
.gif&collectionId=dcb50d88-6307-4897-975e-13c151621a8a)
스트림이란
•
기존 Java에서는 컬렉션 데이터를 처리하려면 for문이나 foreach 루프문을 사용하면서 컬렉션 내 요소들을 하나씩 다루어야 했다. 만약 반복문 내에서 복잡한 처리가 필요하거나 컬렉션의 크기가 커지면, 루프문의 사용으로 인해 성능이 저하되는 문제가 발생했다.
// 빨간색 사과 필터링
List<Apple> redApples = forEach(appleList, (Apple apple) -> apple.getColor().equals("RED"));
// 무게 순서대로 정렬
redApples.sort(Comparator.comparing(Apple::getWeight));
// 사과 고유번호 출력
List<Integer> redHeavyAppleUid = new ArrayList<>();
for (Apple apple : redApples)
redHeavyAppleUid.add(apple.getUidNum());
Java
복사
스트림을 사용하지 않을 때
•
Java 8부터 이런 문제를 해결하기 위해 소스에서 추출된 연속된 요소들에 접근하여 데이터 처리 연산을 정의할 수 있는 스트림(stream)을 도입했다.
List<Integer> redHeavyAppleUid = appleList.stream()
.filter(apple -> apple.getColor().equals("RED")) // 빨간색 사과 필터링
.sorted(Comparator.comparing(Apple::getWeight)) // 무게 순서대로 정렬
.map(Apple::getUidNum).collect(Collectors.toList()); // 사과 고유번호 출력
Java
복사
스트림을 사용할 때
•
스트림은 데이터의 흐름을 의미하며, 컬렉션이나 배열, I/O 자원 등의 소스로부터 제공되는 API를 통해 데이터를 소비한다. 그 과정에서 주어지는 소스의 데이터 순서를 그대로 유지하여 정렬된 순서를 보장할 수 있다.
•
또한 스트림에서는 paralleStream 메서드를 제공하여, 별도의 멀티스레드 구현없이도 간편하게 병렬처리가 가능해진다.
List<Integer> redHeavyAppleUid = appleList.parallelStream() // 병렬 처리
.filter(apple -> apple.getColor().equals("RED")) // 빨간색 사과 필터링
.sorted(Comparator.comparing(Apple::getWeight)) // 무게 순서대로 정렬
.map(Apple::getUidNum).collect(Collectors.toList()); // 사과 고유번호 출력
Java
복사
•
위 코드는 stream() 메서드를 통해 appleList라는 소스(Source)에서 연속된 데이터들을 얻어 스트림을 생성한다. 해당 스트림에 Stream API인 filter, sorted, map, collect의 데이터 처리 연산을 적용하고 처리 결과를 반환한다.
•
IntStream, DoubleStream, LongStream 등의 형태를 기본형 스트림으로 제공하여, 오토박싱 등의 불필요한 과정을 생략할 수 있고 더 효율적으로 사용할 수 있다. 추가적으로 .sum()이나 .average()와 같은 Stream<T>에는 없는 더 유용한 메서드를 제공하기도 한다.
•
이처럼 Java 8에서는 스트림을 도입하여 더 간결하고 가독성과 유연성이 좋은 코드를 작성할 수 있다.
스트림의 특징
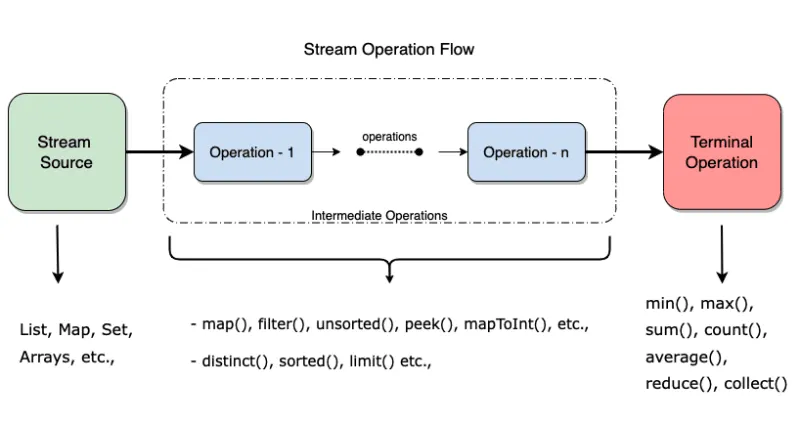
•
스트림의 데이터 처리
◦
스트림은 말그대로 데이터의 흐름일 뿐 데이터를 담고 있는 저장소나 컬렉션이 아니다.
◦
스트림을 통해 데이터를 가공하는 과정에서 원본 데이터 소스를 Read-Only로 가져오며 변경하지 않는다.
◦
스트림은 Iterator처럼 일회용으로 사용되며, 스트림을 다시 사용하려면 새로 생성해야 한다.
•
파이프 라이닝
◦
스트림 연산들을 서로 연결하여, 큰 파이프 라인을 구성할 수 있도록 스트림 자신을 반환한다.
◦
스트림 자신을 반환하기 때문에 laziness나 short-circuiting과 같은 최적화 방식을 적용할 수 있다.
laziness
최종연산이 실행되기 전까지, 중간연산을 실행하지 않고 대기
short-circuiting
여러 개의 조건이 중첩된 상황에서 값이 결정되면, 더 이상 불필요한 실행을 하지 않도록 해서 실행 속도를 증가시키는 기법
◦
스트림 파이프 라이닝에는 중간 연산자와 최종 연산자가 있다.
List<String> highCaloriesFoodName = foodList.stream()
.filter(food -> food.getCalories() > 400)
.map(Food::getName)
.limit(3)
.collect(Collectors.toList());
System.out.println(highCaloriesFoodName);
Java
복사
◦
위 코드에서 filter, map, limit은 중간 연산자로 파이프 라인을 형성할 수 있도록 스트림 자신을 반환한다. collect는 최종 연산자로 파이프라인을 처리하여 결과를 반환한다.
◦
연산 파이프라인은 데이터베이스의 SQL 질의문과 비슷하다.
•
내부 반복
◦
반복자(Iterator)를 통해 명시적으로 순회하는 컬렉션과는 다르게, 스트림 자체에서 내부 반복 기능을 제공한다.
◦
스트림의 내부 반복 기능에 람다식으로 함수를 넘겨주어 별도의 반복문 없이 내부 순회와 처리 로직을 적용할 수 있다.
스트림의 연산
•
위에서도 언급되어 있듯이, 스트림의 연산들은 중간 연산과 최종 연산으로 구분할 수 있다. 데이터 소스를 중간 연산을 통해 가공하고 최종 연산으로 결과를 저장한다.
•
중간 연산
◦
스트림의 파이프 라이닝을 위해 스트림 자신을 반환하여 여러 중간 연산을 수행할 수 있는 연산들이다.
◦
최적화를 위해 Laziness가 적용되어 있어, 최종 연산을 만나기 전까지 아무 연산도 수행하지 않고 기다린다.
•
최종 연산
◦
파이프라이닝을 통해 연산된 결과를 반환하는 연산을 말한다.
◦
List나 Integer, void 등 다양한 형태로 결과를 받을 수 있다.
스트림과 컬렉션의 차이점
•
스트림과 컬렉션은 둘 다 연속된 요소를 가지는 자료구조 인터페이스를 제공한다. 둘의 가장 큰 차이점은 내 컴퓨터에 저장된 동영상 파일과 인터넷에서 동영상 스트리밍의 차이정도로 생각할 수 있다.
•
데이터 계산 시점
◦
컬렉션의 자료구조가 포함하는 모든 요소들을 메모리에 저장하는 방식이다. 그렇기 때문에 컬렉션의 모든 요소는 컬렉션에 추가되기 전에 계산되어야 한다.
◦
스트림에서는 요청할 때, 사용자가 필요로 하는 일부분만 계산하는 고정된 자료구조이다.
•
반복의 일회성
◦
컬렉션의 경우에는 같은 소스에 대해 여러 번 반복해서 처리할 수 있다.
◦
스트림에서는 소비(Consume)의 개념을 사용하기 때문에, 소비한 요소에 대해 접근할 수 없어 여러 번 반복해서 처리할 수 없다.
Consume<List<Food>> c = (foodList) -> {
for (food : foodList) System.out.println(food);
}
c.accept(foodList); // 정상
c.accept(foodList); // 정상
Stream<Food> s = foodList.stream();
s.forEach(System.out::println); // 정상
s.forEach(System.out::println); // IlleagalStateException 발생
Java
복사
•
반복 구조
◦
컬렉션은 사용자가 반복문을 직접 명시하는 외부반복 개념이다.
◦
스트림은 라이브러리를 사용하는 내부반복 개념이다.
List<String> foodNameList = new ArrayList<>();
for (Food food : foodList){
foodNameList.add(food.getName());
}
List<String> foodNameList = foodList.stream()
.map(Food::getName)
.collect(Collectors.toList());
Java
복사
스트림 생성하기
•
배열 스트림
String[] array = new Integer[]{1, 2, 3};
Stream<Integer> stream1 = Arrays.stream(array);
Stream<Integer> stream2 = Arrays.stream(array, 1, 3); // index 1 포함, 3 제외
Java
복사
•
컬렉션 스트림
List<Integer> list = Arrays.asList(1, 2, 3);
Stream<Integer> stream = list.stream();
Java
복사
•
스트림 builder
Stream<Integer> stream = Stream<Integer>builder()
.add(1)
.add(2)
.add(3)
.build();
Java
복사
•
스트림 generator
// generate 시그니처 : Supplier 함수형 인터페이스를 매개변수로 받는다.
// public static<T> Stream<T> generate(Supplier<T> s) { ... }
// Hello 문자열을 무한대로 생성하는 스트림
Stream<String> stream = Stream.generate(() -> "Hello").limit(5);
Java
복사
•
스트림 Iterator
// 100부터 10씩 증가하는 숫자를 생성하는 iterate
Stream<Integer> stream = Stream.iterate(100, n -> n + 10).limit(5);
Java
복사
•
빈 스트림
Stream<Integer> stream = Stream.empty();
Java
복사
•
기본형 스트림
IntStream intStream = IntStream.range(1, 10);
IntStream boxedIntStream = IntStream.range(1, 10).boxed(); // 오토박싱
LongStream longStream = LongStream.range(1, 100);
LongStream boxedLongStream = LongStream.range(1, 100).boxed(); // 오토박싱
Java
복사
•
문자열 스트림
IntStream stream1 = "Hello, world".chars(); // (72, 101, 108, 108, 111, 44, 32, 87, 111, 114, 108, 100)
Stream<String> stream2 = Pattern.compile(",").splitAsStream("Apple,Banana,Melon");
Java
복사
•
파일 스트림
Stream<String> stream = Files.lines(Path.get("test.txt"), Charset.forName("UTF-8"));
Java
복사
•
스트림 연결
Stream<Integer> stream1 = Stream.of(1, 2, 3);
Stream<Integer> stream2 = Stream.of(4, 5, 6);
Stream<Integer> stream = Stream.concat(stream1, stream2); // 1, 2, 3, 4, 5, 6
Java
복사
스트림 가공하기 - 중간 연산
•
Filter
◦
데이터를 필터링하는 스트림으로, boolean을 반환하는 람다식을 넣어 true면 다음 스트림을 진행하고 false면 데이터를 버린다.
// 스트림의 Food 요소들 중 calories가 400을 넘는 값만 필터링
foodList.stream().filter(food -> food.getCalories() > 400)
Java
복사
•
Map, FlatMap
◦
스트림을 새로운 형태의 데이터 요소를 가진 스트림으로 변환한다.
◦
FlatMap의 경우 중첩 구조를 제거하고 다음 스트림으로 진행한다.
// Food 컬렉션에서 생성한 스트림으로부터 food 이름들의 스트림으로 변환
foodList.stream().map(Food::getName())
Java
복사
•
limit, skip
◦
스트림 데이터 중 특정 부분의 데이터들만 선택하여 다음 스트림으로 진행한다.
// foodList 스트림 중 앞에서 10번째부터 10개의 데이터만 선택
foodList.stream().skip(10).limit(10)
Java
복사
•
sorted
◦
스트림의 요소들을 정렬하고 다음 스트림으로 진행한다.
foodList.stream().sorted()
foodList.stream().sorted(Comparator.comparingInt(Food::getCalories))
Java
복사
데이터 가공하기 - 최종 연산
•
anyMatch, allMatch, nonMatch
◦
스트림의 데이터들 중 특정 조건을 만족하는 데이터가 있는지 확인한다.
// foodList 스트림 중 Apple 문자열을 이름에 포함하고 있는 데이터가 있는지 확인(true/false 반환)
foodList.stream().anyMatch(food -> food.getName().contains("Apple"))
Java
복사
•
findFirst, findAny
◦
스트림을 순회하며 조건에 맞는 값 중 가장 먼저 찾은 하나를 찾아온다.
foodList.stream().findFirst(food -> food.getName().contains("Apple"))
foodList.stream().findAny(food -> food.getName().contains("Apple"))
Java
복사
◦
findFirst와 findAny의 경우 스트림을 직렬처리하는 경우에는 차이가 없지만, 병렬로 처리하는 경우 findFirst는 가장 앞쪽에 있는 요소를 반환하고 findAny는 멀티 스레드 중 가장 먼저 찾은 요소를 반환한다. findAny로 병렬 처리를 하는 경우 뒤쪽의 요소가 반환될 수도 있다.
•
count, sum, min, max
◦
각 목적에 맞는 수학적 연산을 한 후 그 결과를 반환한다.
•
reduce
◦
스트림 요소를 줄여가면서 하나씩 누적 연산을 수행 후 결과를 반환한다.
// 1부터 10까지의 숫자들을 하나씩 누적해서 더한다.
Integer sum = Stream.of(1, 2, 3)
.reduce((total, y) -> total + y);
System.out.println("sum: " + s); //sum: 6
// 초기값을 지정해 줄 수 있다.
Integer sum = Stream.of(1, 2, 3)
.reduce(10, Integer::sum);
System.out.println("sum: " + sum); //sum: 16
// 세 번째 인자로 병렬처리 결과를 합치는 로직을 받을 수 있다.
Integer sum = ArrayList.asList(1, 2, 3)
.parallelStream()
.reduce(10, Integer::sum, (a, b) -> a + b); // sum: 36
// 여기서 36이 되는 이유는 병렬처리로 10 + 1 / 10 + 2 / 10 + 3 을 각각 계산 후 값들을 더했기 때문이다.
Java
복사
•
collect
◦
스트림의 요소들을 원하는 자료형으로 변환하여 저장
foodList.stream().map(Food::getName()).collect(Collectors.toSet()); // Set으로 변환
foodList.stream().map(Food::getName()).collect(Collectors.toList()); // List로 변환
foodList.stream().map(Food::getName()).collect(Collectors.joining(", ")); // 하나의 String으로 join
foodList.stream().collect(Collectors.averagingInt(Food::getCalories)); // 각 요소의 Calories의 평균값을 반환
foodList.stream().collect(Collectors.summingInt(Food::getCalories)); // 각 요소의 Calories의 합을 반환
Java
복사