



18강. 기능적 관점으로 구분하는 결합의 종류
•
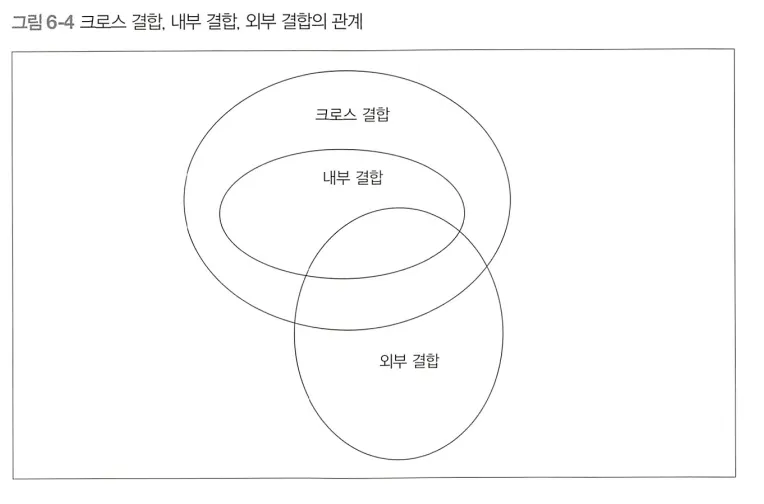
기능적인 관점의 분류 (서로 배타적) → 결합 후 생성되는 결과를 기준으로 분류
◦
크로스 결합
◦
내부 결합
◦
외부 결합
•
등가 결합 / 비등가 결합
◦
결합 조건으로 등호를 사용 / 부등호를 사용
•
자연 결합
◦
결합 조건을 따로 기술하지 않고, 암묵적으로 같은 이름의 필드가 등호로 결합
◦
필드 이름이 다르거나 자료형이 다른 경우 적용 불가

◦
자연 결합은 내부 결합으로 표현 가능

1.
크로스 결합 - 모든 결합의 모체
•
크로스 결합은 = 데카르트 곱
→ 여러 테이블들의 레코드에서 가능한 모든 조합을 구하는 연산
•
비용이 매우 많이 드는 연산 → 실무에서 거의 사용 x
•
실수로 사용한 크로스 결합
◦
결합 조건을 지정하지 않아서 다음과 같은 크로스 결합이 발생

→ ‘INNER JOIN’ 과 같은 표준 SQL 의 구문은 결합 조건이 없으면 구문 오류가 발생하기 때문에 실수를 미연에 방지할 수 있다.
2.
내부 결합
•
내부 결합의 결과 = 크로스 결합 결과의 일부
→ 내부는 “데카르트 곱의 부분 집합”이라는 의미

•
내부 결합은 상관 서브쿼리로 대체할 수 있다.

→ 하지만, 비용이 높다.
스칼라 서브쿼리
3.
외부 결합
•
외부 결합 ≠ 데카르트 곱의 부분 집합 (경우에 따라서는 ‘=’ 성립)
•
종류
◦
left outer join
◦
right outer join
◦
full join
•
왼쪽/오른쪽 외부 결합은 기능적으로 같다.
◦
마스터 테이블이 왼쪽에 적히는지, 오른쪽에 적히는지의 차이
◦
외부 결합은 마스터 테이블에만 존재하는 키가 있을 때는 해당 키를 결합 결과에 보존

4.
자기 결합 → 연산의 대상으로 무엇을 사용하는지에 따른 분류
•
같은 테이블(혹은 뷰)을 사용한 결합
•
논리적으로 같은 데이터를 가진 서로 다른 테이블을 결합하는 것으로 생각하면 편하다.
19강. 결합 알고리즘과 성능
•
옵티마이저가 선택 가능한 결합 알고리즘
◦
Nested Loops
◦
Hash
◦
Sort Merge
•
옵티마이저가 어떤 알고리즘을 선택할지는 데이터 크기 혹은 결합 키의 분산이라는 요인에 의존한다.
→ 결합 키의 분산?
1.
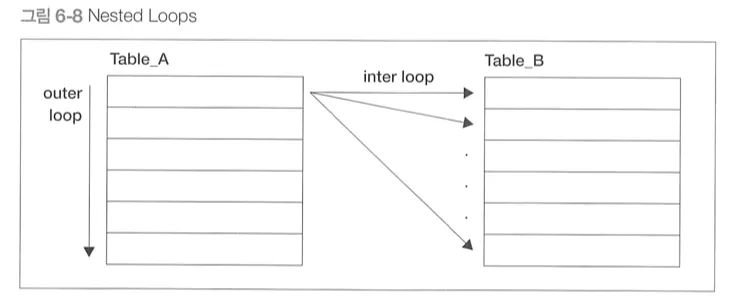
Nested Loops
•
SQL에서 결합은 한 번에 두 개의 테이블만 결합하므로 이중 반복과 같은 의미
•
작동 방식
a.
외부 테이블 A(혹은 구동 테이블)에서 레코드를 하나씩 반복해가며 스캔
b.
외부 테이블의 레코드 하나마다 내부 테이블(B)의 레코드를 하나씩 스캔 후 결합 조건에 맞는지 검사
c.
외부 테이블의 모든 레코드에 반복
•
특징
◦
실행 시간은 레코드 수에 비례
◦
한 번의 단계에서 처리하는 레코드 수가 적으므로 Hash 또는 Sort Merge에 비해 메모리 소비가 적다.
◦
모든 DBMS에서 지원
- (검색 조건으로 압축된)구동 테이블이 작을수록 Nested Loops의 성능이 좋아진다.
•
단점
◦
결합 키가 내부 테이블에 대해 유일하지 않은 경우( = 내부 테이블의 결합 키로 지정된 필드의 레코드가 유일하지 않은 경우?) 내부 테이블에 접근할 때 조건에 맞는 (히트되는) 레코드가 너무 많아서 성능이 생각보다 좋지 않을 수 있다.
→ 외부 테이블로 큰 테이블을 선택한다면, 내부테이블에서 항상 하나의 레코드에 접근하는 것이 보장되기 때문에 성능 비균등 문제로 인해 극단적으로 성능이 낮아지는 것을 막을 수 있다.
2.
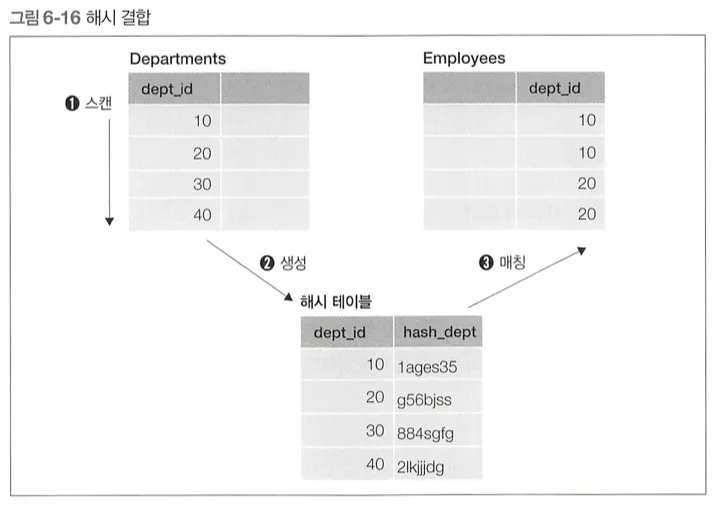
Hash
•
작동 방식
◦
우선 작은 테이블을 스캔하고, 결합 키에 해시 함수를 적용하여 해시값으로 변환
◦
이어서 큰 테이블을 스캔하고, 결합 키가 해시값에 존재하는지를 확인
•
해시 테이블은 DBMS의 워킹 메모리에 저장되므로 작은 테이블에서 만드는 것이 효율적이다.
•
특징
◦
해시 테이블을 만들기 때문에, Nested Loops에 비해 메모리를 크게 소모한다.
◦
TEMP 탈락이 발생하는 경우 지연이 발생한다.
◦
출력되는 해시값은 입력값의 순서를 알지 못하므로, 등치 결합에만 사용할 수 있다.(?)
•
해시는 Nested loops가 효율적으로 작동하지 않는 경우의 차선책이다.
3.
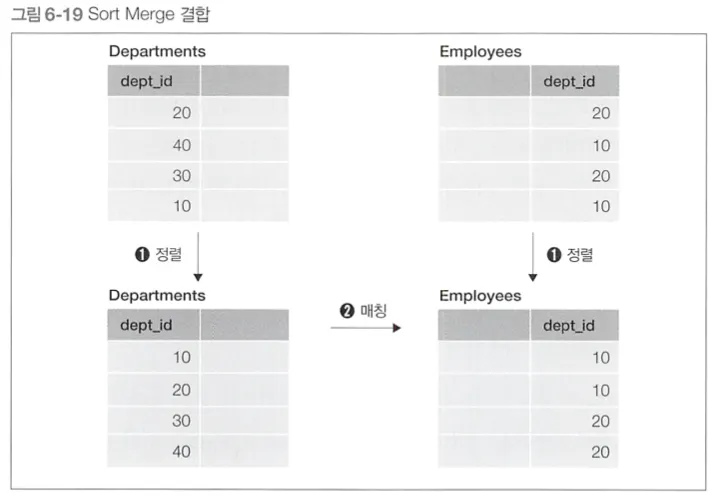
Sort Merge
•
작동 방식
◦
결합 대상 테이블들을 각각 결합 키로 정렬하고, 일치하는 결합 키를 찾으면 결합한다.
•
특징
◦
결합 대상 테이블을 모두 정렬해야 하므로 Nested Loops보다 많은 메모리를 소비한다. 경우에 따라서는 해시보다 많은 메모리를 사용한다.
◦
TEMP 탈락이 발생하면 지연이 발생할 수 있다.
◦
등치 결합과 부등호를 사용한 결합에도 사용할 수 있다. 부정 조건 결합에서는 사용할 수 없다.
•
Sort Merge는 테이블 정렬을 생략할 수 있는 경우에 고려해볼 만한 방법이다.
4.
의도하지 않은 크로스 결합
•
삼각 결합을 하는 경우 결합 조건이 존재하지 않는 테이블 간의 (의도하지 않은)크로스 결합이 일어날 수 있다.

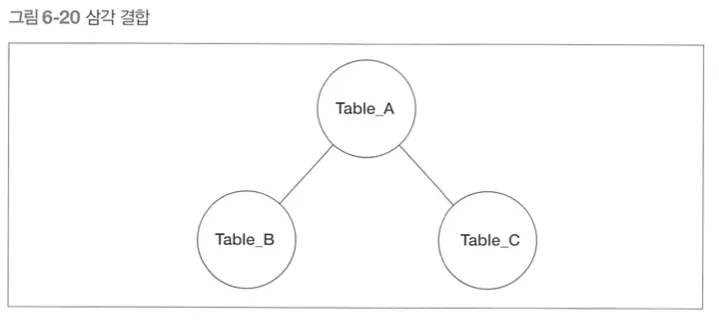
→ 위의 예시에서 테이블 B와 테이블 C는 서로 결합 조건이 없기 때문에 크로스 결합이 발생할 수 있다.
•
회피 방법
◦
서로 간의 결합 조건이 없는 테이블 사이에 불필요하지만 결합 결과에 영향을 미치지 않는 결합 조건을 추가해주면 된다.
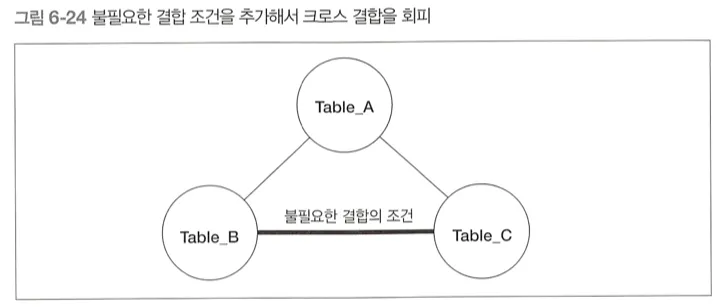
20강. 결합이 느리다면
•
결합 알고리즘 정리
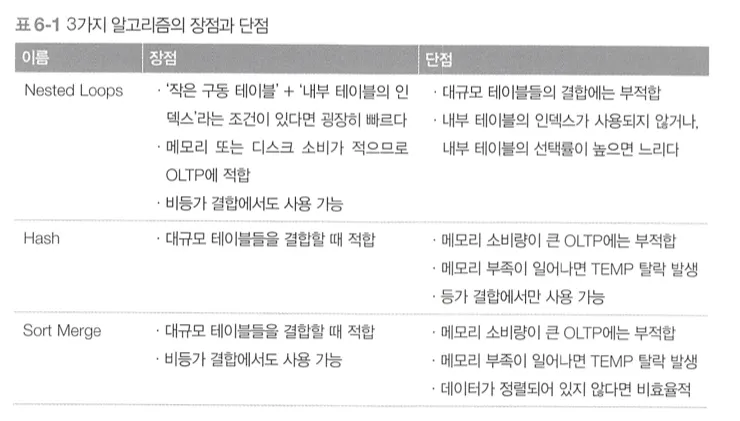
•
결합 대상 레코드수에 따른 최적의 결합 알고리즘

•
실행 계획 제어
◦
DBMS에 따라 실행 계획을 사용자가 원하는 만큼 제어할 수 있는 경우도 있다.
→ MySQL에는 결합 알고리즘이 Nested Loops 계열밖에 없으므로 선택의 여지가 없다…
정리
•
결합은 SQL 성능에서 중요한 부분을 차지한다.
•
결합 알고리즘은 기본적으로 Nested Loops를 사용하되, 테이블의 규모등에 따른 경우에 따라서 Hash와 Sort Merge를 고려한다.
•
결합은 실행 계획 변동이 일어나기 쉬운 연산이므로, 주의해서 사용해야 하며, 결합을 사용하지 않는 것이 최선이다(?) → 추후 다룸