



26강. 갱신은 효율적으로
•
SQL은 DB에서 정보를 검색하는 것을 주요 목적으로 설계되었다.
→ 갱신과 관련된 SQL 구문은 비효율적이고 성능이 좋지 않은 방식으로 작성된다.
1.
NULL 채우기
•
이전 레코드와 같은 값을 가지는 경우 val 필드의 값이 NULL로 되어 있다.

•
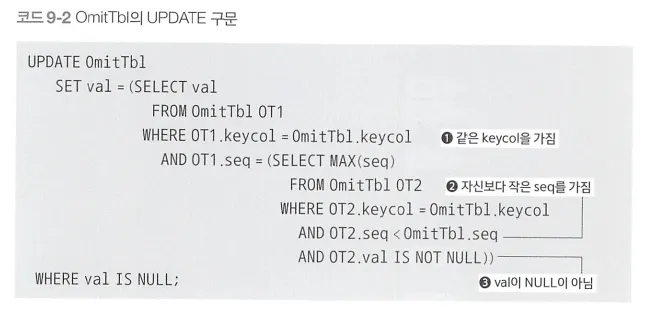
다음과 같은 3가지 조건을 만족하는 레코드 집합에서 가장 큰 sql 값을 가진 레코드를 찾아서 해당 레코드의 val 값으로 갱신한다.

27강. 레코드에서 필드로의 갱신
1.
필드를 하나씩 갱신

•
간단하지만, 3개의 상관 서브쿼리를 실행해야 하기 때문에 성능이 좋지 않다.
2.
다중 필드 할당

•
다중 필드 할당 : 여러 개의 필드를 리스트화하고 한 번에 갱신하는 방법
•
서브쿼리를 한 번에 처리할 수 있어서 성능 향상과 가독성이 좋아진다.
3.
NOT NULL 제약이 걸려있는 경우

•
NULL 값을 0으로 대체
•
MERGE 구문 사용

◦
UPDATE 를 사용할 때는 2개의 장소에 분산되어 있던 결합조건((ScoreColsNN.student-id=SR.studentid)을 ON구로 한번에 끝낼 수 있다.
◦
ScoreColsNN 테이블과 ScoTeRows 테이블의 결합이 1회로 충분하므로 EXISTS를 사용하는 경우보다 성능적으로 나을 수 있다.
28강. 필드에서 레코드로 변경

•
학생별로 갱신 대상 레코드를 subject 필드에 따라 분기
29강. 같은 테이블의 다른 레코드로 갱신
•
INSERT SELECT와 UPDATE의 비교
1.
INSERT SELECT
장점.
•
UPDATE에 비해 성능이 낫다.
•
MySQL처럼 갱신 SQL에서의 자기 참조를 허가하지 않는 데이터베이스에서도 사용할 수 있다. (참조 대상 테이블과 갱신 대상 테이블이 서로 다르기 때문에)
단점.
•
같은 크기와 구조를 가진 데이터를 2개 만들어야 하기 때문에 용량을 2배 이상 소비한다.
30강. 갱신이 초래하는 트레이드오프
•
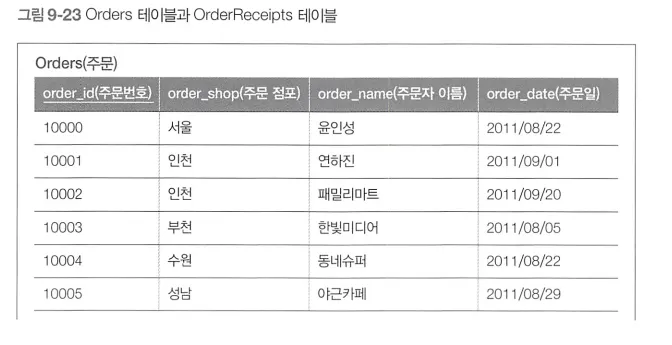
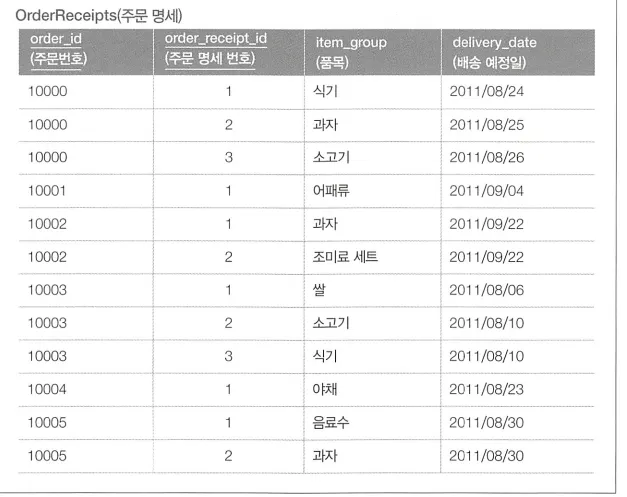
일대다 관계인 Orders테이블과 OrderReceipts 테이블이 있다.
•
주문일과 상품의 배송 예정일의 차이가 3일 이상인 레코드를 판별하고자 한다.
1.
SQL을 사용하는 방법

2.
모델 갱신을 사용하는 방법
•
현재 상태의 테이블 구성을 변경할 수 없다는 전제가 있다면, SQL을 사용하는 방법이 최선일 수 있다.
•
하지만, 이 방법은 결합 또는 집약을 포함한 SQL 구문을 사용하므로 검색 처리에 드는 비용이 높고, 결합에 따른 실행 계획의 변동 리스크가 있는 만큼 장기적 측면에서 성능을 불안정하게 만드는 요인이 잠재되어 있다.
•
반면, 다음과 같이, Orders 테이블에 배송 지연 플래그를 필드로 추가하면, 문제를 한층 쉽게 해결할 수 있다.
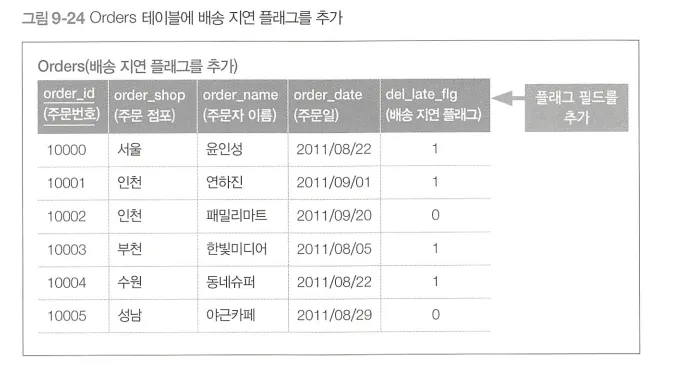
결론 : SQL 구문 외에도 문제를 해결하는 더 좋은 방법이 있을 수 있다. (망치를 잠시 내려놓자)

31강. 모델 갱신의 주의점
1.
높아지는 갱신비용
위에서 본 모델 갱신을 사용하는 방법은 배송 지연 플래그 필드에 값을 넣는 처리가 필요하기에 결국 검색 부하를 갱신 부하로 미루는 꼴이다.
2.
갱신까지의 시간 랙(time rag) 발생
배송 예정일이 주문 등록 후에 갱신되는 경우에는 Orders 테이블의 배송 지연 플래그 필드와 OrderReceipts 테이블의 배송 예정일 필드가 실시간으로 동기화되지 않으므로 차이가 발생할 수 있다.
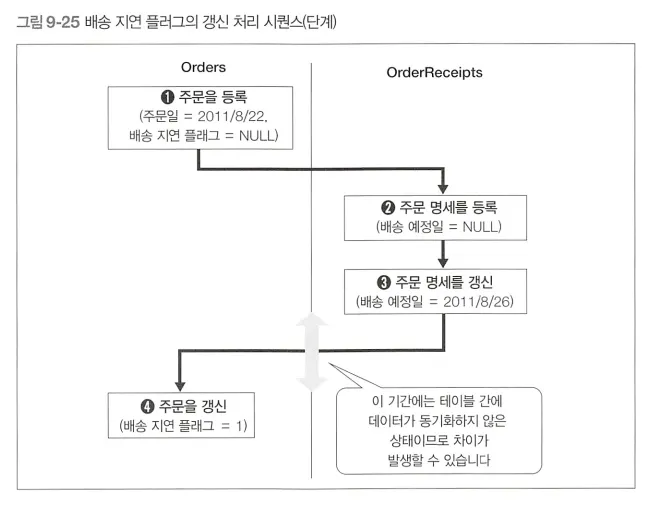
3.
모델 갱신비용 발생
RDB 모델을 갱신하는 것은 코드 기반의 수정(SQL 사용)에 비해 훨씬 큰 폭의 수정을 요구한다.
→ RDB 모델을 수정하면 해당 테이블을 사용하는 다른 처리에도 문제가 발생할 수 있기 때문
32강. 시야 협착 : 관련 문제
문제. 주문 번호마다 몇 개의 상품이 주문 되었는지 파악하고자 함.

위의 문제는 집약 함수 혹은 윈도우 함수를 사용하여 해결할 수 있다.
하지만, 그 전에 모델 갱신과 같은 다른 방식의 방법도 고려할 수 있어야 한다.
33강. 데이터 모델을 지배하는 자가 시스템을 지배한다
데이터 모델이 코드를 결정하지 코드가 데이터 모델을 결정하지 않는다.