



/
14강 반복문 의존증
SQL 에는 반복문이 없다
15강 반복계의 공포
반복계의 소개
•
이전 데이터가 없는 경우 NULL
•
이전 데이터보다 매출이 올랐을경우 +
•
이전 데이터보다 매출이 내렸을경우 -
•
이전 데이터와 매출이 동일한 경우 =
OPEN c_sales;
LOOP
/* 레코드를 때치해서 변수에 대입 */
fetch C=sales into rec_sales
/* 레코드가 없다면 반복을 종료 */
exit when c_sales%notfound;
IF (c_company = rec_sales.company) THEN
/* 직전 리코드가 같은 회사의 레코드일때 */
/* 직전 레코드와 매상을 비교*/
IF (i_pre_sale < rec_sales.sale) THEN
c_var :='+';
ELSEIF (i_pre_sale > rec_sales.sale) THEN
c_var := '-';
ELSE
c_var :='=';
END IF;
ELSE
c_var := NULL;
END IF;
SQL
복사
•
특정 연도의 레코드와 직전 연도의 레코드를 비교하는 로직을 반복 == 한번에 한 레코드 적 사고방식
•
SQL 문장의 단순함
•
반복계가 가지는 장점 중 하나가 SQL 처리를 단순화 할 수 있다는 점
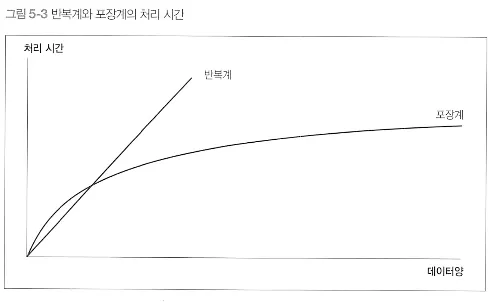
반복계의 단점
•
성능이 구리다
•
포장계로 구현한 코드에 성능적으로 이길 수 없음 (레코드가 적을땐 차이 별로없음)
•
많아질수록 차이가 벌어짐
•
처리 횟수 *한 회에 걸리는 시간 ⇒ 처리 대상 레코드 수에 비례
•
포장계의 경우 인덱스를 사용한 접근, 실행 계획 변동이없다면? 완만한 커브를 그린다
SQL 실행 오버헤드
1.
SQL 구문 네트워크 전송
2.
DB 연결
3.
SQL 구문파스
4.
SQL 구문의 실행 계획 생성 또는 평가
5.
결과 집합을 네트워크로 전송
⇒ 3번,4번은 은 작은 SQL 여러번을 실행할때 오버헤드가 높아짐
한번에 큰거 처리하는게 빠를 수 밖에 없다
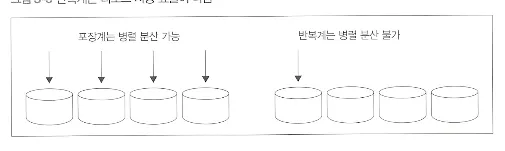
병렬 분산이 힘들다
•
대부분 DB 서버 저장소는 RAID 디스크라서 I/O 를 부하 분산할 수 있다.
•
반복계 SQL 구문은 대부분 단순해서 1회의 SQL 구문이 접근하는 데이터양이 적다. ⇒ I/O 병렬화가 힘들다
⇒ 소일거리를 개많이 해서, 나눠주는게 힘들다
데이터베이스 벤더의 진화로 인한 혜택을 받기 힘들다
•
DB의 진화 == 대규모 데이터를 다루는 복잡한 SQL 구문을 빠르게 하려는 시도다.
•
단순한 SQL 구문을 빠르게 만드는건 안중에도 없다.
⇒ 실제 반복계의 처리가 느려서 문제가 될때는 대충 스케일업 한다.
물리 리소스가 병목이 걸리는게 아니라면 스케일업을 해도 의미가 없을 수 있다.
(물론 포장계의 SQL이 충분히 튜닝 되어 있어야 한다.)
반복계를 빠르게 만드는 방법은?
•
반복계를 포장계로 다시 작성
◦
현실적으로 어려움
•
각각의 SQL을 빠르게 수정
◦
더이상 쪼갤게 없다.
•
다중화 처리
◦
처리를 나눌 수 있는 키가 병확히 정해져있다면 가능
•
수백개 정도만 반복한다면 반복계라도 성능이 괜찮다.
•
수백 또는 수천만 번의 반복이라면 생각을 해봐야한다.
반복계의 장점
•
실행 계획의 안정성
◦
너무 간단해서 실행 계획에 변동 위험이 거의 없다.
◦
옵티마이저가 계획을 바꾸지 안흔ㄴ다.
◦
SQL 구문 내부에서 결합을 사용하지 않아도 된다는점이 크게 작용
처리시간의 정밀도
•
예상 처리시간의 정밀도가 높다.
트렌젝션 제어가 편리
•
트렌젝션의 정밀도를 미세하게 제어 가능
•
중간에 오류가 발생했을때, 중간지점에서 다시 처리가능
•
포장계의 경우 한번에 다 실행되므로 이런 제어가 불가능
16강 SQL 에서는 반복을 어떻게 표현할까?
포인트는 CASE 식과 윈도우 함수
•
IF-THEN- ELSE
•
CASE - 윈도우함수
⇒ CASE + 윈도우 함수로 포장계로 바꿀 수 있다.
•
서브쿼리를 통해 스캔 횟수를 줄일 수 있다.
•
반복 횟수가 정해지지 않은경우
◦
인접리스트 모델과 재귀처리로 찾을 수 있다
WITH RECURSIVE Explosion (name,pcode,new_pcode, depth)
AS
(SELECT name, pcode, new_pcode, 1
FROM PostalHistory
WHERE name = 'A'
AND new_pcode IS NULL -- 검색 시작
UNION
SELECT Child.name, Child,pcode, Child.new_pcode, depth+1
FROM Explosion AS Parent, PostalHistory As Child
WHERE Parent.pcode =Child.new_pcode
AND Parent.name = Child.name)
-- 메인 SELECT 구문
SELECT name, pcode, new_pcode
FROM Explosion
WHERE depth = (SELECT MAX(depth) FROM Explosion);
SQL
복사
◦
실행계획
▪
WorkTable : Explosion 뷰에 여러번 접근하므로 일시 테이블로 만든다
◦
재귀 공통 테이블은 비교적 최근에 만들어진 기능으로, 아직 없거나 최적화되지 않은 DBMS 라면 대체수단들 있다
•
SQL 의 계층 구조를 나타내는 방법
◦
인접 리스트모델
◦
중첩 집합 모델
◦
경로 열거 모델
17강 편향 공죄
꼭 반복계가 안좋은건 아닌데… 장점과 단점을 고려해서 잘 골라 쓰자