



반복계와 포장계
반복계 : 행 하나씩 절차적으로 처리하는 방식
포장계 : 여러 행을 한번에 처리하는 방식
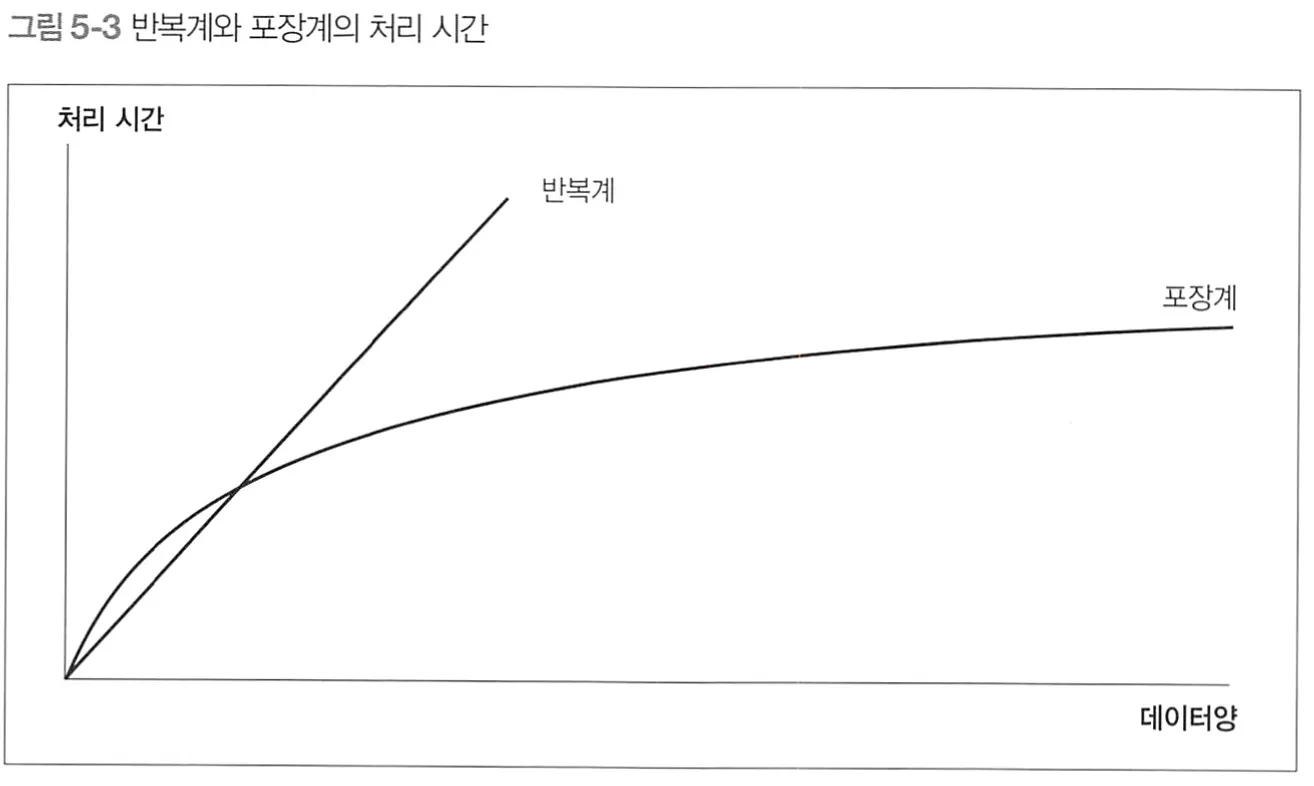
반복계는 (처리 횟수 * 처리 시간)이므로 선형적이다.
포장계는 큰 변화가 없는 한(인덱스를 사용하고, 실행 계획이 바뀌지 않는 한) 대체로 대수적(방정식의 근)이다.
…
반복계의 단점
반복계의 경우 SQL 실행할 때의 오버헤드를 더욱 많이 갖게 된다.
•
네트워크 연결(네트워크 - DBMS)
•
구문 Parse
•
실행 계획 평가 - 생성
•
결과 전송
위 두가지에서 꽤 많은 시간을 잡아먹게되므로, 불필요한 오버헤드가 발생할 수 있는 것이다.
•
반복계는 리소스 분산이 불가능하므로 병렬처리가 어렵다.
•
DBMS는 진화하고 있는데, 옵티마이저와 성능의 개선은 대용량 데이터 처리를 중점적으로 진행되므로 반복계가 갖는 작은 쿼리들에 대해서는 혜택을 받기 어렵다.
•
튜닝의 한계가 명확하기에 성능개선이 필요한 경우 어플리케이션의 재조정이 필요할 것이다..
JPA는 반복계를 최적화할까?
반복계의 장점
•
실행계획이 단순하다.
→ 실행 계획의 변경 여지가 별로 없다.
→ 일관된 성능을 보장한다.
•
단순한 만큼 예측가능성이 높기에 처리 시간이나 속도에 대한 정밀도가 높다.
•
반복계는 iterating하므로, 트랜잭션 중간에 실패했더라도 지정하여 다시 수행할 수 있다.
CASE와 윈도우 함수를 이용해서 반복계를 해결할 수 있다.
•
CASE를 통한 조건 분기 및 해당 값에 따른 윈도우 함수 + 집약 함수의 응용으로 원하는 결과를 해결할 수 있다(한방 쿼리로 해결하기).
•
윈도우 함수를 이용하면 추가적인 스캔을 줄일 수 있다.
•
재귀를 통해서 횟수를 추적할 수 없는 경우에 대해서도 수행할 수 있다.
→ 근데.. WAS를 구현하는 입장에서 DB에 로직이 매우 많이 들어가서(예를 들면 위에서 나타난 재귀) 하나의 쿼리가 뚱뚱해지는 것 또한 병렬처리나 스케일링에 부담을 주는 행위 아닌가..?
결론
•
집합 지향적 사고를 가지렴
•
절차지향적이지 않은 사고를 가지렴
•
반복계가 아닌 포장계를 떠올리렴