



18강 - 기능적 관점으로 구분하는 결합의 종류
SQL에는 다양한 결합이 있다. 등가 결합과 비등가 결합은 결합 조건으로 등호(=)를 사용하는지, 이 이외의 부등호를 사용하는지에 따라 구분되고, 자연 결합은 자주 사용하는 내부 결합+등가 결합의 조합을 간단하게 작성하는 것이다.
웬만하면 자연 결합 대신 내부 결합을 사용하자.
이번 강에서는 기능적 관점으로 결합을 구분해 알아본다. 이는 배타적 분류로, 생성되는 결과의 형태에 따라 이름 지어진다: 크로스 결합, 내부 결합, 외부 결합
크로스 결합
2개 테이블의 레코드에서 가능한 모든 조합을 구하는 연산
실무에서 사용할 기회가 거의 없지만, 모든 결합의 모체이다.
예시 - 크로스 결합
가능한 모든 조합을 구해야 하는 경우가 거의 없고, 비용(실행 시간이 매우 길고 하드웨어 리소스도 많이 소비)이 매우 많이 들어서 실무에서 사용되지 않는다.
크로스 결합이 실무 쿼리에 쓰인다면 주로 실수로 결합 조건을 적지 않은 경우이다.
예시- WHERE 구로 결합 조건을 지정하지 않음
INNER JOIN은 결합 조건이 없으면 구문 오류를 발생시킨다. INNER JOIN을 사용해 실수를 미연에 방지하자.
내부 결합
두 테이블을 조인할 때, 두 테이블에 모두 지정한 열의 데이터가 있어야 한다.
가장 많이 사용되는 결합 중 하나로, 크로스 결합 결과의 일부(부분 집합)이다.
SELECT e.emp_id, e.emp_name, e.dept_id, d.dept_name
FROM "06_employees" e
INNER JOIN "06_departments" d
ON e.dept_id = d.dept_id;
SQL
복사
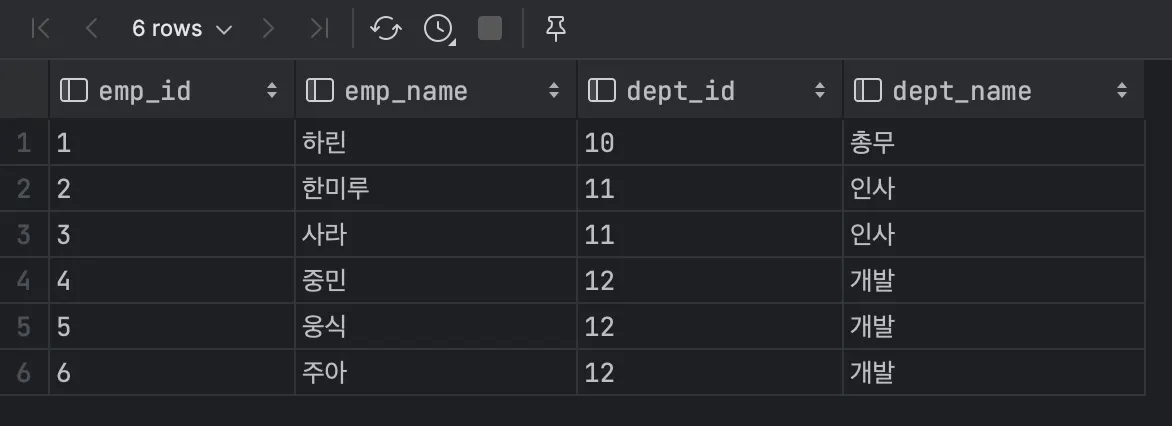
크로스 결합 결과의 일부이지만, 내부 결합을 구하는 알고리즘에 크로스 결합을 사용하진 않는다. 처음부터 결합 대상을 최대한 축소하는 형태이다.
•
상관 서브쿼리 VS 내부 결합
기본적으로는 내부 결합을 사용하는 것이 좋다. 상관 서브쿼리의 경우 결과 레코드 수만큼 상관 서브쿼리를 실행해 비용이 높아지기 때문이다.
내부 결합 예시 코드와 같은 기능을 하는 상관 서브쿼리 코드
외부 결합
두 테이블을 조인할 때, 마스터 테이블에만 데이터가 있어도 된다.
LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN 세 종류가 있다.
마스터가 되는 테이블을 왼쪽에 적으면 LEFT OUTER JOIN이고, 오른쪽에 적으면 RIGHT OUTER JOIN이다.
/* LEFT OUTER JOIN */
SELECT e.emp_id, e.emp_name, e.dept_id, d.dept_name
FROM "06_departments" d
LEFT OUTER JOIN "06_employees" e
ON e.dept_id = d.dept_id;
/* RIGHT OUTER JOIN */
SELECT e.emp_id, e.emp_name, e.dept_id, d.dept_name
FROM "06_employees" e
RIGHT OUTER JOIN "06_departments" d
ON e.dept_id = d.dept_id;
SQL
복사
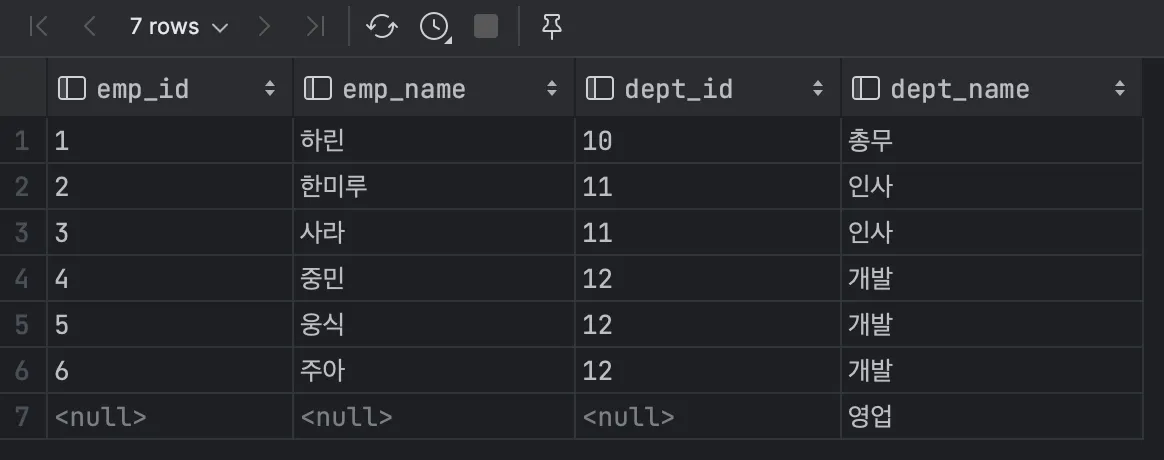
7번째 레코드와 같이, 마스터 테이블 쪽에만 존재하는 키가 있다면 해당 키를 제거하지 않고 결과에 보존한다. 이 레코드는 내부 결합과 크로스 결합의 결과에 없는 레코드이다.
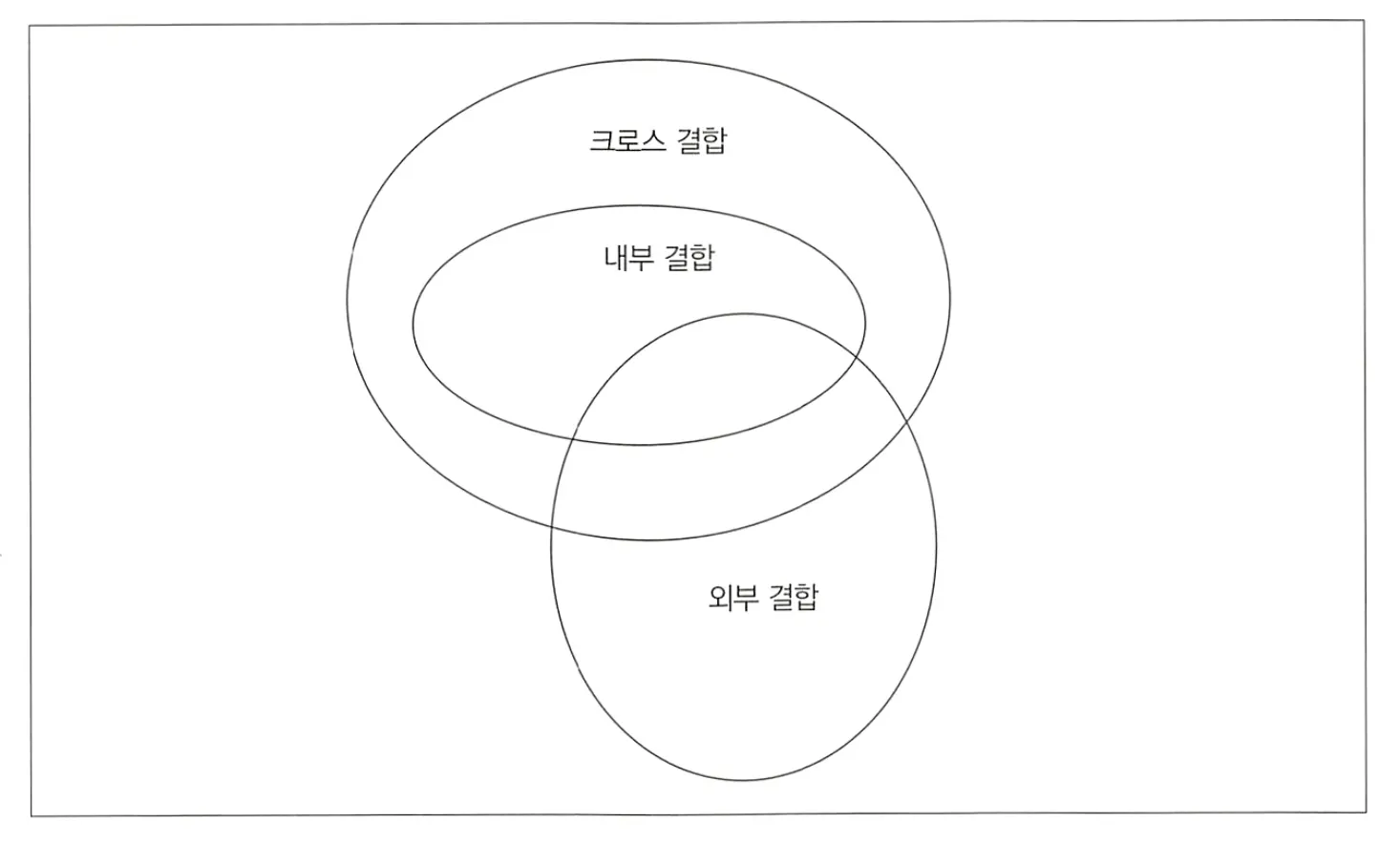
결합의 종류로 자기 결합을 다룰 필요가 없다고 생각한다.
같은 테이블(또는 같은 뷰)를 사용해 결합하는 것
SELECT d1.digit + (d2.digit * 10) AS seq
FROM "06_digits" d1
CROSS JOIN "06_digits" d2;
SQL
복사
일반적으로 같은 테이블에 별칭(d1, d2 등)을 붙여 다른 테이블인 것처럼 다룬다. 물리 레벨에서 보면 같은 테이블과 결합하는 것이지만, 논리 레벨에서 보면 서로 다른 두 개의 테이블을 결합하는 것과 같다. 또한, SELF JOIN을 수행하기 위한 별도의 문법이 있는 것도 아니다. 따라서 결합의 종류로 자기 결합을 따로 분류할 필요가 없다고 생각한다.
19강 - 결합 알고리즘과 성능
옵티마이저는 데이터 크기나 결합 키의 분산에 따라 알고리즘을 선택하는데 Nested Loops, Hash, Sort Merge 순으로 많이 쓰인다. DBMS 버전이 오르면 알고리즘이 바뀌기도 한다.
Nested Loops
중첩 반복을 사용하는 알고리즘. SQL에서의 결합은 한 번에 2개의 테이블만 결합하므로 이중 반복이다.
•
과정
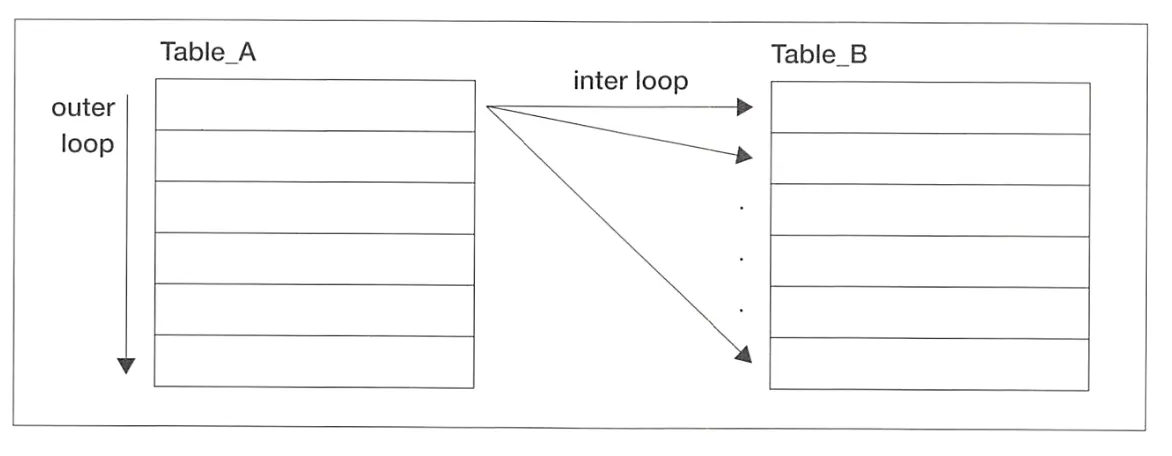
1.
결합 대상 테이블(driving table, outer table)인 Table_A에서 레코드를 하나씩 반복해가며 스캔함.
2.
driving table의 레코드 하나마다 inner table인 Table_B의 레코드를 하나씩 스캔해서 결합 조건에 맞으면 리턴.
3.
위의 과정을 driving table의 모든 레코드에 반복.
•
특징
◦
Table_A, Table_B의 결합 대상 레코드를 R(A), R(B)라고 하면 접근되는 레코드 수는 R(A) X R(B)로, 실행 시간이 레코드 수에 비례한다.
◦
한 번의 단계에서 처리하는 레코드 수가 적으므로 Hash 또는 Sort Merge 에 비해 메모리 소비가 적다.
◦
모든 DBMS에서 지원한다.
Nested Loops에서 어떤 테이블을 driving table로 사용하는지가 중요하다. 이중 반복의 외측과 내측의 반복 처리가 비대칭이기 때문에, driving table이 작을수록 Nested Loops의 성능이 좋아진다.
단, inner table의 결합 키 필드에 인덱스가 존재해야 한다. 해당 인덱스를 통해 DBMS는 inner table을 완전히 순환하지 않아도 된다.
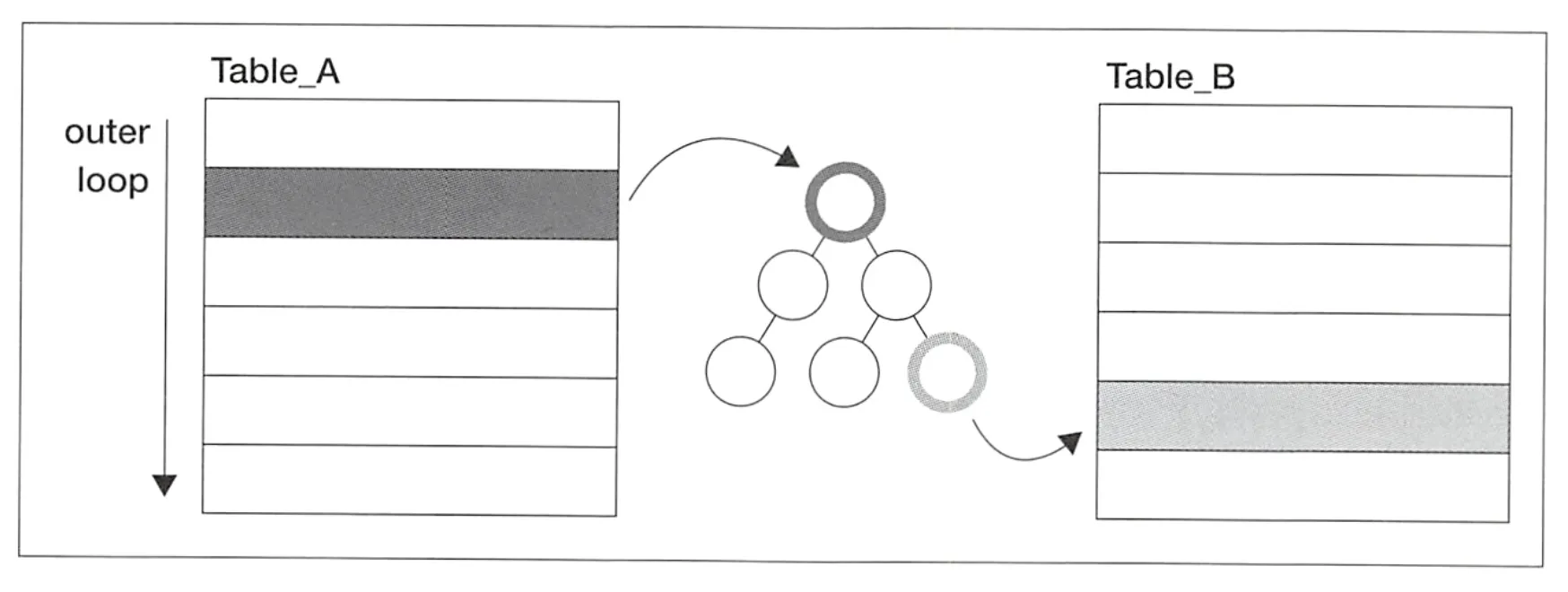
driving table의 레코드 한 개에 inner table의 레코드 한 개가 대응하고, 해당 레코드를 inner table의 인덱스를 사용해 반복 없이 찾을 수 있는 경우가 가장 이상적이다. 이 경우, 접근하는 레코드 수는 R(A) X 2이다.
INNER JOIN 예시 코드를 다시 실행해본 결과
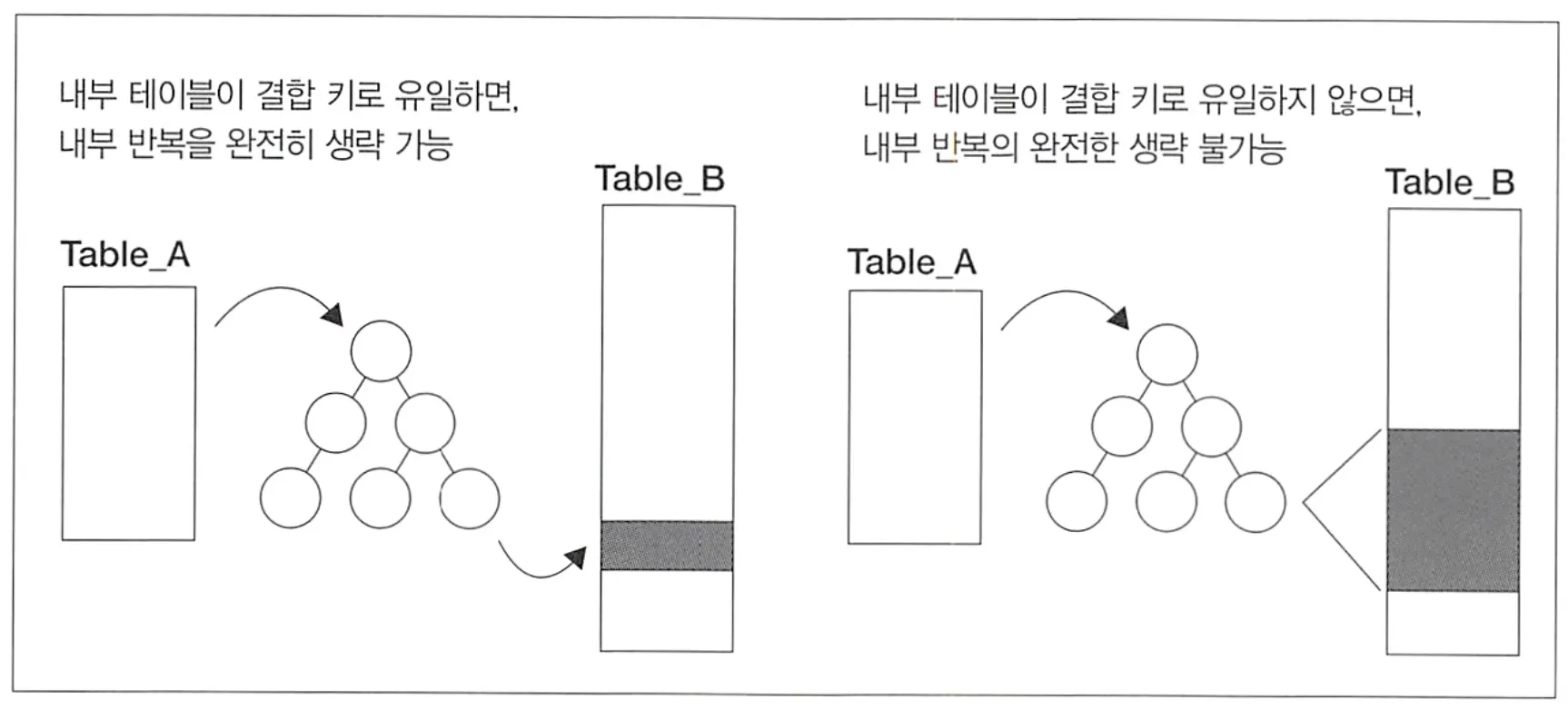
driving table을 작게하는 것보다 inner table을 크게 한다고 생각하자. inner table이 클수록 인덱스 사용으로 인한 반복 생략 효과가 커진다.
하지만, 결합 키가 inner table에 대해 유일하지 않아 히트되는 레코드가 너무 많은 경우, 반복이 일어나 지연이 발생한다는 단점이 있다.
•
균등하지 않은 성능에 대처하는 두 가지 방법
1.
driving table로 큰 테이블을 선택한다.
성능 비균등 문제를 해결해서, 극단적으로 성능이 저하되는 것을 막을 수 있다.
2.
Nested Loops 대신 Hash를 사용한다. Hash는 입력에 대해 어느 정도 유일성과 균일성을 가진 값을 출력하는 함수이다.
Hash
•
과정
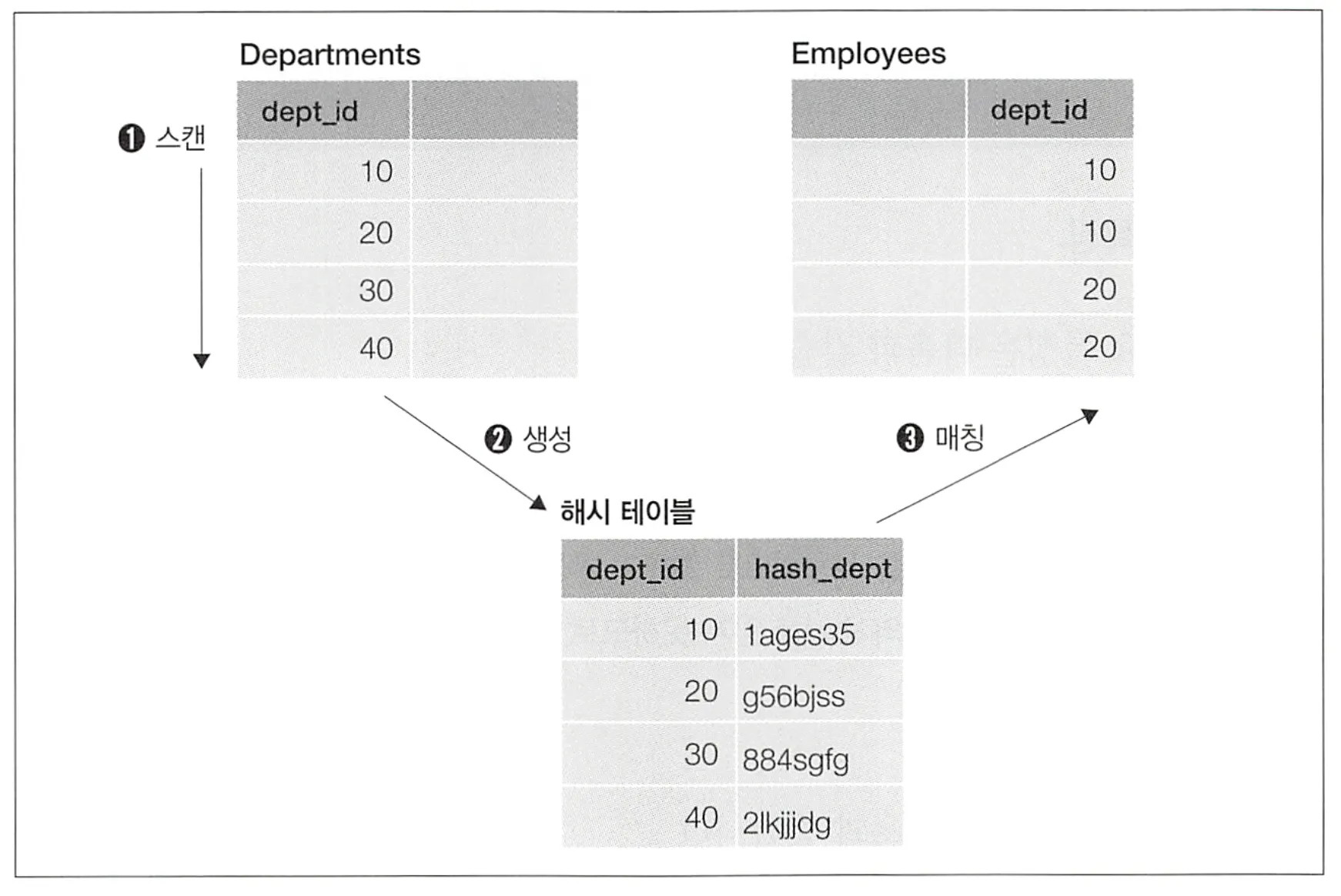
1.
작은 테이블을 스캔하고, 결합키에 해시 함수를 적용해서 해시값으로 변환한다. 이러한 해시들의 집합을 해시 테이블이라 한다.
2.
다른 테이블(큰 테이블)을 스캔하고, 결합 키가 해시값에 존재하는지를 확인하는 방법으로 결합을 수행한다.
•
특징
◦
해시 테이블을 추가로 만들어 하므로, Nested Loops보다 많은 메모리를 소모한다.
◦
메모리가 부족하면 저장소를 사용하므로 지연이 발생한다.
◦
출력되는 해시값은 입력값의 순서를 알지 못하므로, 등치 결합에만 사용할 수 있다.
•
Hash가 유용한 경우
◦
Nested Loops에서 적절한 driving table, 즉 상대적으로 충분히 작은 테이블이 존재하지 않는 경우
◦
inner table에서 히트되는 레코드 수가 너무 많은 경우
◦
inner table에 인덱스가 존재하지 않는 경우
Hash 결합은 양쪽 테이블의 레코드를 전부 읽어야 하므로, 테이블 풀 스캔이 사용되는 경우가 많다. 테이블 규모가 굉장히 크다면, 풀 스캔 소요 시간도 고려해야 한다.
Sort Merge
•
과정
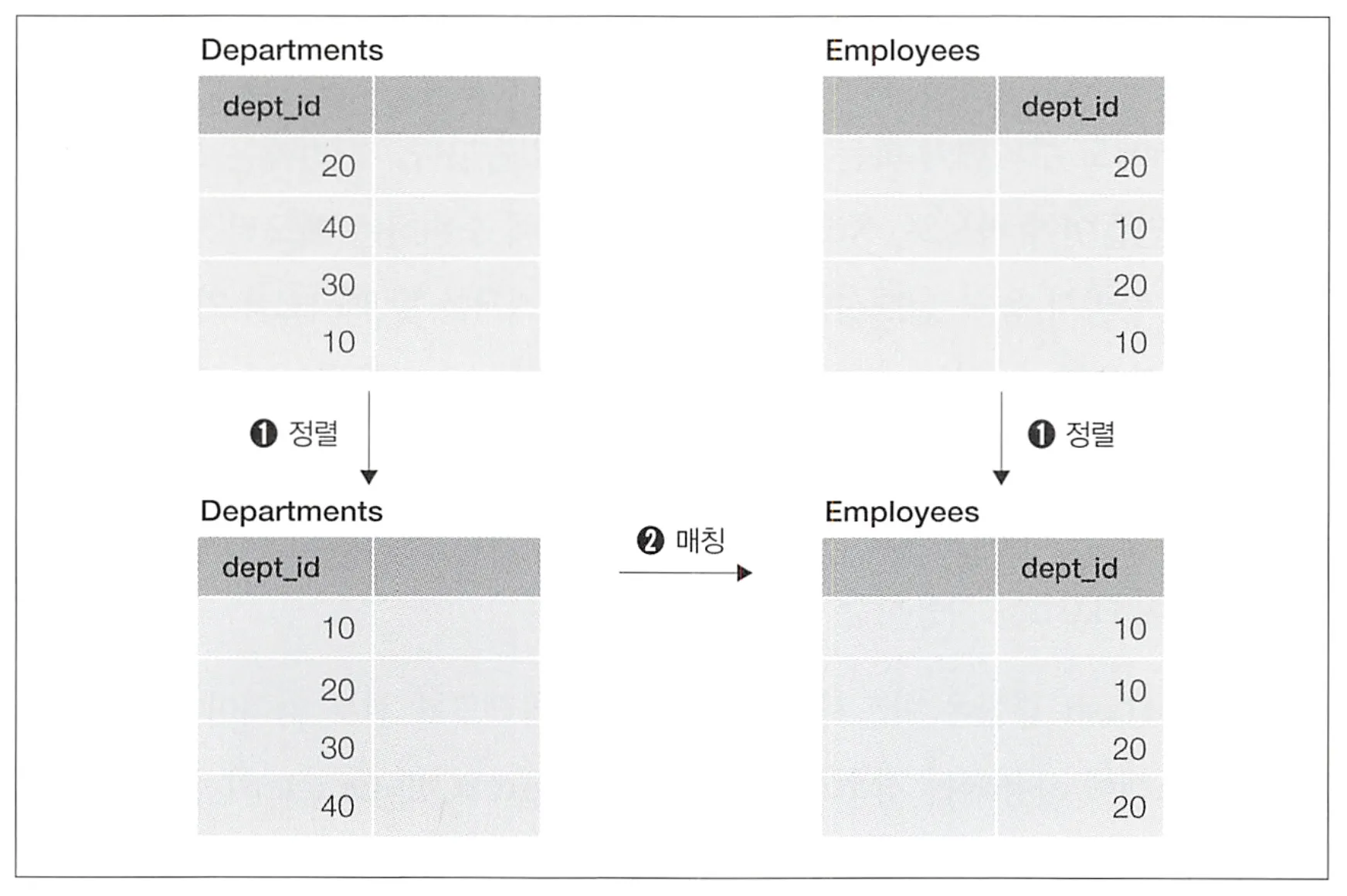
1.
결합 대상 테이블들을 각각 결합 키로 정렬한다.
2.
일치하는 결합 키를 찾으면 결합한다.
•
특징
◦
대상 테이블을 모두 정렬해야 하므로, Nested Loops보다 많은 메모리를 소모한다. Hash는 한쪽 테이블에 대해서만 해시 테이블을 만드므로 Hash보다 많은 메모리를 소비하기도 한다.
이는 TEMO 탈락이 발생하면 I/O 비용이 늘어나고 지연이 발생할 수 있게 된다. (Hash와 동일한 문제)
◦
동치 결합만 가능한 Hash와 달리, 부등호를 사용한 결합에도 사용할 수 있다.
부정 조건을 사용할 수 있는 결합 알고리즘은 Nested Loops뿐이다.
◦
원리적으로 테이블이 결합 키로 정렬되어 있다면 정렬을 생략할 수 있다.
◦
한쪽 테이블을 모두 스캔한 시점에 결합을 완료할 수 있다.
•
Sort Merge가 유효한 경우
Sort Merge 결합 자체에 걸리는 시간은 나쁘지 않지만, 테이블 정렬에 많은 시간과 리소스를 요구할 수 있다. 테이블 정렬을 생략할 수 있는 아주 예외적인 경우에만 Sort Merge를 고려해보자.
의도하지 않은 크로스 결합
•
삼각 결합
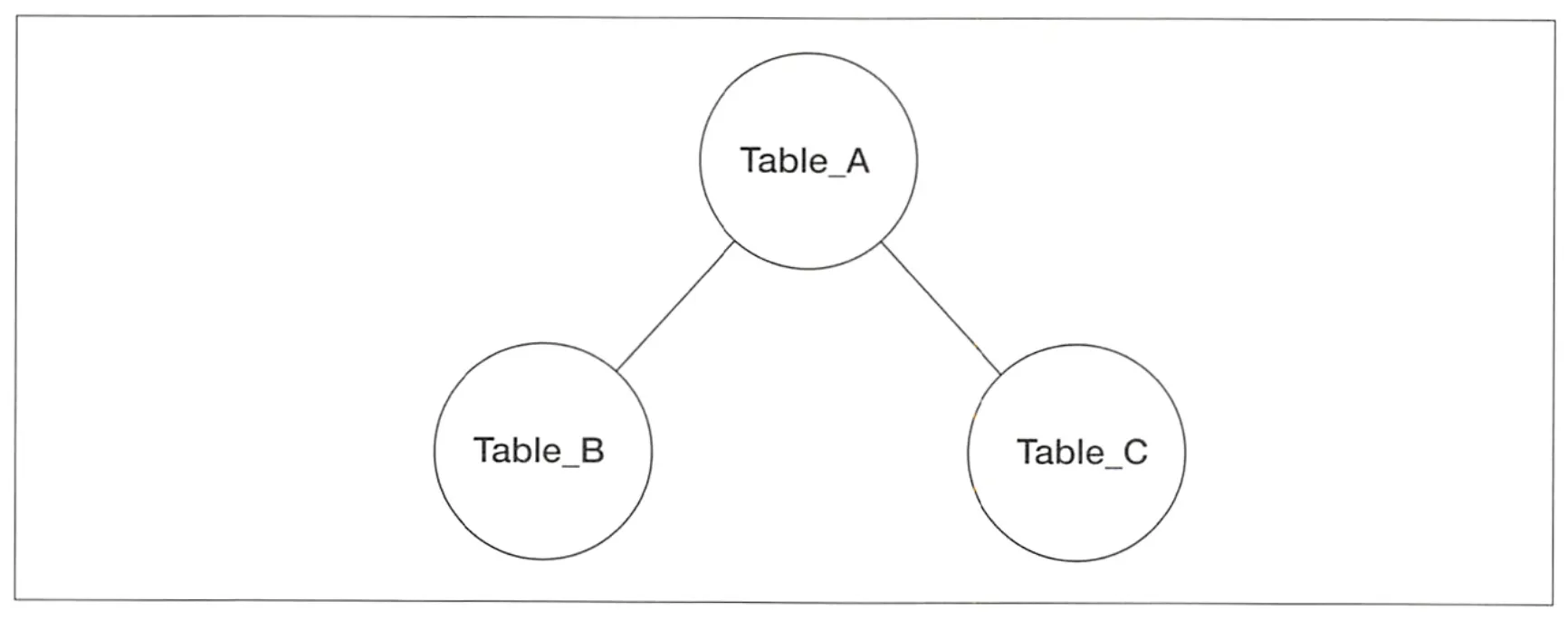
Table_B - Table_C에는 결합 조건이 존재하지 않는다.
예제 코드
삼각 결합의 경우 의도하지 않은 크로스 결합이 나타난다. Table_B와 Table_C의 크기를 작다고 평가했기 때문이라고 추측한다. Table_A에 2번 결합하는 것보다, 먼저 작은 테이블들(B, C)을 결합하고 결과를 다시 결합함으로써 1회로 횟수를 줄이는 것이 합리적이다.
비교적 큰 테이블끼리 결합할 때 크로스 결합이 선택되면 문제가 된다. 결합 조건이 존재하지 않는 테이블 사이에 불필요한 결합 조건을 추가해 크로스 결합을 회피할 수 있다.

20강 - 결합이 느리다면
3가지 결합 알고리즘의 장점과 단점
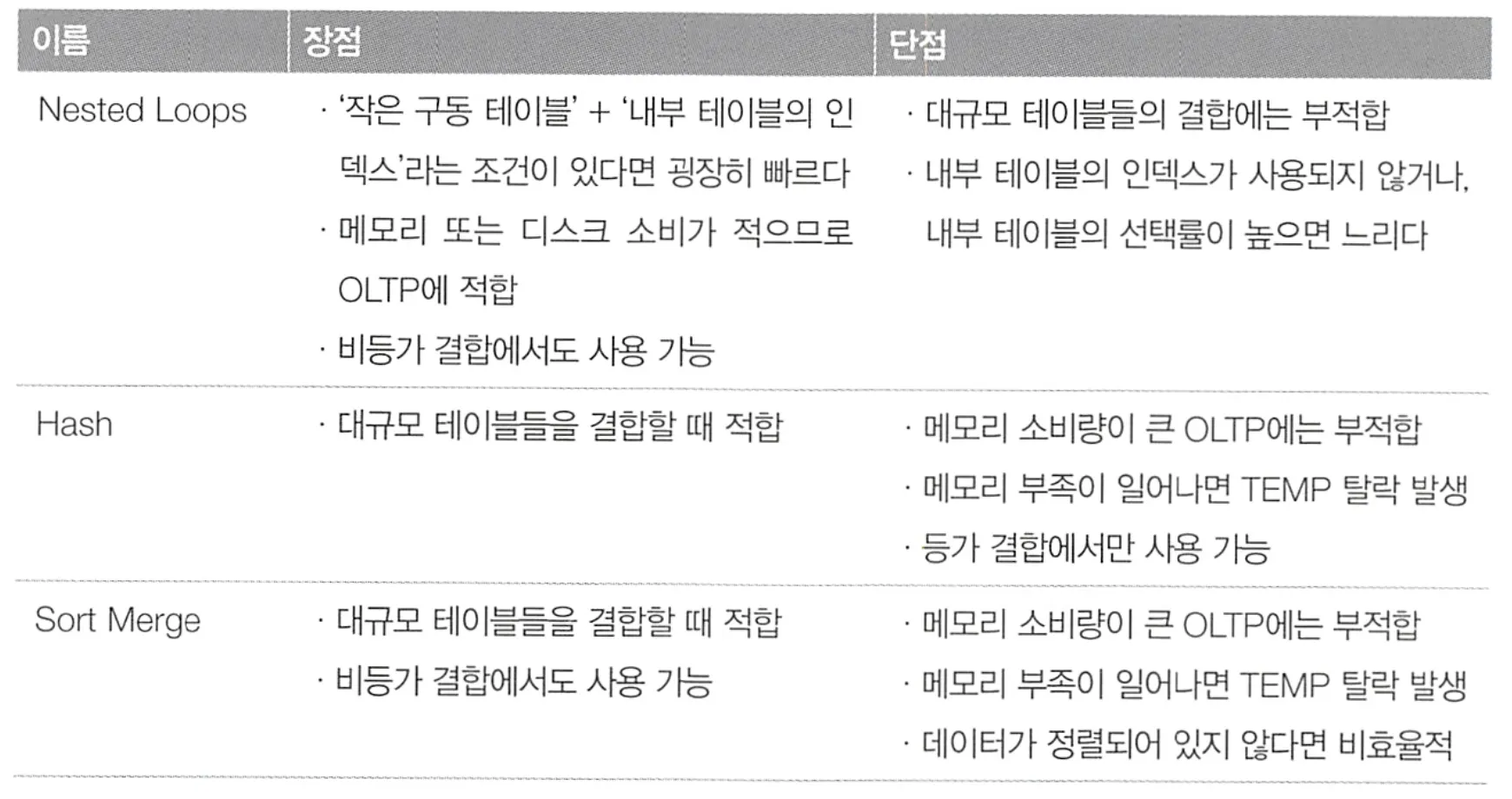
•
OLTP: 사용자 요구에 시스템이 곧바로 응답해야 하는 처리. 대부분의 웹 애플리케이션에서 웹 브라우저를 통해 접근하는 경우
최적의 결합 알고리즘 - 결합 대상 레코드 수 관점
•
소규모 - 소규모: 무관
•
소규모 - 대규모: 소규모 driving table + inner table의 결합키에 인덱스 생성하는 Nested Loops
•
대규모 - 대규모: Hash. 결합 키로 처음부터 정렬되어 있다면 Sort Merge.

일단 Nested Loops, 잘 안되면 Hash
실행 계획 제어
•
DBMS별로 실행 계획 제어 방법이 다르다. 힌트 구로 제어하거나, 결합 알고리즘 자체가 Nested Loops 밖에 없거나(MySQL), 실행 계획 제어가 불가능하다(DB2).
•
데이터양과 카디널리티는 DB를 운용하면서 계속 바뀌기 때문에 비용 기반에 따른 동적 실행 계획을 옵티마이저가 만드는 것이다. 사람의 판단으로 실행 계획을 제어하는 것에는 리스크가 따른다.
이처럼 결합은 알고리즘이 복잡해 실행 계획 변동이 일어나기 쉽다. SQL 성능 변동 위험을 줄이려면 되도록 결합을 피해야 한다. 결합을 대체하는 수단을 뒤에서 배울 것이다.