 많이 발생하므로, 확장성(scalability)과 성능을 떨어뜨리는 원인이 된다.
•
락 경쟁 상황은 락을 얼마나 빈번하게 확보하려 하는가와 한 번 확보 후 해제까지 얼마나 오래 걸리는가가 중요한 요인이다.
•
락 경쟁을 줄이기 위해 락을 확보한 채 유지하는 시간을 줄이고, 락을 확보하려는 요청 횟수를 줄이자.
2.
락 구역 좁히기
•
락 구역을 좁히는 것은 위의 락 경쟁 줄이는 방법 중 락을 확보한 채 유지 시간을 줄이는 것의 일환이다.
•
락이 필요하지 않은 코드들을 동기화 영역 밖으로 뽑아내 락을 유지하는 시간을 줄이자.
•
단일 연산과 불변 객체나 스레드 안전성이 확보된 클래스를 사용하여 락이 필요 없도록 만드는 것도 락을 점유하는 시간을 최소화 할 수 있는 방법이다.
3.
락 정밀도 높이기
•
락의 정밀도를 높여 락을 확보하려는 요청 횟수를 줄이자.
•
락 분할 기법과 락 스트라이핑과 같은 기법들을 사용해 락이 묶이는 범위를 정밀하게 나누고 앱의 확장성을 높이자.
•
락 분할(lock splitting)
◦
여러 개의 상태 변수를 하나의 락으로 묶는게 아니라 락을 여러 개로 분리하여, 독립적인 상태 변수를 각자 묶어두는 방법이다.
◦
하지만 락의 개수가 많아질수록 교착 상태가 발생할 위험이 높아지니 주의해서 사용해야한다.
•
락 스트라이핑(lock stripping)
◦
상태 변수가 기준이 아닌 특정 구간 블록을 단위로 락을 묶어 동기화 하는 기법이다.
◦
예시로 ConcurrentHasMap 클래스의 경우 16개의 락을 배열로 만들어두고, 각각의 락이 전체 해시 범위의 1/16에 대한 락을 담당한다.
◦
여러 개의 락을 사용하도록 쪼개놓은 블록들 전체를 한꺼번에 독점적으로 사용해야 할 필요가 있을 수 있는데, 이런 경우에 단일 락을 사용하는 것보다 동기화 시키기 어렵고 자원 소모도 많이 한다는 단점이 있다.
4.
비차단 동시성 제어 고려하기
•
비차단 동시성 제어는 non-blocking으로 여러 접근을 제어하는 I/O Multiplexing이나 낙관적 락, CAS처럼 lock 없이 경쟁 상태를 최소화하면서 동시성을 제어하는 방식이다.
•
경쟁 상태 자체가 최소화 되기 때문에 성능향상과 동시성 효율 측면에서 더 좋아질 수 있다.
•
다만 정교하고 복잡한 알고리즘이 필요하고, 구현과 디버깅이 어렵다는 단점이 있다.
5.
핫 필드 최소화
•
모든 연산을 수행할 때마다 한 번씩 사용해야하는 카운터 변수와 같이, 여러 스레드에서 자주 사용되는 변수를 핫 필드(hot field)라 한다.
•
여러 스레드에서 자주 계산하고 사용되는 값을 캐시에 저장해두도록 최적화하면, 락 정밀도를 높이기 위해 쪼개서 사용하는 방법을 적용할 수 없고 확장성을 낮추게 된다.
•
이런 핫 필드들을 최소화하여 락 정밀도와 확장성을 높이자.
6.
CPU 활용도 모니터링
•
일부 CPU만 열심히 일하고 나머지가 놀고 있다면, 프로그램의 병렬성을 높이는 방법을 찾아 적용해야한다.
•
부하가 부족한지 않은 지, I/O 혹은 외부 제약 조건, 락 경쟁 등 여러 원인들을 고려하여 프로그램 병렬성을 높이자.
7.
객체 풀링 하지 말기
•
가비지 컬렉션 처럼 객체 풀을 만들어 사용하는 방법은 소모되는 시간을 줄일 수 있지만, 단일 스레드에서 아주 무겁고 큰 객체를 사용하는게 아니라면 일반적으로 성능에 좋지 않다고 알려져있다.
•
또한 크기가 작거나 중간 크기인 객체를 풀로 관리하는 것은 오히려 자원을 더 많이 소모한다.
•
병렬 앱에서는 객체 풀링을 사용했을 때, 객체 풀 때문에 락 경쟁이 발생하는 상황이 앱의 확장성을 낮추는 병목이 될 수 있다.
•
객체 풀을 적절한 용도가 있고, 성능을 최적화하는데 그다지 좋은 방법은 아니다.