



26강 - 갱신은 효율적으로
책에서 말하는 갱신은 아마도 SET을 의미하는 것 같다.
제발.. 영어 병기좀 해줬으면.
DDL, DML, DCL, TCL
•
DDL(데이터 정의, Data Definition Language)
CREATE, ALTER, DROP, RENAME, TRUNCATE
보면, 테이블 자체에 대한 조작임을 알 수 있다.
•
DML(데이터 조작, Data Manipulation Language)
SELECT, INSERT, UPDATE, DELETE
테이블에 있는 데이터(Row)들에 대한 조작임을 알 수 있다.
•
DCL(데이터 제어, Data Control Language)
GRANT, REVOKE
데이터베이스 및 테이블에 대한 권한 제어와 관련된 명령어이다.
•
TCL(트랜잭션 제어, Transaction Control Language)
COMMIT, ROLLBACK, SAVEPOINT
트랜잭션을 제어하는 명령어.
덧붙임 - DISTINCT는 temp 테이블을 형성해서 사용하므로, GROUP BY를 이용하는 것보다 부하가 높을 가능성이 높다.
27강 - 레코드에서 필드로의 갱신

SELECT가 3번으로 서브쿼리가 들어간다.
해결 방법…?

하나씩 지정해서 SET하는 것이 아닌, 다중 필드를 갱신하는 방법을 사용하면된다. 하지~만 Oracle에서 된다는 점~
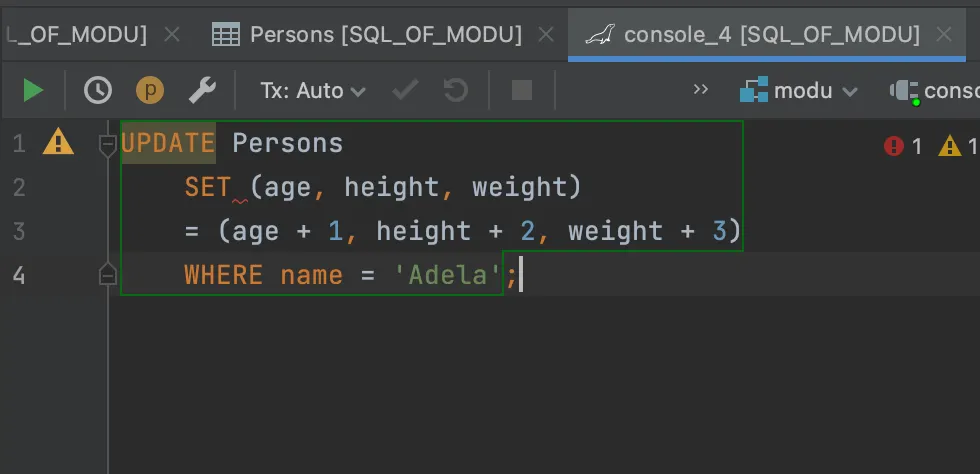
MaraiDB(MySQL) 상에서는 아직 지원을 안하는 것 같다. (검색해도 처음 나온 방법으로만 아티클이 있음)
MERGE는 UPDATE와 INSERT를 한번에 시행하려고 고안된 기술이다.
상관 서브쿼리 많이 쓰는 것 보다 MERGE 쓰는 편이 좋을 것이다.
28강 - 필드에서 레코드로 변경
CASE WHEN THEN 잘 써서 할 수 있다.
29강 - 같은 테이블의 다른 레코드로 갱신
•
이쯤 오니 이 책에서는 비즈니스 로직이 담긴 데이터에 대해서 DBMS 자체에서 작성하는 방법을 알려주는 것 같다. 그와 반해 우리가 주로 사용하게 되는 경우는 DB는 데이터로서만 존재하고, 해당 데이터를 직접 WAS에서 처리해서 사용하는.. 방식이지 않나 싶다.
→ 그렇다면 어떤 점에서 데이터의 생긴 면이 다른걸까? E-R 모델을 충실히 따르는 패턴으로 인한걸까? 직접적으로 데이터를 DBMS 자체에서 응용, 활용하는 경우가 아니고, E-R로 철저히 데이터-서비스를 분리하려고 하는 3 Tier 아키텍처 자체에서 나타나는 특징 때문에 이 책의 주된 응용 내용들에 대해서 물음표가 찍히는 것 같다.
→ 그렇게 생각해보니, 백엔드 개발자에게 테스트를 줄 때, SQL 문제에서 그렇게까지 빡센 쿼리를 물어보지 않는 이유도 알 것 같다. 아마도 ‘그렇게 까지 복잡한 쿼리’를 작성할 일이 없게끔(비즈니스 로직을 DBMS에 사용할이 없게끔)하는 구조로 작업을 하게 되기 때문이 아닐까..
…
INSERT SELECT vs UPDATE
INSERT SELECT가 일반적으로 UPDATE 보다는 성능적으로 낫다고 한다.
또, MySQL에서는 자기 참조를 허가하지 않는데(그래서 우리가 계속 참조에 대한 별칭을 AS로 달아줌), INSERT SELECT는 사용할 수 있다고 한다(참조 테이블과 갱신 테이블이 서로 다른 테이블이라는 것이 포인트)
30강 - 갱신이 초래하는 트레이드 오프
책에서 나타나는 결합을 이용한 예시의 경우가 아마도 흔히 우리가 사용하는 방법(DBMS에서 했다는 것 제외하면)일 것이다.
책에서는 del_late_flag와 같은 플래그를 컬럼으로 추가해서 해결하는 방법을 제안했는데, 나는 이에 대해서 반대한다.
…
책의 입장에서는 철저히 DBMS상에서 데이터를 관리하고, 처리하는 방법을 택하겠지만 우리의 입장에서 E-R 모델로 이뤄진 데이터는 철저히 데이터로서만 남아야하고, 오히려 비즈니스 로직이 아예 덜어져 있는 깨끗한 상태로 남겨져야 한다고 생각한다.
이전에 이런 상황과 비슷한 일을 겪었었는데, 낙관적 락의 트랜잭션 관리를 위해서 Cabinet 엔티티에 대여/반납마다 갱신되는 데이터에 대한 컬럼이 필요했었다. 그 이유는, 낙관적 락을 사용하려면 Versioning(해당 레코드의 변경사항에 따라 증가함)이 필요했는데, 이를 위한 컬럼이 따로 없었기 때문이다.
(lent_history와 외래키로 cabinet 또한 엮여 있어서 잠금이 전파되는데, lent_history의 동시다발적 insert-여러 명이 동시 대여-하는 상황에 있어서 데드락이 발생했음)
이를 해결하기 위한 방법으로 ‘대여 인원 수’에 대한 컬럼을 cabinet에 추가하자는 의견이 있었다. 맨 처음에 나는 ‘왜 대여와 사물함 도메인(엔티티)이 나뉘어 있는데 사물함이 대여에 대한 정보를 가져야하는 것이지?’와 같은 의문을 품었다. && ‘비즈니스 문제를 해결하기 위해서 데이터에 WAS에서 해결할 수 있는 일을 DBMS에 걸어야하나?’와 같은 생각을 했었다.
한편 이 때에는 서비스적으로 동시성 문제가 크리티컬 한 부분이었고, 해결할 방법이 마땅치 않았었다(물론 이후에 방법을 찾아서 해결했음). 그래서 해당 컬럼에 로우를 추가했었고, 낙관적 락을 사용하려다가 이전에 정리하고 해결해서 쓴 글로 다시 비관적 락으로 수정된게 지금 버전이다.
이전 경험을 통해 지금 책에서 제시하는 방안을 생각해보면, 다음과 같은 쟁점이 있다.
•
단순히 해결할 수 없는 일이어서 비즈니스적으로 기존 데이터의 일관성을 깨뜨릴만 한 상황인가?
•
WAS 자체에서 해결할 수 없는 일인가?
이 두 상황에서 이전의 상황은 두가지 모두 다 해당한다고 생각했었다. 내가 생각하는 프로그래밍의 큰 기준은 ‘일관성’이다(결국 가독성과 유지보수가 중요할테니). 이 지점에서 책에서 제시하는 부분은 두가지 모두 다 해당하지 않는다고 생각한다. 만약 적용하게 된다면 ‘그렇게 따지면 그냥 다 집어넣지 왜?’가 가능하다고 생각한다.
… 책에서도 다음과 같은 문제점을 지적한다.
•
높아지는 갱신 비용 - 추가적인 처리 및 UPDATE
•
갱신까지의 Time Lag(오타 뭐임) 발생 - 실시간 정합성의 문제
•
내 생각 : 추가적인 컬럼 데이터 처리를 위해 비즈니스 로직으로 처리되었어야할 값을 DB에 새로 심어주려고, 해당 엔티티에 대한 트랜잭션 내에서 비즈니스 로직 값을 세팅하는 부분이 서비스 로직에서 드러나는 것 (책임의 혼재).
33강 - 데이터 모델을 지배하는 자가 시스템을 지배한다.
•
데이터 모델이 코드를 결정하지, 코드가 데이터 모델을 결정하지 않는다.
→ 그래서 정책 - 뷰 - ERD 설계로 이어지는 방식(탑다운)을 채택하는 이유인 것 같다. 언어가 사고를 결정한다는 얘기랑 비슷한 느낌.
•
코드는 수단이다. 개떡같은 총을 들어도 명사수(잘 구성된 데이터 구조)면 잘 맞출 가능성이 높다.