



14강. 반복문 의존증
•
SQL에는 반복문이 없다. → 반복문이 없는 것이 편하고 생산성에 도움을 주기 때문
15강. 반복계의 공포
•
반복계 - 레코드를 하나씩 읽고 쓰는 형태로 사용하는 방식
•
포장계 - 여러 레코드를 한 번에 처리하는 방식
•
반복계 SQL을 사용하는 예시
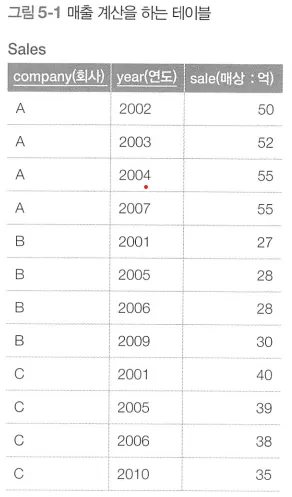
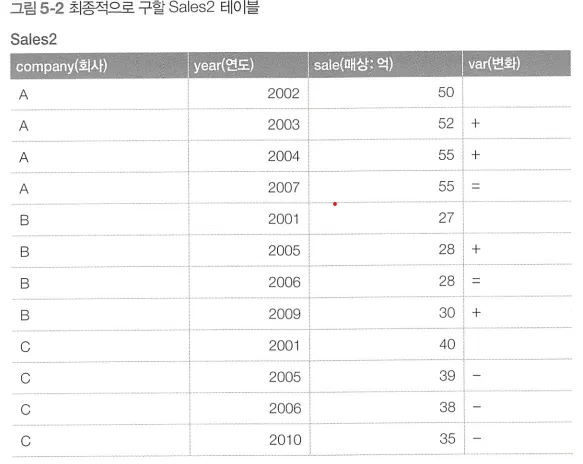
•
왼쪽 테이블에 var 필드를 추가하여 오른쪽 테이블을 만들기 위해 사용하는 SQL 구문

•
반복계 SQL 문장은 단순하다.
1.
반복계의 단점
•
레코드 수가 많아질수록 포장계로 구현한 SQL에 비해서 성능이 현저히 떨어진다.
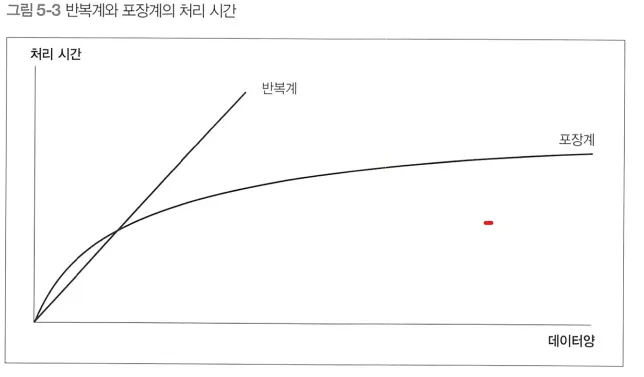
•
반복계의 처리 시간 = { (처리 횟수) * (하나의 처리에 걸리는 시간) } 이므로 ‘하나의 처리에 걸리는 시간’이 일정하다고 가정하면 처리 횟수에 비례한다.
•
포장계의 처리 시간은 SQL 패턴에 따라 다를 수 있지만, 인덱스를 사용하고 실행 계획의 변동이 없다면 일반적으로 위와 같은 완만한 곡선을 그리게 된다.
→ 리소스 부족 등의 상황이 일어나서 TEMP 탈락 같은 일이 발생하지 않는 경우에 대한 가정
•
SQL 실행의 오버헤드
◦
SQL을 실행할 때는 데이터를 검색하거나 연산하는 일 외에도 다양한 처리가 이루어진다.

▪
일정 규모 이상의 시스템에서는 애플리케이션 서버와 데이터베이스 서버가 물리적으로 분리되어 있기 때문에 1번과 5번의 일이 필요하다. 하지만, 일반적으로 두 서버는 동일 LAN 위에 있으므로 전송 속도가 굉장히 빠른 만큼 오버헤드가 크지 않다.
▪
2번은 데이터베이스에 연결해서 세션을 설정하기 위한 처리이다. 최근에는 애플리케이션에서 미리 일정 수의 DB와의 커넥션을 확보하는 커넥션 풀 기술을 사용하기 때문에 크게 문제 되지 않는다.
→ 커넥션 풀을 사용하지 않는 경우 DB와의 빈번한 연결과 해제에 따른 오버헤드가 매우 클 수 있다.
▪
3번과 4번에서 가장 큰 오버헤드가 발생한다. 특히 SQL 구문 분석은 느린 경우 0.1초~1초 정도의 시간이 걸린다. 특히 SQL 파스는 DB가 SQL을 받을 때마다 실행되므로 작은 SQL을 여러 번 반복하는 반복계에서는 오버헤드가 커질 수 밖에 없다.
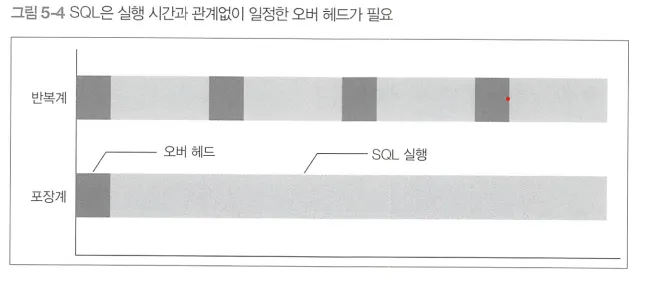
▪
즉, 부수적인 일(오버헤드)을 줄일 수록 중요한 일 (SQL 실행)에 대한 더 많이 확보할 수 있다.
•
병렬 분산이 힘들다
◦
반복계는 반복 1회 마다의 처리를 굉장히 단순화하기 때문에, 리소스를 분산해서 병렬 처리하는 최적화가 힘들기 때문에 리소스 사용 효율이 낮다.
•
데이터베이스의 진화로 인한 혜택을 받을 수 없다
◦
DB가 처리해야 하는 데이터양이 급격히 증가함에 따라, 옵티마이저와 같은 소프트웨어와 SSD와 같은 하드웨어 부문 양쪽에서 발전이 이루어지고 있지만, 이는 대규모 데이터를 다루는 복잡한 SQL 구문(포장계)을 빠르게 하려는 것이 목적이다.
◦
무엇보다도, 포장계의 SQL은 튜닝할 수록 성능의 개선 여지가 크지만, 반복계의 SQL은 튜닝 가능성이 거의 없다. 특히 INSERT 구문은 실행 계획이 너무 단순해서 튜닝을 할 수 없다.
2.
반복계를 빠르게 만드는 방법은 없을까?
a.
반복계를 포장계로 다시 작성 → 현실적이지 않다.
b.
각각의 SQL의 성능을 개선 → 반복계 SQL 구문은 너무 단순해서 튜닝할 만한 부분이 마땅치 않다.
c.
다중화 처리 → CPU나 디스크와 같은 리소스에 여유가 있고, 처리를 나눌 수 있는 키가 명확하게 정해져 있다면, 처리를 다중화해서 성능을 개선할 수 있다.
 처리를 나눌 수 있는 키?
처리를 나눌 수 있는 키?3.
반복계의 장점
•
실행 계획의 안전성
◦
아래와 같은 단순한 SQL 구문은 실행 계획이 변동 될 위험이 거의 없다. 그렇기에 운용 중에 실행 계획이 바뀌어서 느려지는 현상이 일어나지 않는다.
◦
실행 계획 변동에서 가장 문제가 되는 부분이 결합 알고리즘의 변경인데, 반복계 SQL 구문은 매우 단순해서 내부에서 결합을 사용하지 않아도 되기 때문에 이런 문제로부터 자유롭다. → 반면, 포장계는 SQL 구문이 복잡한 만큼 실행 계획의 변동 가능성이 크다.
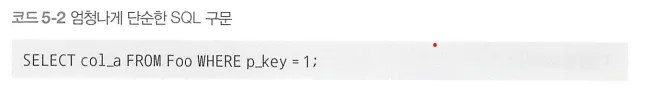

•
예상 처리 시간의 정밀도

◦
상대적으로 반복계 SQL은 정밀하게 예상 처리 시간을 계산할 수 있다.
◦
반면, 포장계는 실행 계획에 따라 성능이 전혀 달라지므로 예상 처리 시간을 사전에 계산하기 매우 힘들다.
•
트랜잭션 제어가 편리
◦
반복계는 트랜젝션의 정밀도를 미세하게 제어할 수 있다.
→ 특정 반복 횟수마다 갱신 처리를 하는 경우, 중간에 오류가 발생했다면, 해당 지점 근처에서 다시 처리를 실행하면 된다. 반면, 포장계는 갱신 처리 중간에 오류가 발생한 경우 처음부터 다시 처리하기 시작해야 한다.
결론
•
성능만이 아니라 기능적인 관점까지 고려한다면 반복계도 장점이 있으니, 상황에 맞춰서 반복계와 포장계 중 선택하는 것이 좋다.
16강. SQL에서는 반복을 어떻게 표현할까?
1.
포인트는 CASE식과 윈도우 함수
•
SQL에서 반복을 대신하는 수단은 CASE 식과 윈도우 함수이다.
•
위에서 살펴본 코드 5-1의 반복계 SQL을 포장계 SQL로 작성한 코드


SIGN 함수
•
ROWS BETWEEN ~ AND 구는 대상 범위의 레코드를 지정하는 구문
◦
EX. ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING은 1개 전 레코드부터 1전 레코드까지 (즉, 직전 한개의 레코드만) 비교 대상 레코드를 지정하겠다는 의미
◦
이를 상관 서브쿼리로 하려면 더욱 SQL 구문이 더욱 복잡해진다.
상관 서브쿼리
2.
최대 반복 횟수가 정해진 경우
•
인접한 우편 번호를 찾는 예시
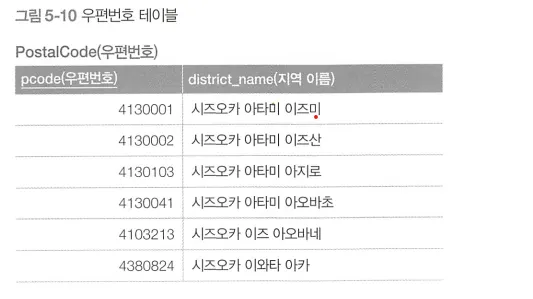
→ 우편번호의 오른쪽부터 한 자리씩 검사하며 가장 가까운 우편번호를 찾는다.
•
반복계 SQL을 사용하지 않고 CASE식을 사용하여 순위를 매기는 방식 사용

→ 우편번호가 7 자리이기에 총 반복계 SQL을 사용하면 7번의 반복이 이루어져야 하지만, 이를 7회의 CASE 식 분기로 변환했다.
→ CASE 식의 WHEN구는 조건을 검사하다가, 일치하면 이후의 WHEN구는 평가하지 않고 리턴한다.
하지만, 최악의 경우 WHEN구의 끝까지 검사해야 된다면, 반복계 SQL과 결국 같은 횟수만큼 반복되는 것 아닌가?•
실행 계획
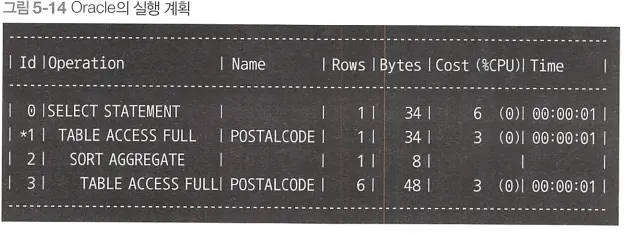
◦
2번의 테이블 접근이 발생한다.
→ 코드 5-7에서 순위의 최솟값을 서브쿼리에서 찾기 때문
•
윈도우 함수를 사용하여 테이블 접근을 1회로 줄이는 방법

◦
서브쿼리 내에서 SELECT 구를 사용하지 않았기에 테이블 풀 스캔이 1회로 줄어든다.
•
실행 계획
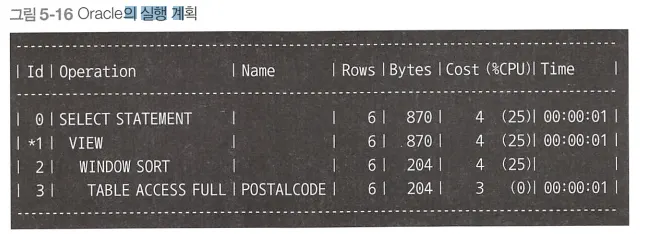
◦
테이블 풀 스캔이 1회로 감소
◦
하지만, 윈도우 함수가 사용되므로 정렬이 추가로 발생함에 따른 비용이 추가된다.
→ 그럼에도 테이블 크기가 크다면, 테이블 풀 스캔을 줄이는 것의 효과가 더 크다.
3.
반복 횟수가 정해지지 않은 경우
•
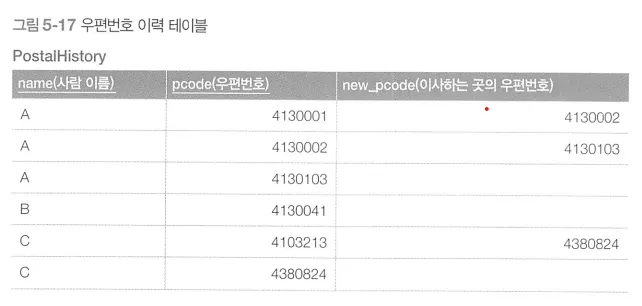
인접 리스트 모델
1.
현재 주소를 등록할 때는 현재 주소를 등록하고 이사 하는 곳의 우편번호는 null로 하여 레코드를 등록한다.
2.
이사하는 시점에는 이사하는 곳의 우편번호를 변경한다.
3.
이사한 후에는 다시 이사한 곳의 주소를 현재 주소로, 이사하는 곳의 우편번호는 null로 하여 새로운 레코드를 등록한다.
◦
위의 방식처럼 우편번호를 키로 삼아서 데이터를 연결한 것을 포인터 체인이라고 부르며, 계층 구조를 표현하는 고전적인 방법이다.
◦
포인터 체인을 사용하는 테이블 형식을 ‘인접 리스트 모델’이라고 부른다.
•
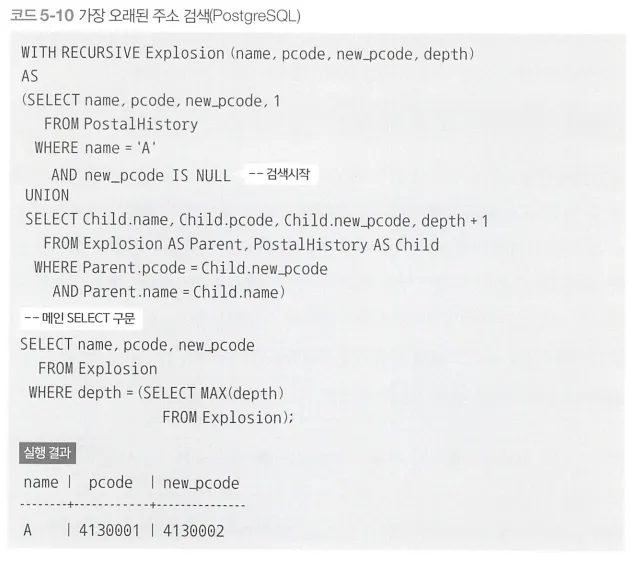
재귀 공통 테이블 식
◦
재귀 공통 테이블식인 Explosion은 A에 대해서 new_pcode가 null인 레코드(현재 주소)부터 시작해서 포인터 체인을 타고 올라가 과거의 주소를 모두 찾는다.
◦
이때 가장 오래된 주소는 재귀 수준이 가장 깊은 레코드이다. → 시작 레코드의 depth는 1로 시작하기 때문
◦
실행 계획

◦
worktable scan on explosion parent는 재귀를 도는 explosion 뷰에 여러번 접근하므로 일시적인 테이블로 만들었다는 것을 나타낸다.
◦
위의 실행 계획은 일시 테이블과 ‘idx_new_pcode’라는 인덱스를 사용해 nested loop를 수행하므로 꽤 효율적이라고 할 수 있다.
•
중첩 집합 모델
◦
재귀 공통 테이블은 표준 SQL에 있는 내용이지만, 아직 구현되지 않았거나 실행 계획이 최적화되지 않은 DBMS가 있기에 이를 대체하기 위해 중첩 집합 모델을 사용할 수 있다.
◦
SQL에서 계층 구조를 나타내는 방법
▪
인접 리스트 모델
▪
중첩 집합 모델
▪
경로 열거 모델
◦
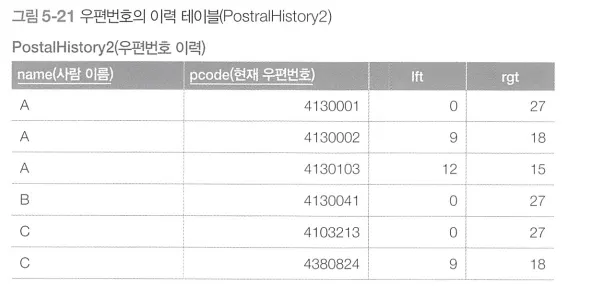
중첩 집합 모델은 각 레코드의 데이터를 집합으로 보고, 계층 구조를 집합의 중첩 관계로 나타내는 방식이다.
▪
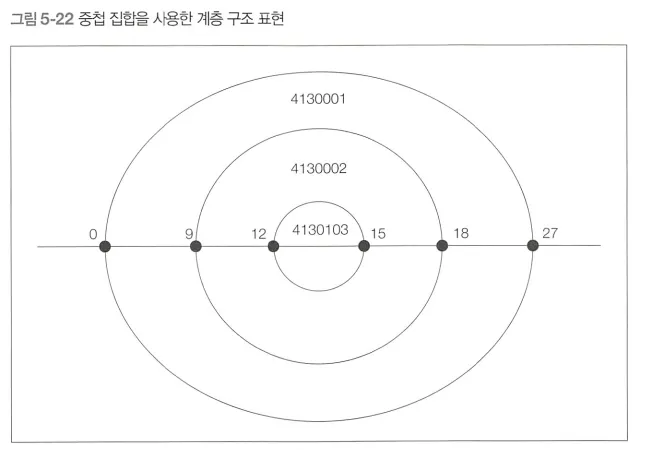
중첩 집합 모델에서는 우편번호 필드의 데이터를 수치선 상에 존재하는 원으로 생각한다.
▪
ltf와 rgt는 원의 왼쪽 끝과 오른쪽 끝에 위치하는 좌표를 나타낸다.
▪
이사할 때마다 새로운 주소의 우편번호가 이전 주소의 우편번호 안에 포함되는 형태로 추가된다.
▪
이러한 중첩 모델의 테이블에서는 가장 오래된 주소를 찾기 위해서 가장 바깥쪽에 있는 원을 찾으면 된다.
◦
중첩 집합 방식을 사용하면 엔티티 구조의 관점으로 문제를 해결할 수 있다. → ?
17강. 바이어스의 공죄
•
RDB의 성능을 최대치로 끌어내고 싶다면, 집향 지향적인 사고방식을 가져야 한다.