



SQL과 집합(Set)
SQL은 집합지향(set-oriented) 방식으로 조작하는 구현이 많다. 기본적인 데이터 단위인 레코드에서 레코드 집합을 이용하도록 사고를 지향해보자.
집약(Aggregate)
집약의 의미는 여러 레코드를 한 레코드로 압축하는 것이다.
예제 DDL
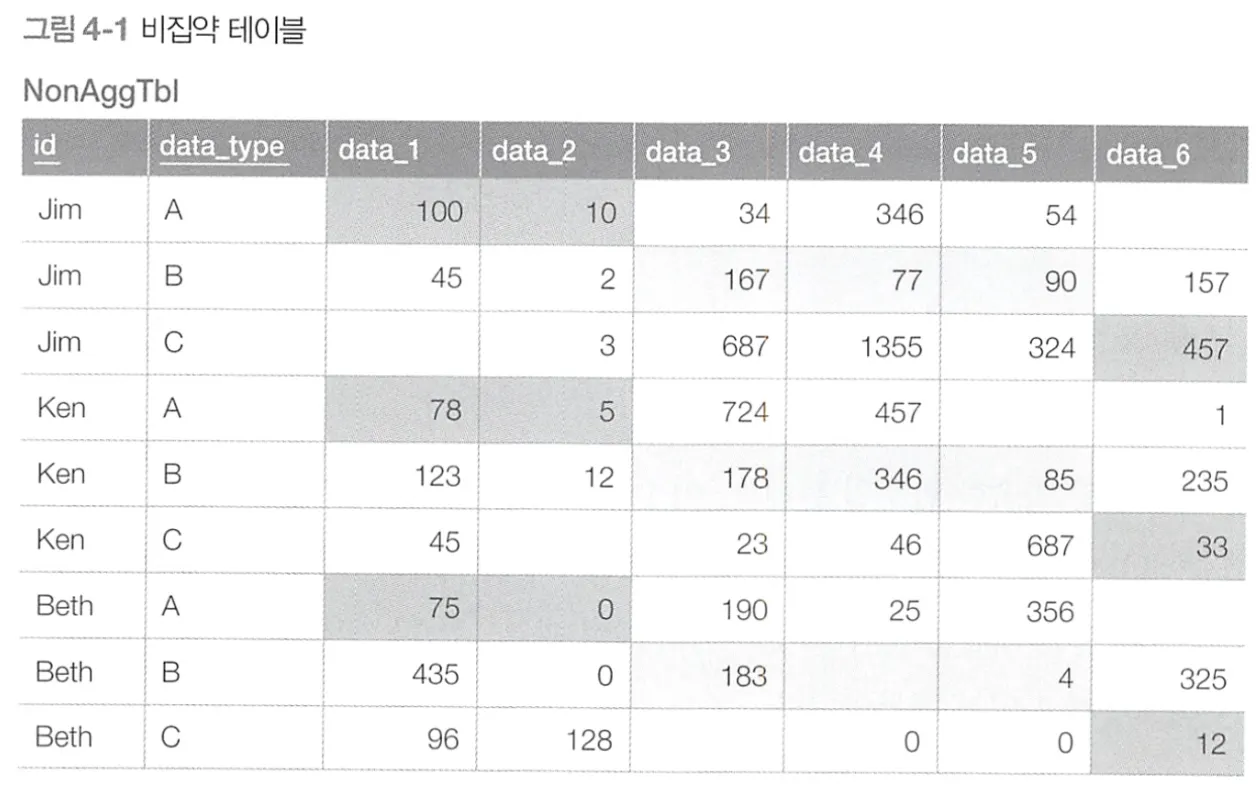
예제에 나타나는 케이스와 같이, 하나의 정보(예제에서는 사람 이름)에 대해 접근할 때에, 여러 레코드가 선택되는 비집약 데이터의 처리에서는 한 개의 레코드로 해당 값을 처리하는 것이 좋을 것이다.
…
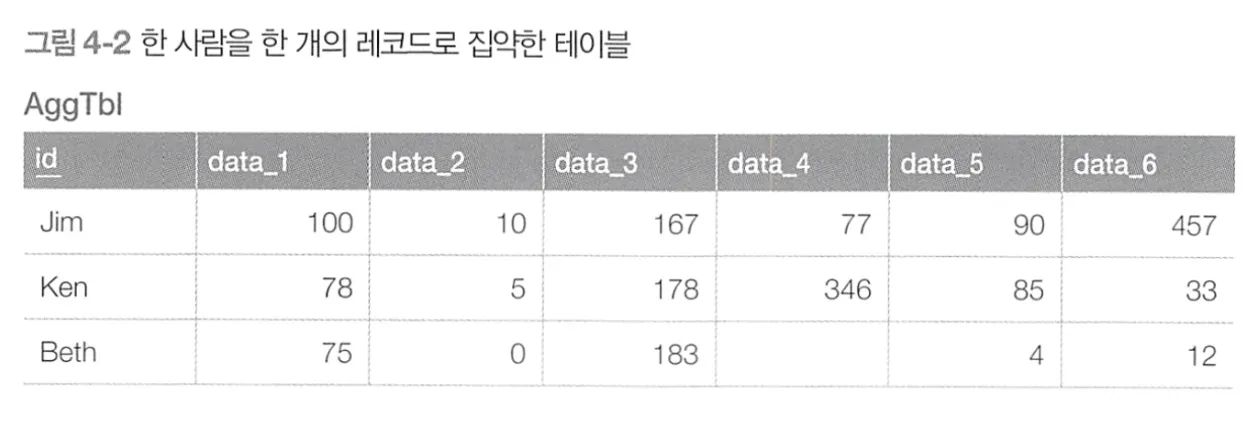
→ 예제의 CSV와 같이 data_type이 Enum처럼 동작해서 data_n이 차별적으로 나뉠 때에, 오히려 한 사람(id)을 기준으로 데이터를 집약하는 방식이 더 나을 것이다. (하지만 사용하는 주체가 data_type에 따른 컬럼이 어떻게 구별되는지 항상 알고 있어야한다는 단점이 있을 것 같다)
→ 특정 상태(Enum)을 통해 해당 객체가 갖는 역할을 분리하려고 하는 안티패턴을 이미 이펙티브 자바에서도 봤었음.
CASE식과 GROUP BY를 응용하기
위의 비집약 데이터를 집약 데이터로 변환하기 위해 어떻게 SQL을 사용해야할까?

위 쿼리는 오류가 발생한다. 왜?
GROUP BY 구로 집약하여 SELECT할 때, 뒤에 올 수 있는 것은 상수, 집약 키, 집약 함수다.
→ CASE에 data_type을 지정하면 하나의 레코드만 선택된다(집약이 아니라는 뜻) - 귀찮더라도(원소가 한 개더라도) 집약 함수를 사용해서 작성해야한다. - 이전 강에서 우리가 살펴본 “왜 레코드가 한 개인데 MAX 씀?”이라는 의문은 집합과 요소를 혼동했기 때문인 것이었다.
→ 매개변수로 단일 객체를 받느냐, List<?>를 받느냐의 느낌같다.
실행계획
EXPLAIN FORMAT=JSON SELECT id,
MAX(CASE WHEN data_type = 'A' THEN data_1 ELSE NULL END) AS data_1,
MAX(CASE WHEN data_type = 'A' THEN data_2 ELSE NULL END) AS data_2,
MAX(CASE WHEN data_type = 'B' THEN data_3 ELSE NULL END) AS data_3,
MAX(CASE WHEN data_type = 'B' THEN data_4 ELSE NULL END) AS data_4,
MAX(CASE WHEN data_type = 'B' THEN data_5 ELSE NULL END) AS data_5,
MAX(CASE WHEN data_type = 'C' THEN data_6 ELSE NULL END) AS data_6
FROM NonAggTable
GROUP BY id;
/*------------------------------------------*/
{
"query_block": {
"select_id": 1,
"cost": 0.018049998,
"filesort": {
"sort_key": "NonAggTable.`id`",
"temporary_table": {
"nested_loop": [
{
"table": {
"table_name": "NonAggTable",
"access_type": "ALL",
"loops": 1,
"rows": 9,
"cost": 0.0123218,
"filtered": 100
}
}
]
}
}
}
}
SQL
복사
1.
"query_block": 이 JSON 실행 계획은 하나의 쿼리 블록에 대한 정보를 제공한다.
2.
"select_id": 쿼리 블록의 고유 ID
3.
"cost": 이 쿼리 블록의 예상 비용
4.
"filesort": 이 쿼리 블록에는 파일 정렬 작업이 포함된다.
→ ORDER BY 구에 대한 처리가 인덱스를 사용하지 못할 때 조회된 레코드를 정렬용 메모리 버퍼에 복사해 퀵 or 힙소트로 정렬한다고 한다. - 워킹메모리일 것 같다.
•
"sort_key": 파일 정렬을 수행하는 기준 컬럼 "temporary_table": 파일 정렬을 위해 임시 테이블을 사용한다.
◦
"nested_loop": 임시 테이블을 생성하고 여기에 대한 접근 방법. 이 경우에는 하나의 테이블 액세스 방법만 나타난다.
▪
"table": 임시 테이블에 접근하기 위한 테이블 정보.
•
"table_name": 테이블의 이름은 "NonAggTable".
•
"access_type": 테이블에 대한 액세스 방법은 "ALL". 이는 테이블의 모든 레코드에 액세스하는 것을 의미한다. - 풀스캔
•
"loops": 루프 횟수는 1이다.
•
"rows": 예상되는 행 수는 9다.
•
"cost": 이 테이블 액세스 작업의 비용은 약 0.0123218.
•
"filtered": 결과 집합에서 필터링된 비율은 100%. 이는 모든 행이 결과 집합에 포함될 것임을 나타낸다.
…
책에서 나타나는 DBMS에서는 Hash 정렬을 이용하는 것으로 나타났지만, MariaDB의 경우에는 해시 정렬이 아닌 Nested Loop을 사용하는 것으로 나타났다.
하나로 합치기
예제 DDL
SELECT product_id
from PriceByAge
GROUP BY product_id
HAVING SUM(high_age - low_age + 1) = 101;
SQL
복사
비록 예제의 데이터에서 테이블의 제약조건만으로는 각 레코드의 구간이 중첩되지 않는다는 조건을 보장할 수는 없지만, 데이터 자체에서는 크게 문제가 없기 때문에 위와 같은 방법으로 해당하는 0~100(합 101)세까지 커버할 수 있는 product가 있는지 확인해볼 수 있다.
… 호텔 예제는 위와 다를바 없으므로 스킵했다.
자르기
GROUP BY는 뭉치기-나누기(집약-자르기)가 가능하다.
예제 DDL
SELECT SUBSTRING(name, 1, 1) AS first_alphabet, COUNT(*)
FROM Persons
GROUP BY SUBSTRING(name, 1, 1)
SQL
복사

위와 같이 GROUP BY를 이용하여 나뉜 부분 집합들을 Partition이라고 한다.
Partition은 중복되는 요소를 가지지 않는 부분 집합이다(서로 배타적이다).
SELECT에 GROUP BY에 사용되는 key를 포함하는 것이 포인트다.
실행계획
{
"query_block": {
"select_id": 1,
"cost": 0.018049998,
"filesort": {
"sort_key": "substr(Persons.`name`,1,1)",
"temporary_table": {
"nested_loop": [
{
"table": {
"table_name": "Persons",
"access_type": "ALL",
"loops": 1,
"rows": 9,
"cost": 0.0123218,
"filtered": 100
}
}
]
}
}
}
}
JSON
복사
역시나 풀스캔 Nested Loop을 사용한다.
집약 함수와 GROUP BY의 실행 계획은, 성능적인 측면에서 해시(또는
정렬)에 사용되는 워킹 메모리의 용량에 주의하라는 것 이외에 따로 할 말은 없다고 한다.
정리
•
기본적으로 SQL을 다룰 때에(혹은 데이터를 다룰 때에도) 단순한 레코드 하나가 아닌 묶음(Set)으로서 우선적으로 생각해보자.
•
고수가 되고 싶다면 GROUP BY와 CASE를 잘 써라.
•
DBMS별로 GROUP BY에 대한 실행계획이 다른데, MariaDB의 경우 Nested Loop와 filesort(인덱스가 없는 테이블이어서)를 이용하는 것을 볼 수 있었다.
→ 궁금해서 인덱스를 추가해서 실행계획을 찾아보았을 때에, 막상 인덱스를 사용할 수 없어서 filesort를 하는 것이 아닌 것 같다. - nested_loop의 프로퍼티에 using_index값이 true로 추가되는 것을 볼 수 있었음.