



12강. 집약
•
집약 함수 - 여러 개의 레코드를 한 개의 레코드로 집약하는 기능을 하는 함수
◦
COUNT
◦
SUM
◦
AVG
◦
MAX
◦
MIN
•
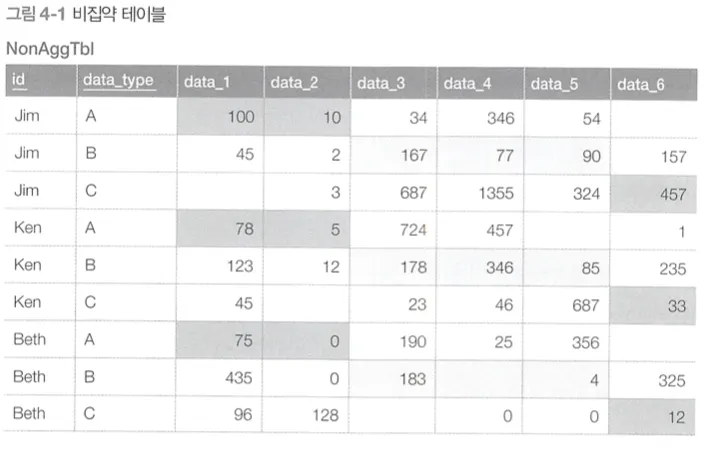
비집약 테이블
◦
한 사람과 관련된 정보가 여러 레코드에 분산되어 있다.
◦
어떤 작업 A~C에서 사용하는 데이터가 필요한 경우 다음과 같은 3개의 쿼리를 사용해야 한다. → 비효율적


◦
또한, 위의 쿼리로 얻은 결과는 서로 필드 수가 달라서 UNION을 사용해서 하나의 쿼리로 합치는 것이 불가능하다.
•
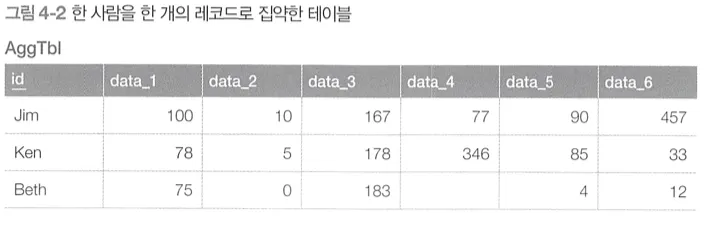
집약 테이블
◦
집약 테이블에서는 한 사람의 정보가 하나의 레코드에 들어있기 때문에 레코드 조회 시 하나의 쿼리로 충분하다.
◦
데이터베이스 모델링의 관점에서도 사람이라는 entity를 나타내는 테이블은 위와 같은 형태가 알맞다.
•
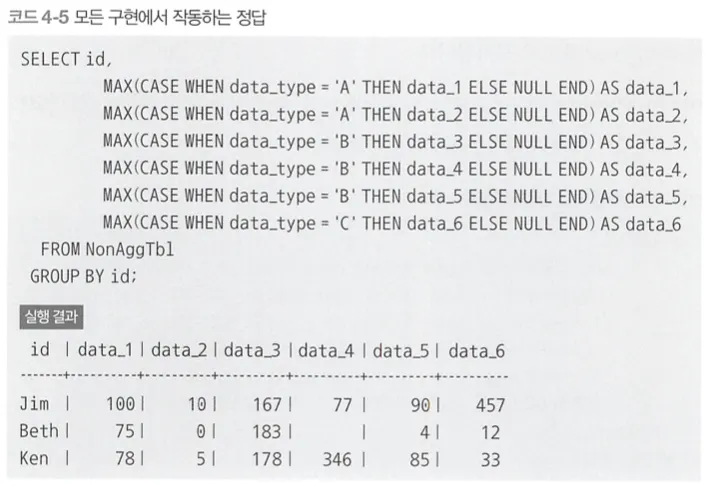
비집약 테이블을 집약 테이블로 변환

◦
GROUP BY구로 집약할 때 SELECT 구에 입력할 수 있는 것은 다음과 같은 3가지 뿐이다.
▪
상수
▪
GROUP BY 구에서 사용한 집약 키
▪
집약 함수
→ MYSQL은 위와 같은 쿼리가 사용가능하도록 기능을 확장했지만, 표준에는 없는 내용이므로 추천하지 않는다.
◦
GROUP BY 구로 레코드를 그룹화하는 시점에는 각 집합에 3개의 요소가 있다.
→ Jim, Ken, Beth에 대한 레코드가 각각 3개 있으므로
◦
여기에 집약 함수를 적용하면 NULL을 제외하고 하나의 요소만 있는 집합이 만들어진다.
•
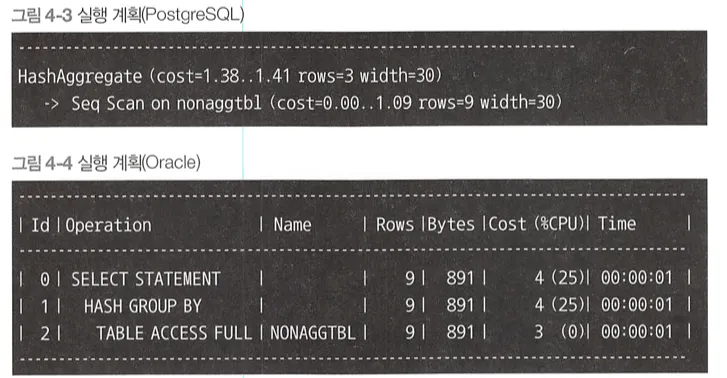
집약, 해시, 정렬
◦
위에서 본 집약 쿼리의 실행 계획
◦
GROUP BY의 집약 조작에 사용하는 알고리즘은 해시 또는 정렬
GROUP BY 해시 방식
◦
해시 방식이 고전적인 정렬 방식보다 빠르다.
→ 해시의 성질상 GROUP BY의 유일성이 높으면 더 효율적으로 작동한다.
의문점
◦
정렬과 해시 모두 메모리를 많이 사용하므로, 충분한 워킹 메모리가 확보되지 않으면 swap이 발생하여 성능 저하가 발생할 수 있다.
→ TEMP 탈락
◦
TEMP 탈락이 발생하면 극단적으로 성능이 저하되며, 최악의 경우 TEMP 영역(디스크)을 모두 써버려 SQL 구문이 비정상적으로 종료될 수 있다.
◦
따라서, 연산 대상 레코드 수가 많은 GROUP BY 구(혹은 집약 함수)를 사용하는 SQL은 충분한 성능 검증을 실시하자.
→ SQL 구문을 직접 실행해보지 않고 성능을 검증 (혹은 실행 계획을 확인)할 수 있나?
•
합쳐서 하나
◦
문제. 0~100세까지 모든 연령이 가지고 놀 수 있는 제품을 구하라.
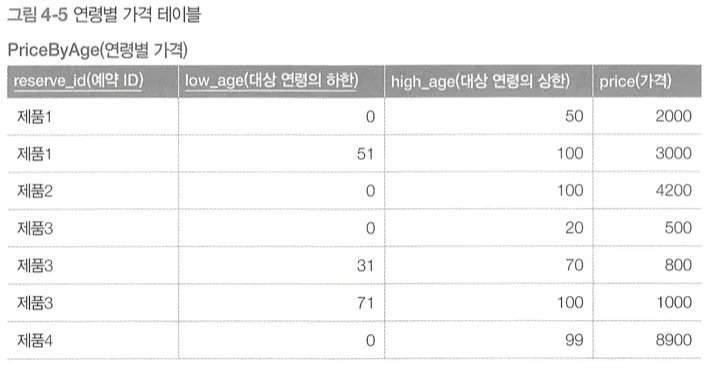
◦
문제의 포인트는 같은 제품에 대한 여러 개의 레코드를 조합해서 문제에 제시된 조건을 만족하는지를 확인하는 것

◦
위와 같은 쿼리로 간단하게 문제를 풀 수 있다.
13강. 자르기
•
GROUP BY구의 기능
◦
자르기
◦
집약
1.
자르기와 파티션
•
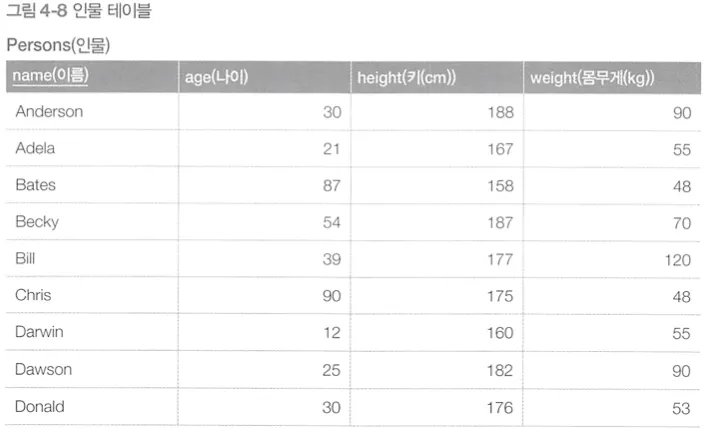
다음과 같은 테이블에서 특정 알파벳으로 시작하는 이름을 가진 사람의 수를 집계
•
SUBSTRING 함수로 name 필드의 첫 글자만 자르기 후 집계
SUBSTRING 함수

•
파티션
◦
GROUP BY 구로 잘라서 만든 각 부분 집합
◦
서로 중복되는 요소를 가지지 않는 부분 집합
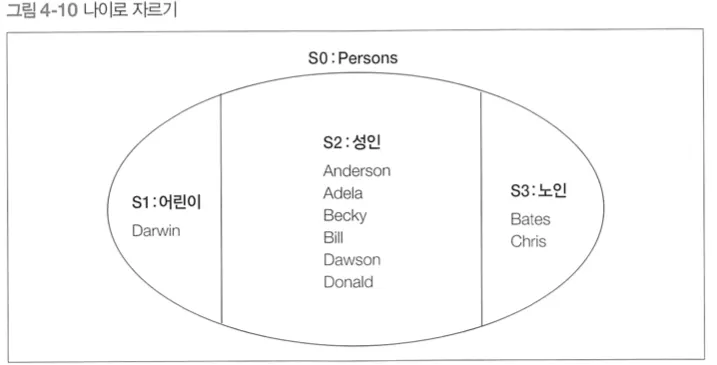

▪
파티션으로 나누고자 하는 기준을 GROUP BY와 SELECT구의 키로 설정 → 위 예제의 경우 나이의 범위
▪
SELECT 구에서 사용한 별칭(age_class)을 GROUP BY에서 사용해서 같은 표현의 중복을 피할수도 있지만 표준에 정의된 방식은 아니다.
▪
실행 계획

▪
GROUP BY구에서 CASE 식 또는 함수를 사용해도 실행계획에는 영향이 없다.
▪
단순한 필드값이 아니라 필드값에 연산을 추가한 식을 GROUP BY의 키로 설정한다면 연산에 오버헤드가 걸릴 수 있다. 하지만 이는 데이터를 가져온 후의 이야기로, 데이터 접근 경로를 의미하는 실행 계획에는 영향이 없다.
2.
PARTITION BY 구를 사용한 자르기
•
PARTITION BY구는 GROUP BY 구에서 자르는 기능만 남긴 구문
•
PARTITION BY구에도 단순 필드외에도 CASE 식, 계산 식 등을 키로 사용할 수 있다.
•
GROUP BY구는 입력 집합을 집약하므로 원본 테이블과 다른 레벨(레코드 수의 차이)의 출력으로 변환하지만, PARTITION BY구는 입력에 정보를 추가할 뿐이므로 원본 테이블의 정보를 그대로 유지한다.