



18강 JOIN의 종류
기능적 관점으로 분류
•
cross join
•
inner join
•
outer join
⇒ 서로 배타적인 분류 ( outer 이면서 inner 일 수 없다.)
등기 / 비등가
•
등가 조인 equi join
◦
결합 조건으로 등호(=) 를 사용한다
•
비등가 조인 non Equi join
◦
결합 조건으로 >, ≥ 등의 부등호 을 사용
⇒ outer 이면서 non equi join 일수는 잇다.
Natural Join
Inner Join + Equi join 을 간단하게 작성하는것
SELECT *
FROM Employees NATURAL JOIN Departments
SQL
복사
⇒ 결합 조건을 따로 기술하지 않고, 암묵적으로 같은 이름의 필드가 등호로 결합된다.
SELECT *
FROM Employees E INNER JOIN Departments D
ON E.dept_id = D.dept_id;
SQL
복사
⇒ Natural Join 을 Inner + equi 로 풀어쓸 경우
굳이 사용할 필요는 없다 ⇒ 필드 이름이 다르거나 자료형이 다르면 적용이 안되므로 확장성이 떨어진다.
USING (Nature 와 Inner 의 중간적 형태)
SELECT *
FROM Employees INNER JOIN Departments
USING(dept_id);
SQL
복사
⇒ 웬만하면 그냥 INNER JOIN 써라
Cross Join - Everything
•
실무에서 거의 안씀
작동원리
예시코드
•
데카르트 곱 연산 ⇒ 2개 테이블의 레코드에서 가능한 모든 조합을 구하는 연산
emp_id(사원ID) | emp_name(사원 이름) | dept_id(부서ID) |
001 | 하린 | 10 |
002 | 한미루 | 11 |
003 | 사라 | 11 |
004 | 중민 | 12 |
005 | 옹식 | 12 |
006 | 주아 | 12 |
•
결과
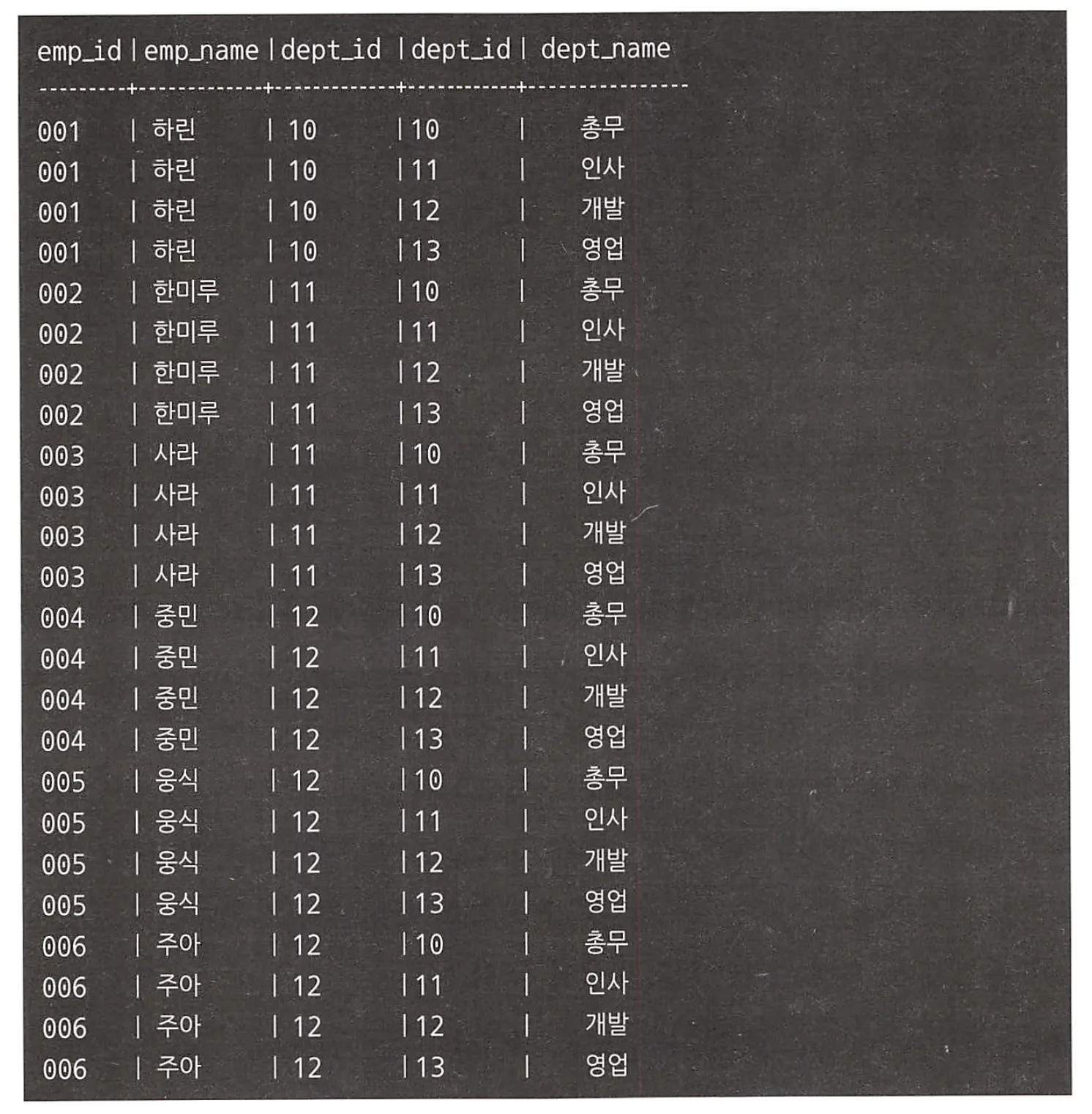
dept_id(부서_ID) | dept_name(부서_이름) |
10 | 총무 |
11 | 인사 |
12 | 개발 |
13 | 영업 |
실무에서 사용되지 않는 이유
•
이런 모든 조합의 결과가 필요한 경우가 없다
•
연산의 비용이 매우 많이 든다.
실수로 사용한 Cross Join
SELECT *
FROM Employees, Departments;
SQL
복사
•
이 경우 Cross Join이 일어난다.
⇒ 이런 실수를 막으려면 표준 SQL에 맞게 결합 구문을 사용하는게 좋다
InnerJoin 내부 결합
작동원리
SELECT E.emp_id, E.emp_name, E.dept_id, D.dept_name
FROM Employees E INNER JOIN Departments D
ON E.dept_id = D.dept_id;
SQL
복사

⇒ 결과는 교집합
실제로는 결합 대상을 최대한 축소하는 형태로 작동한다.
Inner Join 과 같은 기능을 하는 상관 서브 쿼리
SELECT E.emp_id, E.emp_name, E.dept_id, # 사원테이블의 선택
(SELECT D.dept_name #단일값 => 상관 서브쿼리를 스칼라 서브쿼리로 이용
FROM Departments D
WHERE E.dept_id = D.dept_id) AS dept_name
FROM Employees E;
SQL
복사
Employee.dept_id 가 Department.dept_id 와 하나씩 1:1 매칭해서 가져온다
OuterJoin
•
InnerJoin과 배타적 연산
•
데카르트 곱의 부분 집합이 아니다는 의미이나,
•
경우에 따라서 데카르트 곱의 부분 집합이 되기도 한다.
작동 원리
•
Left Outer Join (왼쪽이 마스터)
SELECT E.emp_id, E.emp_name, E.dept_id, D.dept_name
FROM Departments D LEFT OUTER JOIN Employees E
ON D.dept_id = E.dept_id;
SQL
복사
•
Right Outer Join (오른쪽이 마스터)
SELECT E.emp_id, E.emp_name, E.dept_id, D.dept_name
FROM Employees E RIGHT OUTER JOIN Departments D
ON D.dept_id = E.dept_id;
SQL
복사
•
결과
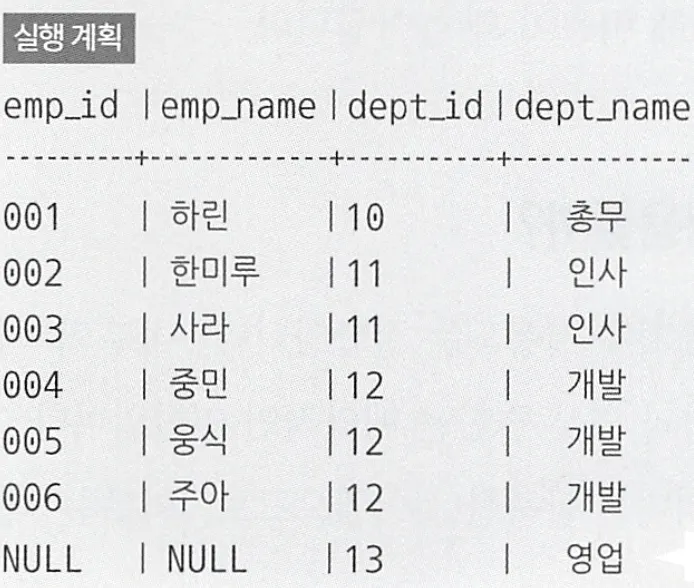
•
마스터 테이블에만 존재하는 키가 있을때는 해당 키를 제거하지 않고 결과에 보존
OuterJoin & InnerJoin 의 차이
Self Join 자기 결합
•
같은 테이블(또는 뷰) 끼리 결합
•
연산의 대상으로 무엇을 사용하는지에 따른 분류
•
Self + Cross , Self + Outer 같은 조합이 가능하다
Self Join 작동
digits |
0 |
1 |
2 |
3 |
… |
9 |
SELECT D1.digit + (D2.digit * 10) AS seq
FROM Digits D1 CROSS JOIN Digits D2;
SQL
복사
결과
100개의 레코드
0 1 2 ... 97 98 99
SQL
복사
•
Digits(D1) Digit(D2) 10 X 10 결과 출력
SelfJoin의 사고방식
•
Digit 테이블을 D1과 D2 라는 별칭을 붙여 마치 다른 테이블인 것처럼 다룬다.

19강 Join 알고리즘과 성능
옵티마이저가 선택 가능한 알고리즘은 세가지
⇒ 데이터 크기
또는
Join Key의 분산에 의존
•
Nested Loops
가장 빈번, 결합 알고리즘의 기본
•
Hash
두번째로 중요
•
Sort Merge
세번째로 중요, 지원하지 않는 DBMS도 있다
⇒ 최신 동향에따라 바뀌기도 한다.
1. Nested Loops
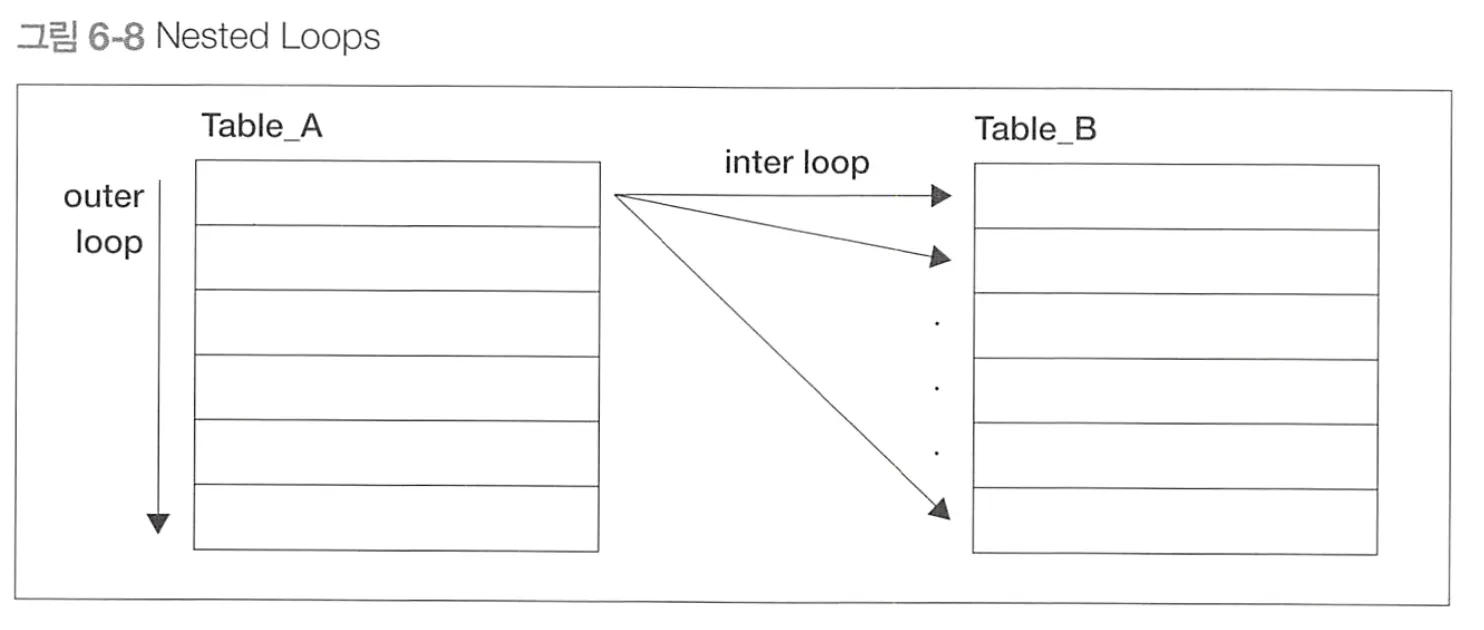
•
중첩 반복 사용
1.
결합 대상 테이블(Table_A) 에서 레코드를 하나씩 반복해가며 스캔합니다.
이 테이블을 구동 테이블(driving table) 또는 외부 테이블(outer table)이라고 부른다.
스캔 대상의 테이블은 Table_B 내부테이블(inner table) 이라 부른다.
2.
구동 테이블의 레코드 하나마다 내부 테이블의 레코드를 하나씩 스캔해서 결합 조건에 맞으면 리턴
3.
이 작동을 구동테이블의 모든 레코드에 반복
•
Table_A, Table_B 의 결합 대상 레코드를 R(A), R(B) 라고할때,
레코드 수는 R(A) * R(B)
실행시간은 레코드 수에 비례
(EXISTS 를 사용할대의 semi-join 또는 NOT EXISTS 사용시, Anti-Join 에서는 반드시 내부 테이블의 모든 레코드에 접근할 필요가 없으므로 레코드수가 감소하는 경향이 있다. ⇒ 하지만 다중반복 로직은 똑같음, 레코드 수만 조금 줄 뿐)
구동 테이블을 작게
내부 테이블의 결합 키 필드에 인덱스가 존재
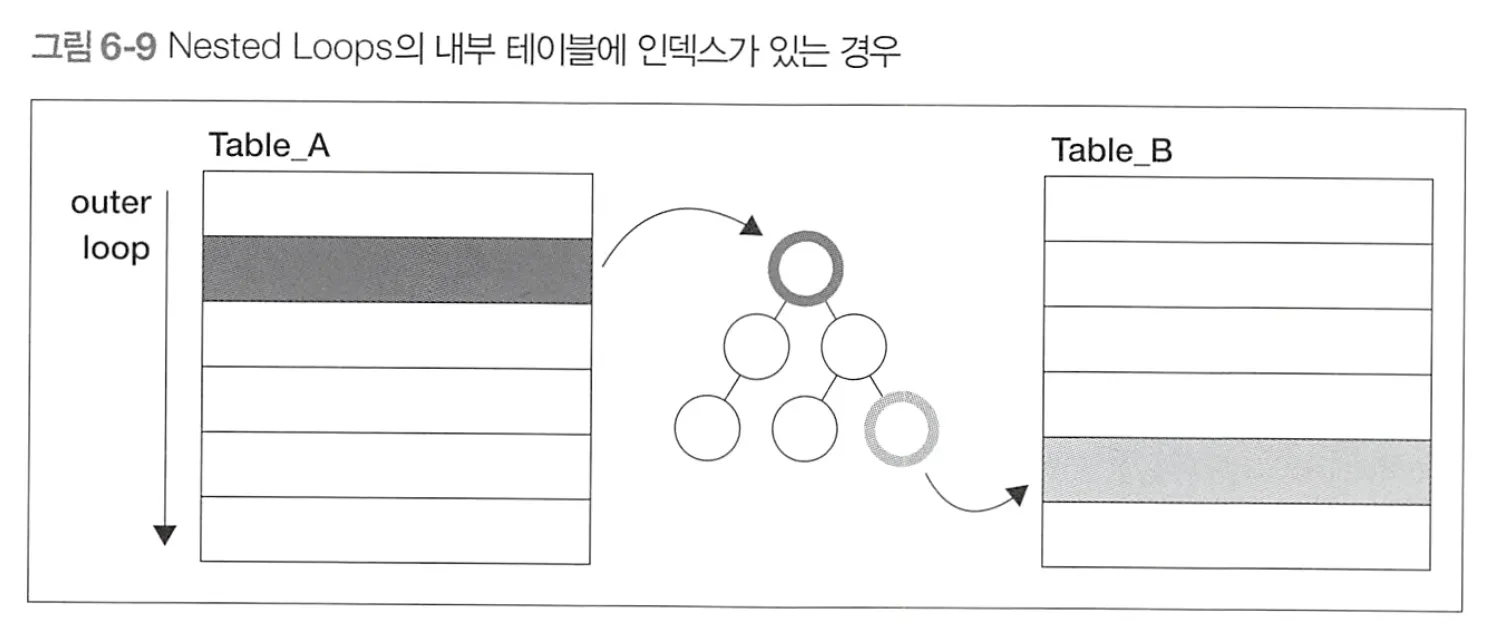
•
내부 테이블의 반복을 어느 정도 건너 뛸 수 있게 된다.
•
이상적인경우는 구동테이블의 레코드 한개에 내부 테이블의 레코드 한 개가 대응하고,
해당 레코드를 내부 테이블의 인덱스를 사용해 찾을 수 있는 경우(반복없이 찾는경우)
이 경우 R(A) X 2
SELECT E.emp_id, E.emp_name, E.dept_id, D.dept_name
FROM Employees E INNER JOIN Departments D
ON E.dept_id = D.dept_id;
SQL
복사


•
내부 테이블의 결합 키 인덱스(department_pkey, PK_DEP)가 사용된다면 내부 테이블의 반복을 생략할 수 있으므로 NestedLoop가 빨라진다.
Oracle
•
내부 테이블의 반복을 완전히 생략할 수 있는 경우는 결합 키가 내부 테이블에 대해 유일한 경우 뿐
◦
등치 결합 이라면 내부 테이블의 접근 대상 레코드를 한개로 한정할 수 있으므로, 이중 반복의 내측에 있는 반복을 완전히 생략가능
⇒equal join? 뭔소리임
JOIN을 했을때, 1:1 대응될때?
이런경우 내부 테이블이 결과가 몇천건이라도, 하나의 레코드만 접근한다.\
•
결합 키가 내부 테이블에 유일하지 않은경우
◦
인덱스로 내부 테이블에 접근하는 경우라도, 여러개의 레코드가 히트될 수 있다.
◦
여러개의 레코드에 반복을 적용 (INDEX RANGE SCAN oracle)
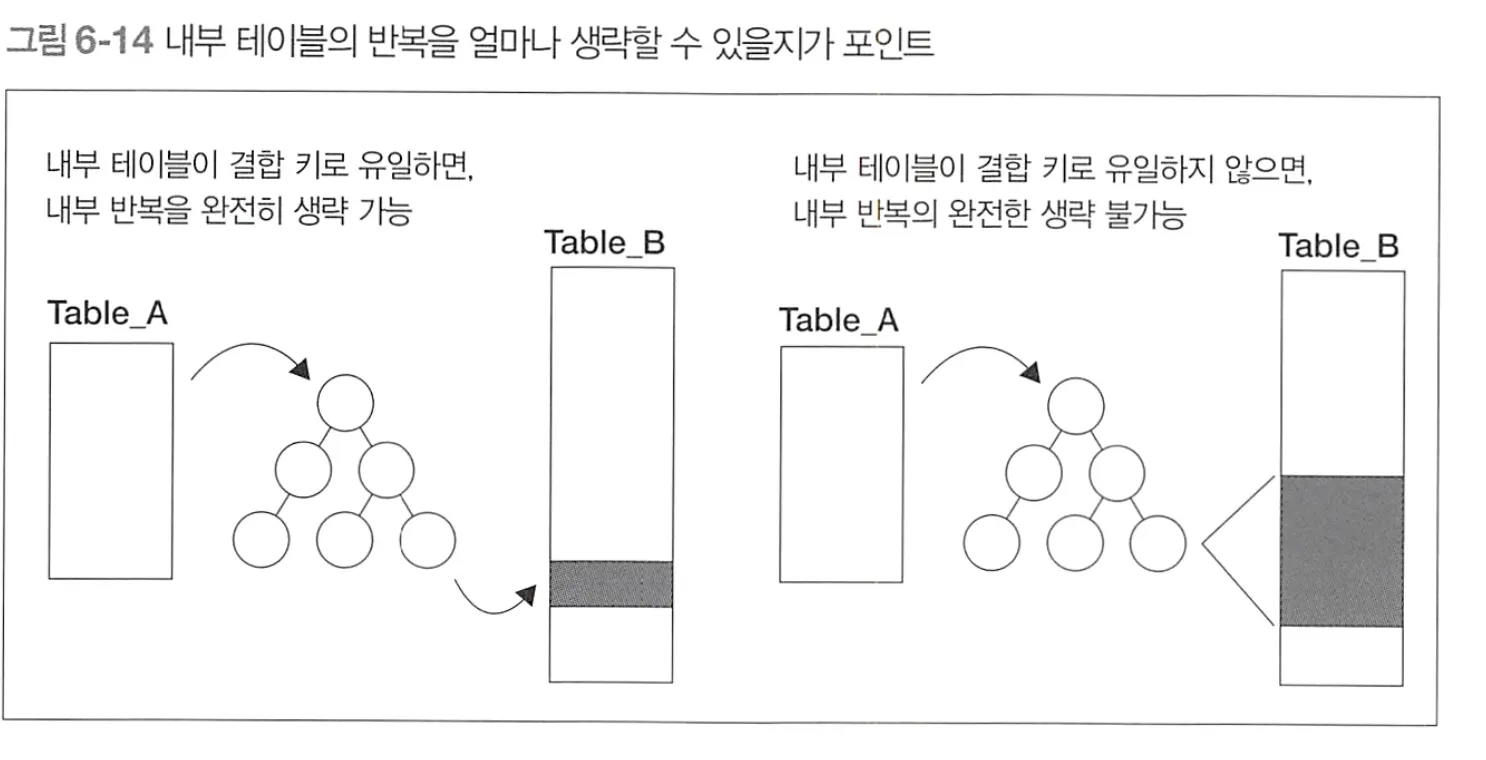
⇒ 구동 테이블을 작게, 내부테이블을 크게
⇒ 내부 테이블이 클수록 인덱스 사용으로 인한 반복 생략 효과가 커진다
구동 테이블이 작은 NestedLoops + 내부 테이블의 결합 키에 인덱스
⇒ 조회하려는 테이블이 작은 NestedLoops + 결합대상이 되는 테이블의 결합 키(아마도 FK?)에 인덱스
단점
•
결합 키로 내부 테이블에 접근할 때 히트되는 레코드가 많을때 느리다
결합 키가 내부 테이블에 대해 유일하지 않은 경우
인덱스를 사용해서 반복을 생략해도, 절대적인 양이 너무 많은경우
•
점포 테이블 & 받은 주문 테이블
◦
점포에 대해 여러개의 주문이 대응하니까 → 점포 테이블이 작다
점포 테이블을 구동 테이블로 잡고, 점포 ID 를 결합키로 사용
하지만 한 개의 점포 ID에 수백만건, 수천만 건의 레코드가 주문테이블에서 히트된다면,
결국 반복 횟수가 많아져서 성능이 낮아진다.
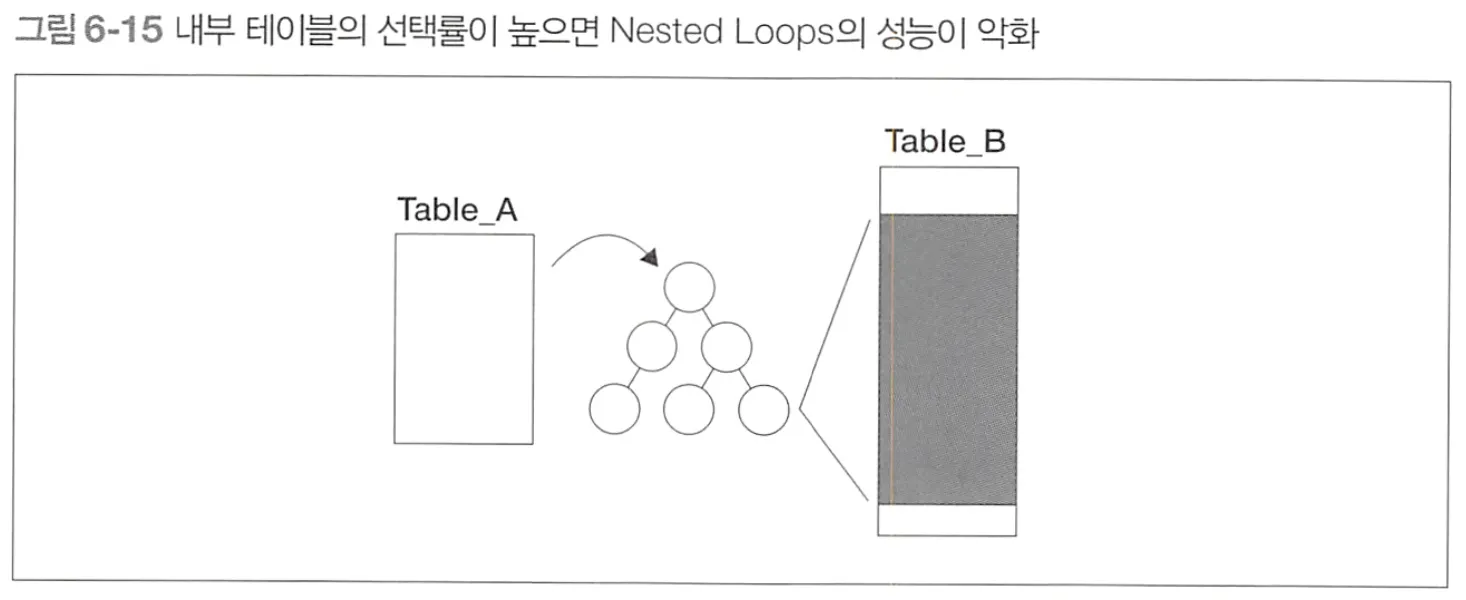
⇒ SQL 성능은 결국 데이터양에 의존한다
느릴때 대처방법
1.
구동테이블로 큰 테이블을 선택하는 역설적인 방법
내부 테이블에 대한 점포 테이블의 접근이 PK(점포ID)로 수행되므로, 항상 하나의 레코드로 접근하는 것이 보장된다.
따라서 점포에 따른 성능 비균등 문제 해결 ⇒ 극단적 성능 저하 저지
⇒ 주문 테이블이이라는 거대 테이블 접근비용이 현실적인 범위라면 효과적
2.
해시
2. Hash
hash 의 작동
입력에 대해 어느 정도 유일성과 균일성을 가진 값을 출력하는 함수 ⇒ 해시
해시결합
일단 작은 테이블을 스캔하고, 결합 키에 해시 함수를 적용해서 해시값으로 변환 (해시값의 집합⇒해시테이블)
이어서 다른 테이블(큰 테이블)을 스캔하고, 결합 키가 해시값에 존재하는지 확인하는 방법으로 JOIN
⇒ hash 가 사용될경우 어느 한쪽이 극단적으로 작거나 크지 않다. 구동테이블이라고 부르지 말자
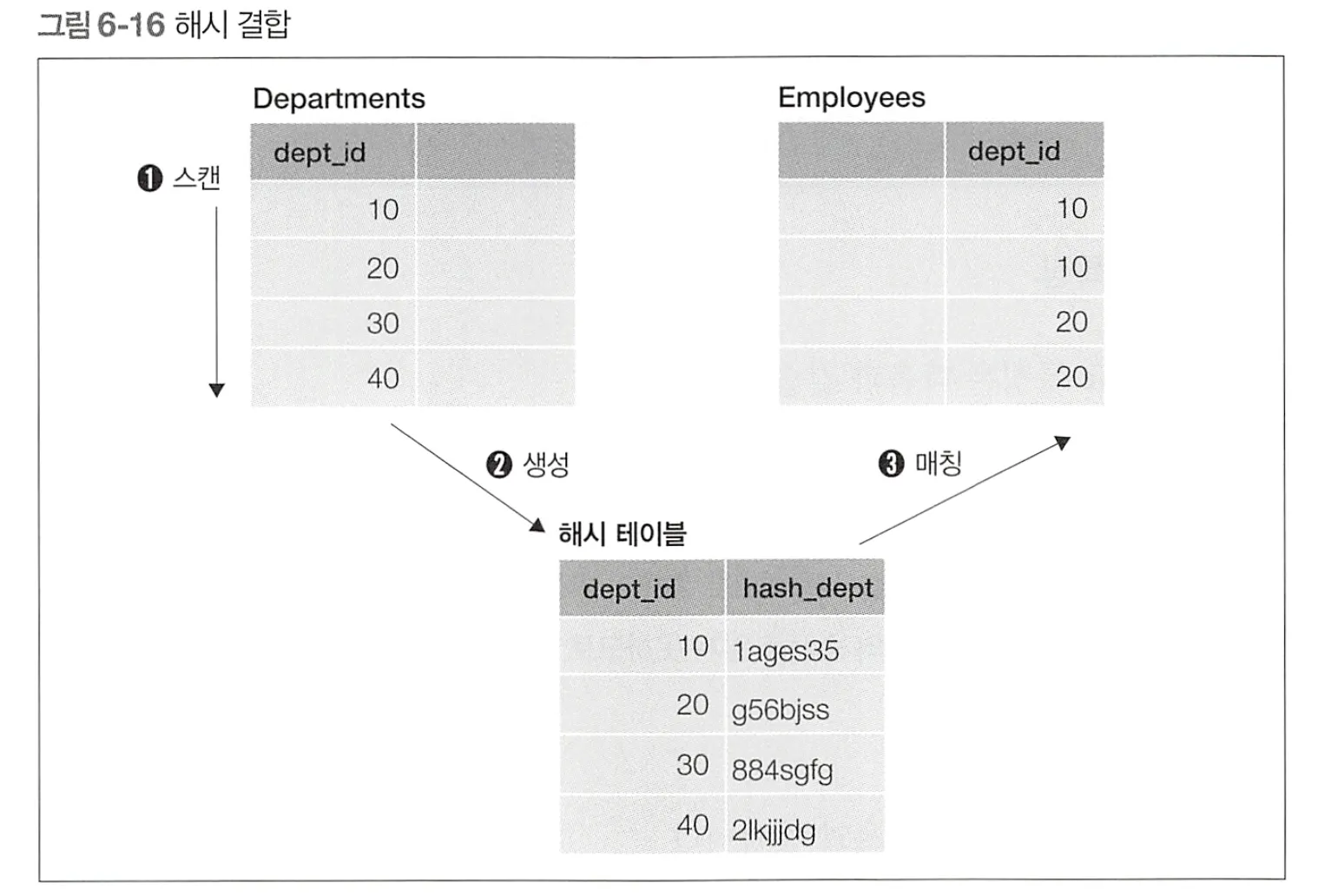
•
결합 테이블로부터 hash table 을 만들어서 활용하므로, Nested Loop 에 비해 메모리를 크게 소모한다.
•
메모리가 부족하면 저장소를 사용하므로 딜레이 발생
•
출력되는 해시값은 입력값의 순서를 알지 못하므로, 등치 결합에만 사용 가능
Hash 가 유용한 경우
•
Nested Loop에서 적절한 구동 테이블(상대적으로 충분히 작은 테이블)이 존재하지 않는경우
•
구동 테이블로 사용할만한 작은 테이블은 있지만, 내부 테이블에서 히트되는 레코드 수가 너무 많은 경우
•
Nested Loops의 내부 테이블에 인덱스가 존재하지 않는(또는 여러 가지 사정에 의해 인덱스를 추가할 수 없는) 경우
•
Nested Loops 가 효율적으로 작동하지 않는 경우의 차선책
느린경우
OLTP(Online Transactional Processing) 처리 ( 사용자 요구에 시스템이 곧바로 응답해야하는 처리 - 웹 앱 등) 에서 Hash가 사용되면, DBMS가 사용할 수있는 메모리가 부족→ 저장소 사용 → 딜레이
BI/DWH( Business Intelligence / DataWareHouse) 와 같은 시스템에 한해 사용
Hash 결합은 반드시 양쪽 테이블의 레코드를 전부 읽어야 하므로, 테이블 풀 스캔이 보통 쓰인다. ⇒ 이 시간도 고려해야함
3. Sort Merge
작동 원리
Nested Loops가 비효율적일때 Hash 외로 SortMerge 사용
Merge 또는 Merge Join 이라 부르기도 한다
•
결합 대상 테이블들을 각각 결합 키로 정렬하고, 일치하는 결합 키를 찾으면 결합
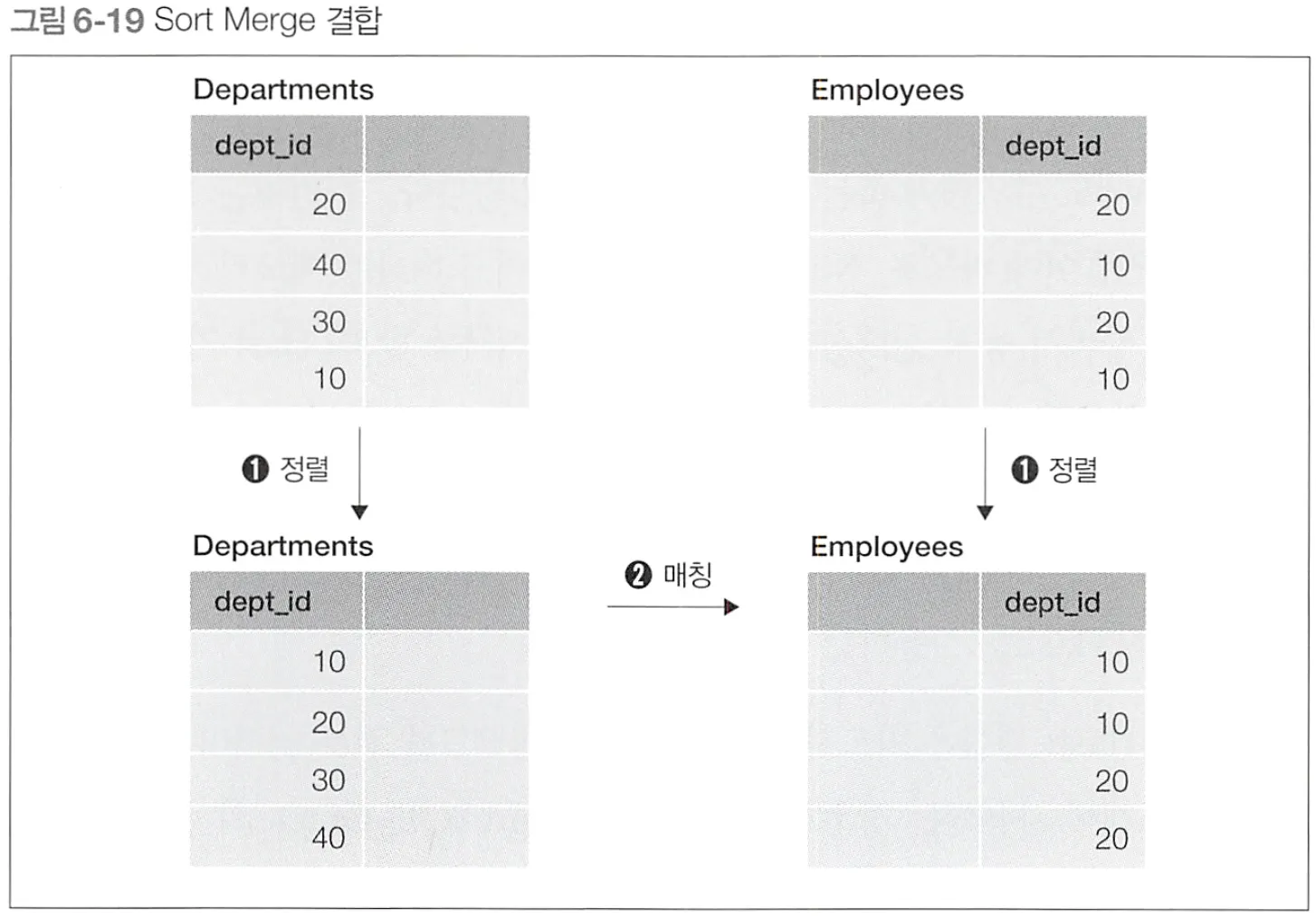
1.
대상 테이블을 모두 정렬해야하므로 Nested Loop 보다 많은 메모리 소비
Hash 와 비교하면 규모에 따라 다르지만, Hash는 한쪽 테이블에만 만드는 것에비해, 더 많은 메모리를 소모할 수 있다.
2.
동치 결합 뿐만 아니라 부등호 결합에도 사용 가능 하지만 부정 조건 <> 결합에서는 사용 불가
3.
원리적으로는 테이블이 결합키로 정렬되어 있다면 정렬을 생략할 수 있다.
다만 이는 SQL에서 테이블에 있는 레코드의 물리적인 위치를 알고 있을 때. 이러한 생략은 구현 의존적
4.
테이블을 정렬하므로, 한쪽 테이블을 모두 스캔한 시점에 결합 완료
Sort Merge 가 유효한 경우
테이블 정렬을 생략할 수 있는경우 (상당히 예외적이다)
4. Cross Join
의도치 않게 나타나는 경우
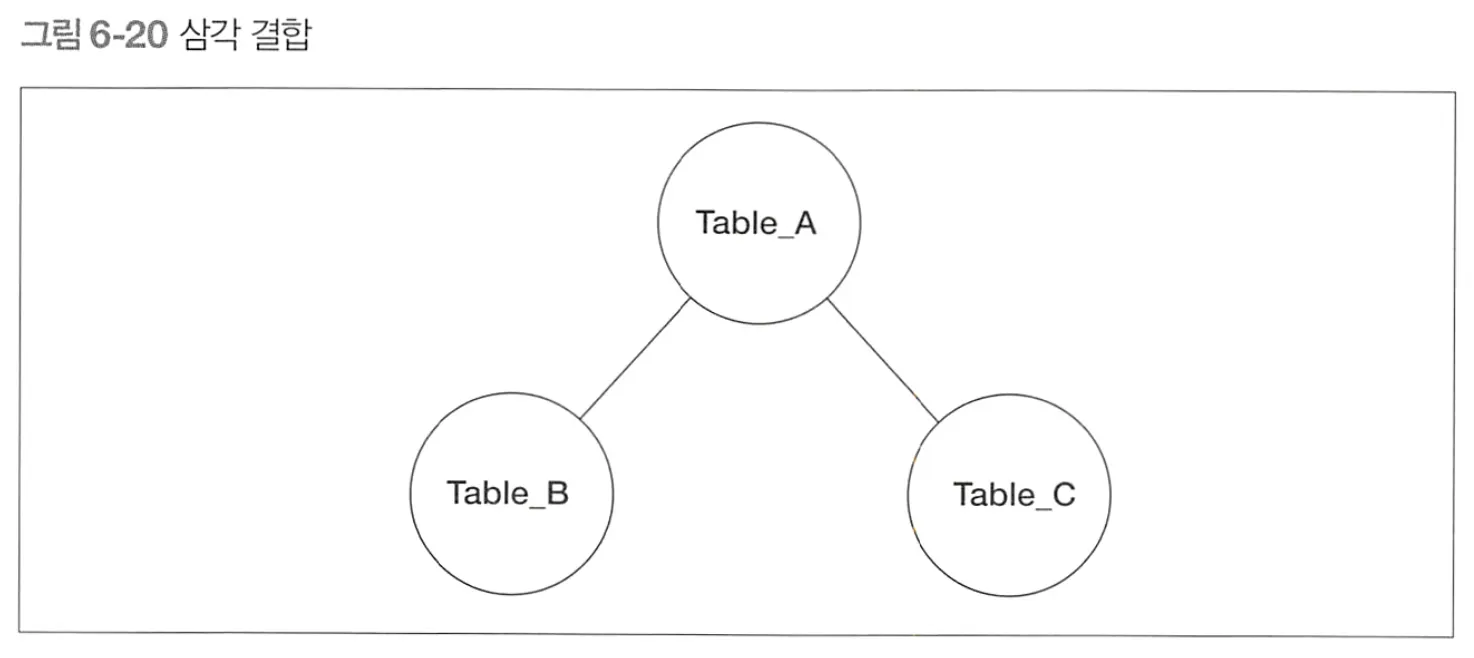
◦
삼각 결합
SELECT A.col_a, B.col_b, C.col_c
FROM Table_A A
INNER JOIN Table_B B
ON A.col_a = B.col_b
INNER JOIN TAble_C C
ON A.col_a = C.col_c;
SQL
복사
◦
A, B, C 테이블 결합
◦
A-B, A-C 결합
◦
B-C에는 결합 조건이 존재하지 않는다.
Cross Join 이 선택되는 경우
B와 C가 먼저 결합되고, 그 결과를 A와 결합하는 순서로 결합을 수행할때
B-C 에는 결합조건이 없으므로 CrossJoin을 하게 된다.
⇒옵티마이저가 B 와 C의 크기를 작다고 평가했을때
큰테이블 A에 두번 결합하기보다는 먼저 작은거부터 결합함으로 횟수를 줄이려한다.
의도하지 않은 크로스 결합을 회피하는 방법
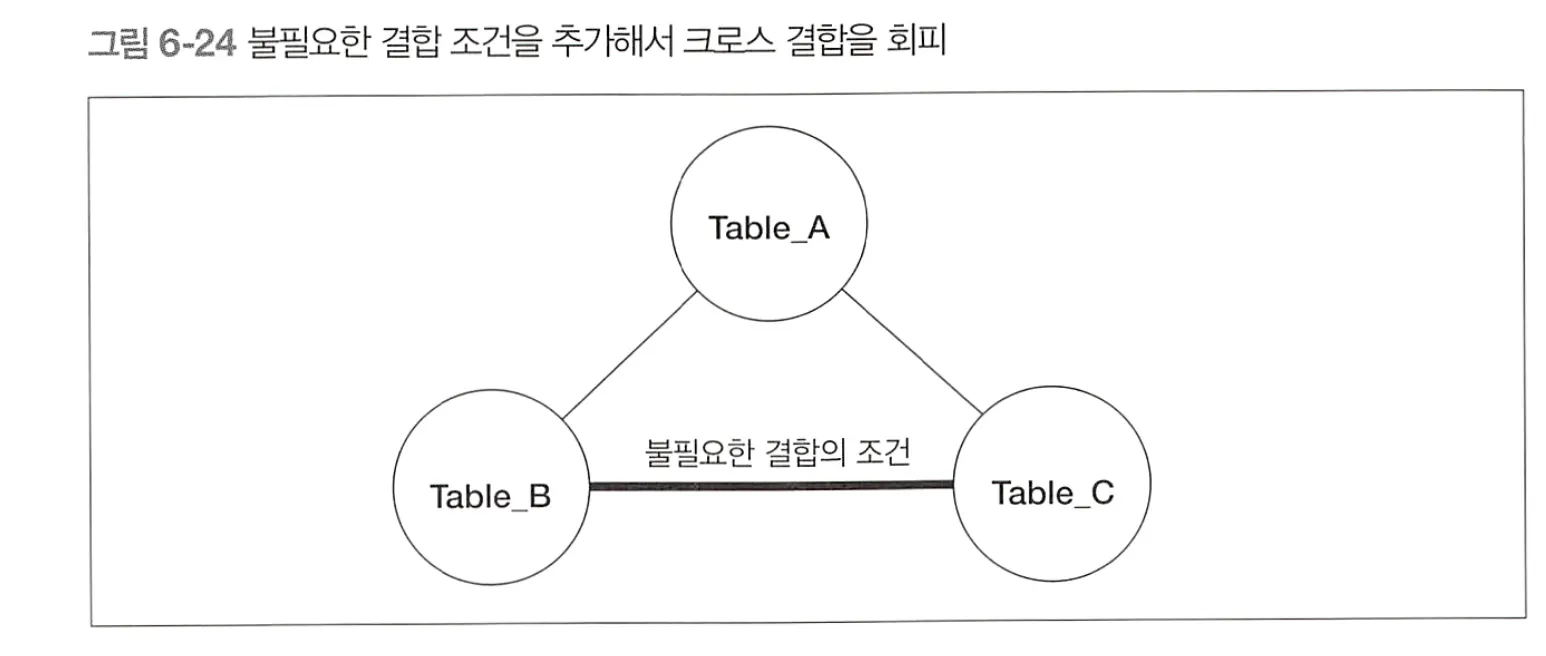
◦
B 와 C사이 조건 지정
SELECT A.col_a, B.col_b, C.col_c
FROM Table_A A
INNER JOIN Table_B B
ON A.col_a = B.Col_b
INNER JOIN Table_C C
ON A.col_a = C.col_c
AND C.col_C = B.col_b; -- Table_B 와 Table_C 의 결합조건
SQL
복사
20강 - 결합이 느리다면
1. 상황에 따른 최적의 결합 알고리즘
이름 | 장점 | 단점 |
Nested Loops | - 작은 구동 테이블 + 내부 테이블의 인덱스 라는 조건이 있다면 굉장히 빠르다
OLTP에 적합
비등가 결합에서도 사용 가능 | 대규모 테이블들의 결합에는 부적합
내부 테이블의 인덱스가 사용되지 않거나, 내부 테이블의 선택률이 높으면 느리다 |
Hash | 대규모 테이블 결합시 적합 | 메모리 소비량이 큰 OLTP에 부적합
메모리 부족시 TEMP 탈락 발생
등가결합에서만 사용 가능 |
Sort Merget | 대규모 테이블들을 결합
비등가 결합에서도 사용 가능 | 메모리 소비량이 큰 OLTP에 부적합
메모리 부족이 일어나면 TEMP 탈락 발생
데이터가 정렬되어있지 않다면 비효율적 |
•
소규모 -소규모
◦
결합 대상 테이블이 작은경우에는 뭘 쓰든 비슷
•
소규모 - 대규모
◦
소규모 테이블을 구동 테이블로 하는 Nested Loop를 사용
대규모 테이블의 결합 키에 인덱스를 만들어 줘라
하지만 내부 테이블의 결합 대상 레코드가 너무 많으면 구동 테이블과 내부 테이블을 바꾸거나 HASH 사용 검토
•
대규모 - 대규모
◦
일단 Hash, 키로 정령되어 있는 상태면 Sort merge
2. 실행 계획 제어
•
실행 계획은 통계정보로 옵티마이저가 자동으로 세우게 되어있다
•
하지만 바꾸려면
◦
Oracle : USE_NL, USE_HASH, USE_MERGE
◦
MsSQL : Hint 구로 알고리즘 제어 가능 (LOOP, HASH, MERGE)
◦
PostgreSQL: pg_hint_plan 기능 사용, 서버 매개변수로 디비 전체 제어 가능
enable_nestloop, enable_hashjoin, enable_mergejoin
◦
MYSQL
▪
결합 알고리즘 자체가 Nested Loops 계열밖에 없음 제어 불가
◦
DB2
▪
제어 불가
◦
실행계획을 사용자가 제어할 때의 리스크
▪
하지마
▪
검토 잘 해봐
3. 흔들리는 실행 계획
•
결합 하지마