



서브쿼리가 일으키는 폐해
서브쿼리의 문제점
•
연산비용 추가
◦
실체적 데이터를 안가짐 → 서브쿼리에 접근 때마다 SELECT → 추가비용
▪
복잡할수록 증가
•
데이터 I/O 발생
◦
연산결과를 어딘가에 저장하다 보면 데이터량이 크면 TEMP 탈락 발생가능
•
최적화 불가능
◦
서브쿼리에는 옵티마이저가 쿼리를 해석하기 위한 정보 (메타정보) 없음
서브쿼리 의존증
•
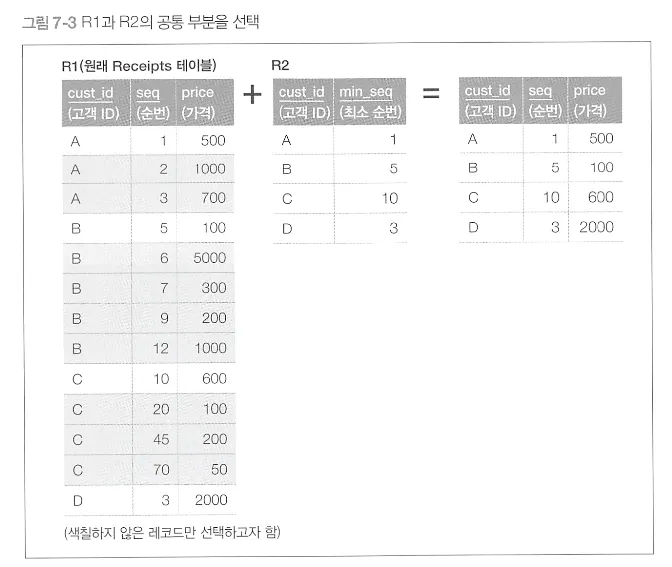
영수증 테이블 ⇒ 고객별 가장 오래된 구매기록을 찾기
◦
영수증엔 고객이 여러개 들어있고, 가격도 여러개
SELECT R1.cust_id,R1.seq,R1.price
FROM Receipts R1
INNER JOIN
(SELECT cust_id,MIN(seq) AS min_seq
FROM Receipts
GROUP BY cust_id) R2
ON R1.cust_id=R2.cust_id
AND R1.seq = R2.min_seq;
SQL
복사
•
코드 복잡
•
성능 문제
◦
서브쿼리 TEMP 에 확보 → 오버헤드
◦
제약정보(메타데이터 없음) 최적화 불능
◦
결합을 필요→실행계획 변동 리스크
◦
Receipts 테이블 스캔 2번
•
상관 서브쿼리는 답이 될 수 없다
SELECT cust_id, seq, price
FROM Receptis R1
WHERE seq = (SELECT MIN(seq) FROM Receipts R2 WHERE R1.cust_id = R2.cust_id);
SQL
복사
⇒ Receipts 테이블 접근 두번 필요 ( 테이블접근1회, 기본키 인덱스접근 1회)
•
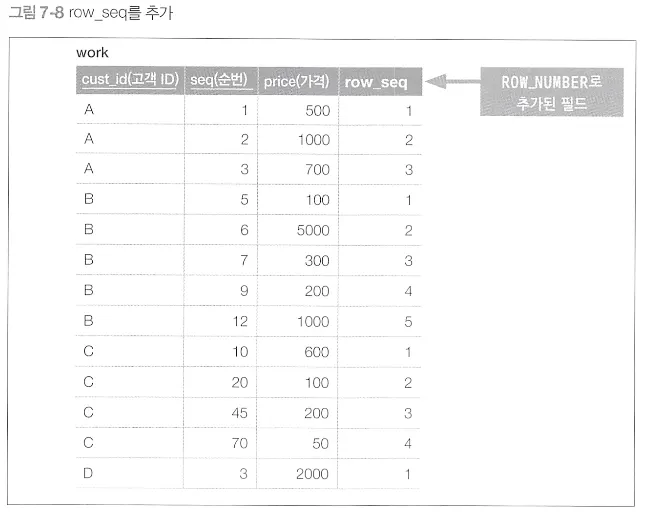
윈도우 함수로 결합 제거
SELECT cust_id, seq, price
FROM (SELECT cust_id, seq, price, ROW_NUMBER()
OVER (PARTITION BY cust_id ORDER BY seq) AS row_seq
FROM Receipts)
WORK
WHERE WORK.row_seq=1;
SQL
복사
•
row_seq 로 구매 이력에 번호를 붙이고 1번만 가져옴
•
윈도우 함수에서 정렬이 추가되긴했으나 앞에서도 MIN() 을 썼으므로 비용차이가 별로 없음
장기적 관점에서의 리스크 관리
•
결합을 사용하면
알고리즘 변동의 리스크
•
NestedLoops, Sort Merge, Hash 중 옵티마이저가 뭘 고를지 모른다
•
큰 테이블 결합일때 Sort Merge 혹은 Hash 사용되기 쉽다
•
어느 순간 테이블이 커지면서 알고리즘 변동 가능성
⇒ 하지만 우린 주로 Mysql 이라 Nested Loops만..
환경 요인에 의한 지연 리스크(인덱스, 메모리, 매개변수 등)
•
TEMP 탈락 발생시 ⇒ 작업 메모리 늘려주기(트레이드오프)
•
장기적 관점에서 리스크를 늘리는것
•
실행 계획이 단순할수록 성능이 안정적
•
엔지니어는 기능(결과)뿐만 아니라 비기능적 부분(성능)도 보장할 책임이 있다.
서브쿼리 의존증 응용편
서브쿼리는 정말 나쁠까?
YES
22강 서브쿼리 사용이 더 나은경우
•
회사테이블, 사업소테이블
•
1 : N
•
결합을 먼저 수행
SELECT C.co_cd, MAX(C.district), SUM(emp_nbr) AS sum_emp
FROM Companies C
INNER JOIN Shops s ON C.co_cd = S.co_cd
WHERE main_flg ='Y'
GROUP BY C.co_cd;
SQL
복사
•
집약을 먼저 수행
SELECT C.co_cd, C.district, sum_emp
FROM Companies C
INNER JOIN
(SELECT co_cd, SUM(emp_nbr) AS sum_emp FROM Shops WHERE main_flg = 'Y' GROUP BY co_cd) CSUM
ON C.co_cd. = CSUM.co_cd;
SQL
복사
•
결과는 같지만 결합대상 레코드 수가 다르다.
•
첫번째는 회사테이블 4 - 사업소테이블 10
•
두번째는 회사 테이블 4 - 사업소테이블(CSUM) 4
⇒ 데이터양이 많다고 쳤을때 당연 작은 레코드끼리 결합하는게 좋다.