



23강 - 레코드에 순번 붙이기
기본 키가 한 개의 필드일 경우
•
윈도우 함수(ROW_NUMBER())를 사용하자.

→ 없다면 상관 서브쿼리.
기본 키가 여러 개의 필드로 구성될 경우
•
ORDER_BY의 키에 필드를 추가하면 된다.


•
Weight3 테이블의 윈도우 함수(ROW_NUMBER)를 이용한 seq 서브쿼리 결과
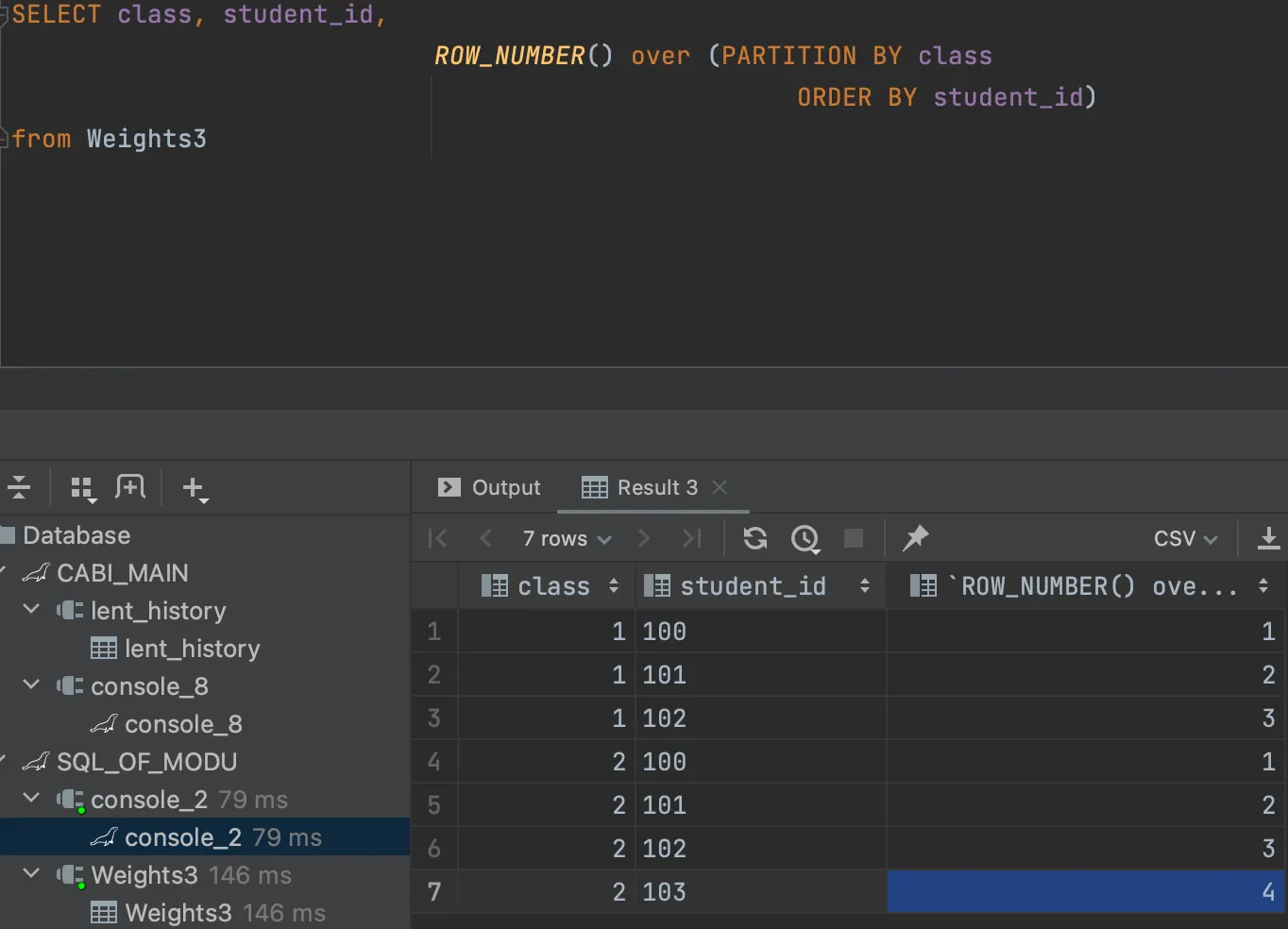
student_id를 기준으로, class를 partition(row_number의 갱신지점)을 지정하여 select한 결과다.
이 서브쿼리를 토대로 update 쿼리를 진행하면 다음과 같이 나타난다.
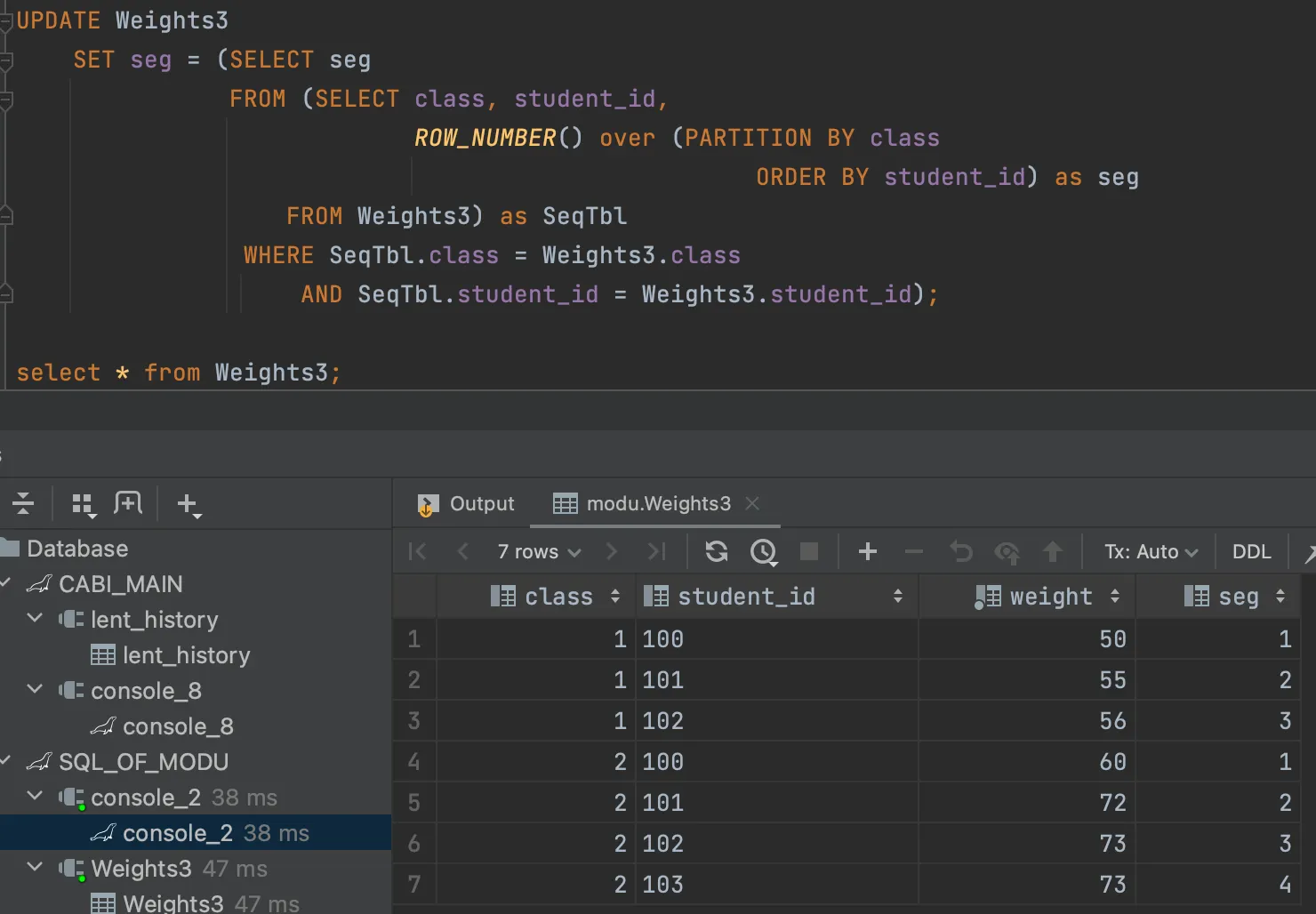
예제에서는 SeqTbl이라는 라벨링 앞에 as가 없는데, 생략가능한 것으로 확인했다.
24강 - 레코드에 순번 붙이기 응용
•
순번은 연속성과 유일성을 가진다는 특징을 기억하자
중앙값(median) 구하기
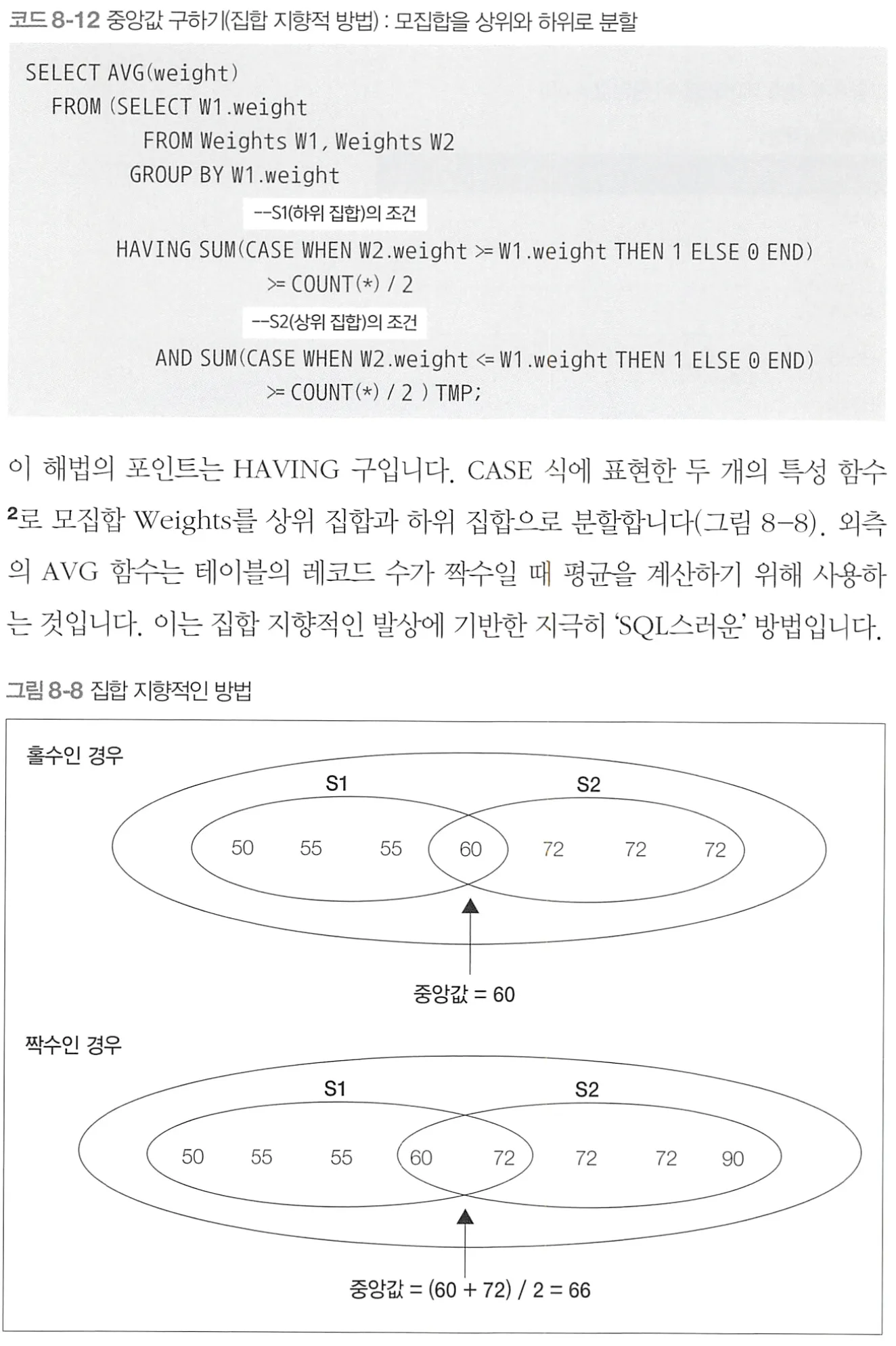
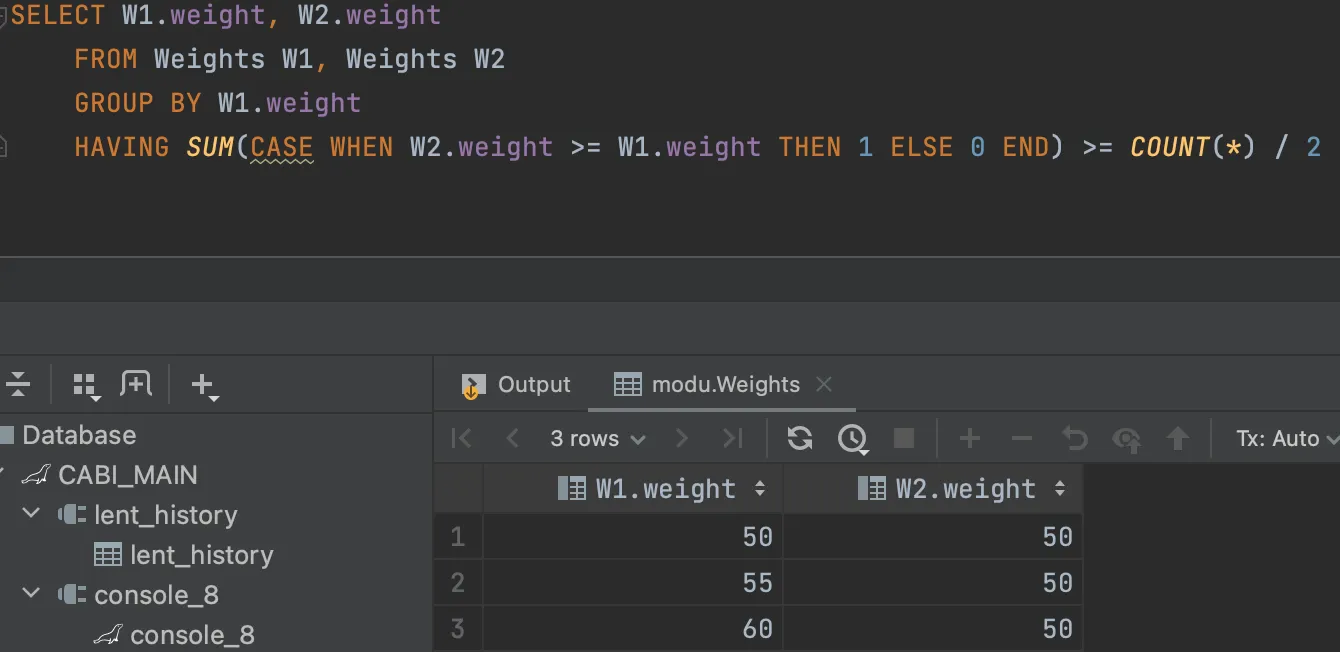
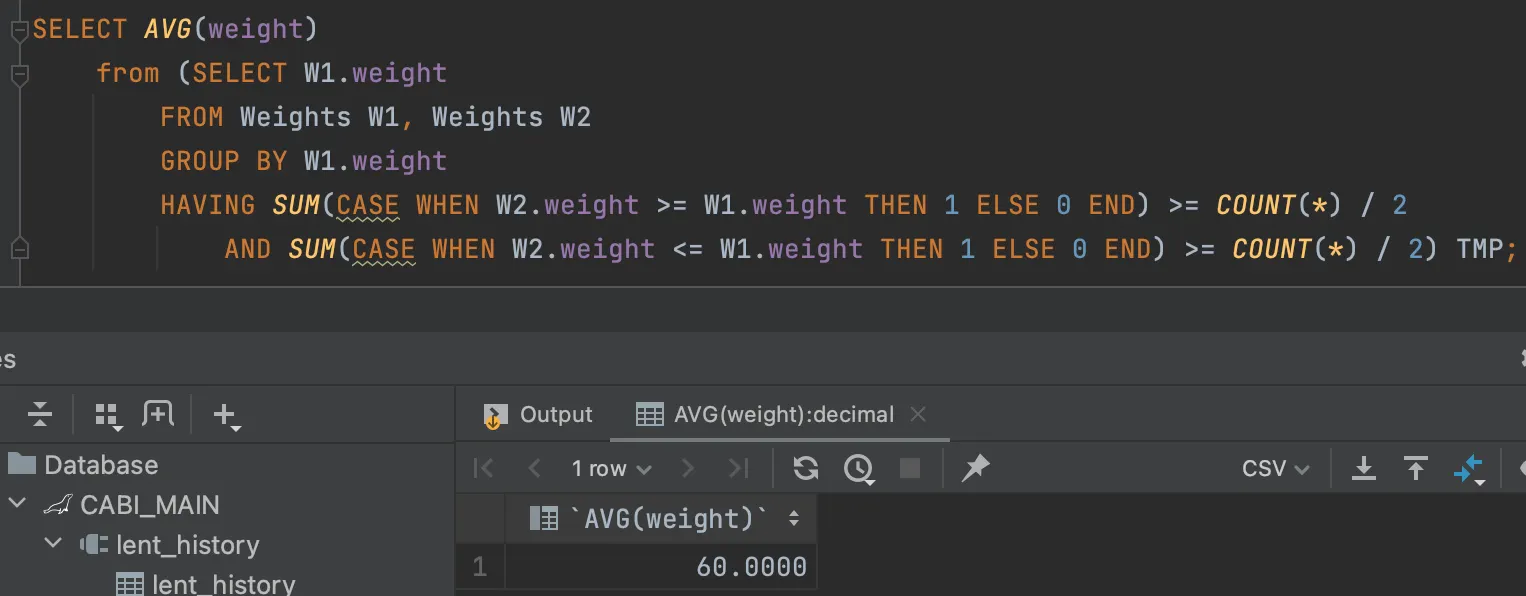
끝에 TMP를 적지 않으면 쿼리가 실패한다. 왜?
→ 당연히 테이블을 SELECT하는 것인데, FROM이 되는 테이블의 별칭이 없으므로 ⇒ 하위 쿼리는 주 쿼리의 일부로 사용(참조)될 수 있도록 별칭을 가져야 한다. 아마도 작동방식인 임시 테이블 생성 때문일 것이다.
한편 위 방법은 실행 계획에서 두번의 NESTED_LOOPS를 갖는다. + 결합도 이뤄진다.
→ 구릴 가능성이 높다.
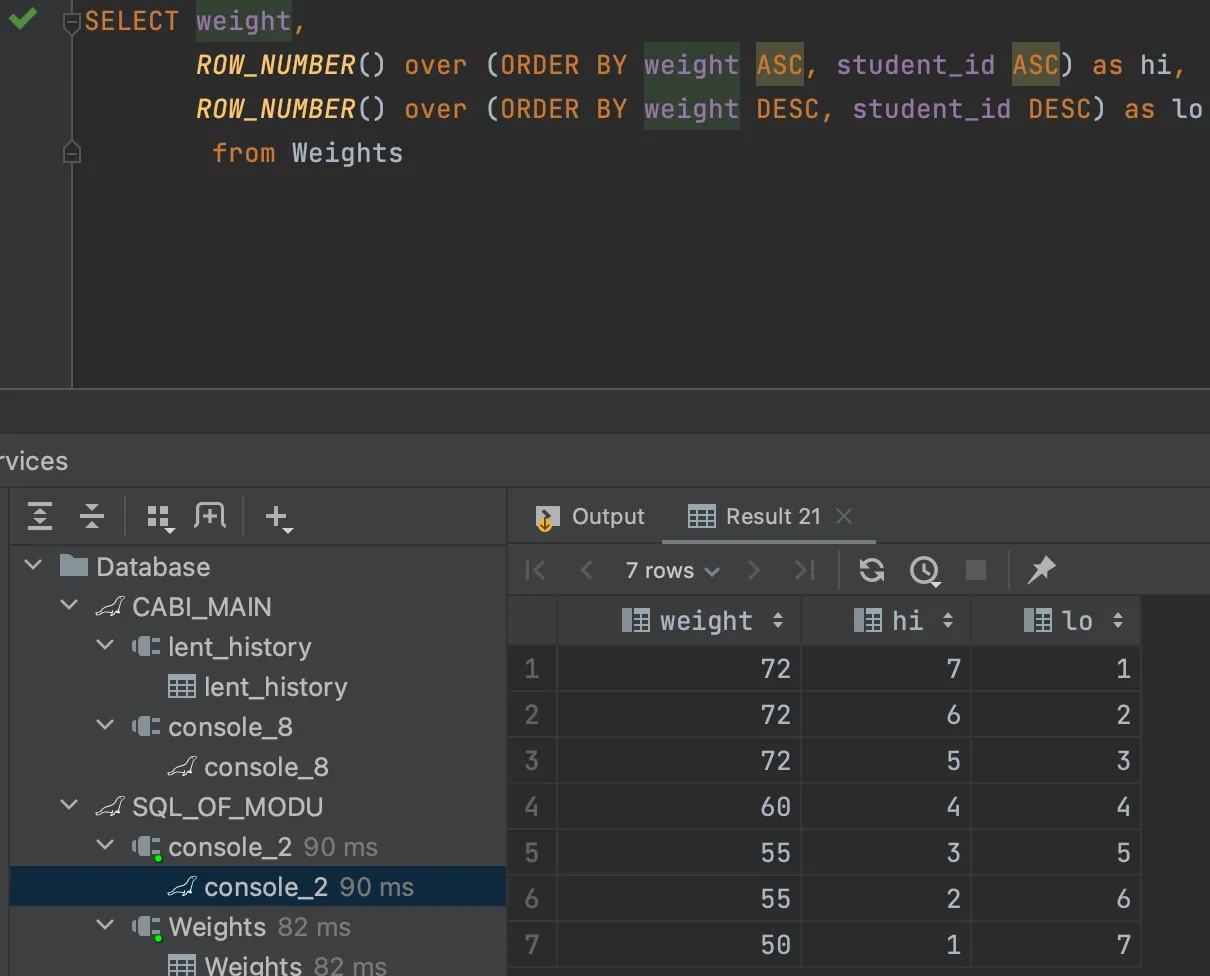

•
Q: student_id를 넣었는데, 왜 포함하지 않으면 NULL인 결과가 나타날 수 있을까?
A: 흠..?
비어있는 급간에 대한 쿼리
집합지향적으로 쿼리를 작성할 수 있지만..
→ 결합을 수반한다는 점에서 구릴 수 있단다.
절차지향적으로 작성할 여지가 있다!
테이블에 존재하는 시퀀스 쿼리
예제가 미친건가..?
어쨌든 서브쿼리의 크기에 따라 TMP 뷰의 생성에서 저장소를 사용할 수 있으므로 성능에서 집합지향vs절차지향 상대적이다.
25강 - 시퀀스 객체, IDENTITY 필드, 채번 테이블
시퀀스 > IDENTITY 필드 이긴 한데 어쨌든 둘 다 쓰지마.
•
보다가 든 시퀀스 객체에 든 의문
기존에 알고 있는 auto increment의 방식과 매우 유사하게 동작하는데.. 그렇다면 PK의 auto_increment 전략은 시퀀스 객체인가?
일단 시퀀스 객체는 사용자 정의이고, 테이블과 연결되지 않기 때문에 여러 테이블에서 공유 가능하다.
한편 IDENTITY는 테이블의 열로서의 속성이므로 공유 불가능하다.
다음 IDENTITY 값을 생성하기 위해서는 테이블에 새 행을 삽입해야 하는데, SEQUENCE 객체에 대한 다음 VALUE는 간단한 메서드로 생성할 수 있다.
IDENTITY 속성은 초기값으로 재설정할 수 없다.
SEQUENCE 객체의 값은 시퀀스를 다시 생성하여 재설정할 수 있다.
AUTO_INCREMENT/IDENTITY 시퀀스는 정의된 테이블에 의해 소유되며 해당 테이블 외부에는 존재하지 않는다.
참고 글

→ PK의 AUTO_INCREMENT는 시퀀스 객체가 아니고, IDENTITY라고 볼 수 있다. (테이블 종속적)
→ 근데 속성 재설정할 수 있던데..? 꼭 IDENTITY는 아닌 듯? 혹은 IDENTITY가 아닌 테이블의 메타데이터를 초기화해버리는 지점에서 다른 얘기이거나..

Hot Spot 문제
시퀀스 객체와 같은 순번, 시간 등의 연속된 데이터를 다룰 때 발생하는 문제.
연속된(비슷한) 데이터를 연속으로 INSERT하면 물리적으로 같은 영역에 저장되고, 실제 하드웨어의 특정 물리적 블록에만 I/O부하가 커지므로 성능 악화가 발생하는데 이를 Hot Spot이라고 한다.
•
해시를 이용해서 연속되더라도 쪼개지도록 한다
•
역 전환 키 인덱스(Reverse Key Index)를 이용한다
→ 물리적으로 1234라는 데이터라면, 4321로 인덱스를 걸어놓는다(한쪽에 몰리지 않고 각 생김새별로 분산되도록).
◦
참고

하지만 구리다는거~