

개요
•
RDB는 데이터를 관계라는 형식으로 저장 - 구현 형태는 테이블(table)
•
SQL은 테이블을 검색해서 데이터를 찾거나 갱신할 때 사용하는 언어
6강. SELECT 구문
•
검색을 위해 사용하는 SQL 구문
•
SELECT 구문에는 데이터를 어떤 방법으로 선택할지 쓰여 있지 않다. → 사용자는 어떤 데이터가 필요한지만 기술하면 된다.
•
SELECT 구문은 입력과 출력이 table인 함수 - > 입력으로 들어오는 table은 변경하지 않기 때문에 읽기 전용 함수라고 볼 수 있다.
→ 입력과 출력이 모두 table이기 때문에 관계가 닫혀있다 → 폐쇄성
•
FROM 구
◦
데이터를 선택할 테이블을 지정
◦
상수를 선택하는 경우 테이블을 지정하지 않아도 됨 - 일부 DBMS에서는 동작 안되는 예외 존재
•
WHERE 구
◦
레코드(데이터)를 선택할 때 조건을 지정
◦
다양한 연산자를 통해 조건 지정 가능

◦
WHERE 구는 벤다이어그램으로 표현 가능하다.
◦
AND, OR로 여러 조건을 연결할 수 있다.
◦
IN으로 여러 조건을 연결한 OR 묶음을 한번에 표현 가능하다.

◦
NULL 레코드를 선택할 때는 “IS NULL”이라는 키워드를 사용해야 한다. → “레코드 = NULL”과 같은 표현은 X
→ NULL은 데이터 값이 아니므로, 데이터값에 적용하는 연산자인 ‘=’를 적용할 수 없다.
•
GROUP BY 구
◦
테이블에서 레코드를 선택해 집계 연산을 수행하기 위한 구
◦
group을 나누는 기준은 필드
•
HAVING 구
◦
GROUP BY 구로 나뉘어진 그룹(집합)에 조건을 지정
•
ORDER BY 구
◦
SELECT 구문의 결과에 대한 순서를 지정
◦
SQL은 결과로 출력될 데이터들을 정렬하는 일반적인 규칙이 없다.
•
뷰(view)
◦
SELECT 구문을 데이터베이스 내부에 저장하는 기능
◦
테이블처럼 사용 가능 → but, 테이블과는 다르게 내부에 데이터를 보유하지 않음

◦
뷰에서 데이터를 선택하는 SELECT 구문은 내부적으로 뷰를 SELECT 구문으로 전개해서 실행한다.
→ 뷰는 내부에 데이터를 보유하지 않기 때문
•
서브쿼리(subquery)
◦
FROM 구에 지정하는 SELECT 구문
◦
IN 구문에 서브쿼리를 사용할 수 있다.
→ 테이블의 데이터가 변경되어도 수정할 필요가 없어서 편리하다.
7강. 조건 분기, 집합 연산, 윈도우 함수, 갱신
1.
조건 분기
•
CASE 식
◦
CASE 식은 2 종류
▪
단순 CASE 식
▪
검색 CASE 식 → 단순 CASE식의 기능을 포함

◦
SQL의 조건 분기식은 특정 값을 리턴한다.
2.
집합 연산
•
UNION, INTERSECT, EXCEPT등의 집합 연산자들은 중복 레코드를 제거한다.
•
UNION으로 합집합 구하기
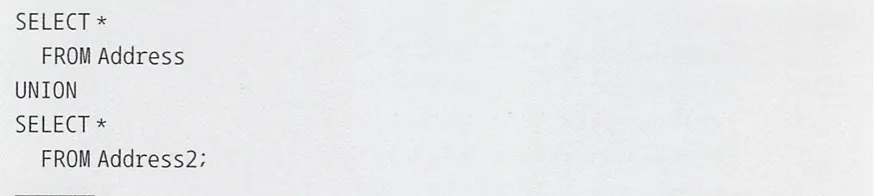
•
INTERSECT로 교집합 구하기

•
EXCEPT로 차집합 구하기

3.
윈도우 함수
•
특정 필드를 기준으로 데이터를 나누는 기능 → 집약 기능이 없는 GROUP BY 구
•
출력 결과의 레코드 수가 입력 테이블의 레코드 수와 같다. → 집약하지 않으므로


◦
COUNT, SUM, RANK, ROW_NUMBER 등을 윈도우 함수로 사용할 수 있다.
4.
트랜잭션과 갱신
•
SQL은 데이터 검색을 중심으로 수행하기 위한 언어 → 갱신은 부가적인 기능
•
SQL의 갱신 작업 분류
1.
INSERT

◦
여러 개의 레코드를 한번에 insert하는 방법도 있음 → 모든 DBMS에서 사용 가능하지는 않음
2.
DELETE

◦
delete 구문은 테이블의 모든 데이터를 제거 → delete 구문의 삭제 대상은 레코드 (필드 x)
◦
일부 레코드만 제거하고 싶으면 WHERE 구로 제거 대상이 되는 레코드를 선별
3.
UPDATE

◦
UPDATE 구문의 SET 구에 여러 개의 필드를 입력해서 한 번에 여러 값을 변경할 수 있다.
