




6강 - SELECT 구문
SELECT 구문은 두 부분으로 구성되는데, ‘SELECT 뒤의 부분인 구’와 그 뒤에 붙는 ‘FROM 구’로 구성된다.
→ SELECT name, phone_nbr FROM personal_info
WHERE 구
WHERE는 어디?가 아니라 ~인 경우를 나타내는 조건을 의미한다.
WHERE는 AND로 묶을 수 있다.
OR 조건을 많이 지정해야하는 경우, IN을 이용할 수 있다.
왜 SQL은 = NULL이 아닌 IS NULL을 사용해야 하는걸까?
ANSI SQL(표준)또한 권장하기도하고, 기본적으로 ‘=’ 연산자 자체는 존재하는 값에 사용하는 연산자이기 때문이다. SQL에서 NULL은 JS의 null처럼 값이 없는 상태를 의미한다.
GROUP BY는 특정 값을 기준으로 그루핑(케이크를 나누기)하는 것.
WHERE구가 ‘레코드’에 조건을 지정하는 것이라면, HAVING구는 ‘그룹’에 조건을 지정하는 것.
뷰와 서브쿼리

마치 Read용 함수를 만들 듯, View를 생성해놓을 수 있다.
“테이블의 모습을 한 SELECT 구문”으로서, 하나의 테이블로서도 사용할 수 있다(이미 1차적인 처리가 끝난, 중첩된 구조로 사용할 수 있음)
한편, 위의 케이스가 아닌 아래의 케이스처럼 FROM 자체에 별도의 SELECT 구문을 삽입하여 사용하게 되는 경우 서브쿼리라고 한다.
DBMS는 서브쿼리를 상수로 전개(즉 실행하여 결과를 가지고 옴)하여 진행한다.

→ 서브쿼리를 남발하면 사실상 여러 쿼리문을 냅다 실행해버리는 결과와 동일하겠군..
7강 - 조건 분기, 집합 연산, 윈도우 함수, 갱신
SQL과 조건 분기
SQL에서는 CASE를 이용하여 분기한다.

집합 연산
UNION을 이용하여 합집합 연산을, INTERSECT를 이용하여 교집합 연산을, EXCEPT로 차집합 연산을 수행할 수 있다.
→ 두 SELECT하는 테이블이 호환되는 스키마를 가져야 연산이 가능하다 - 다른 테이블인 경우에는 수행할 수 없다.
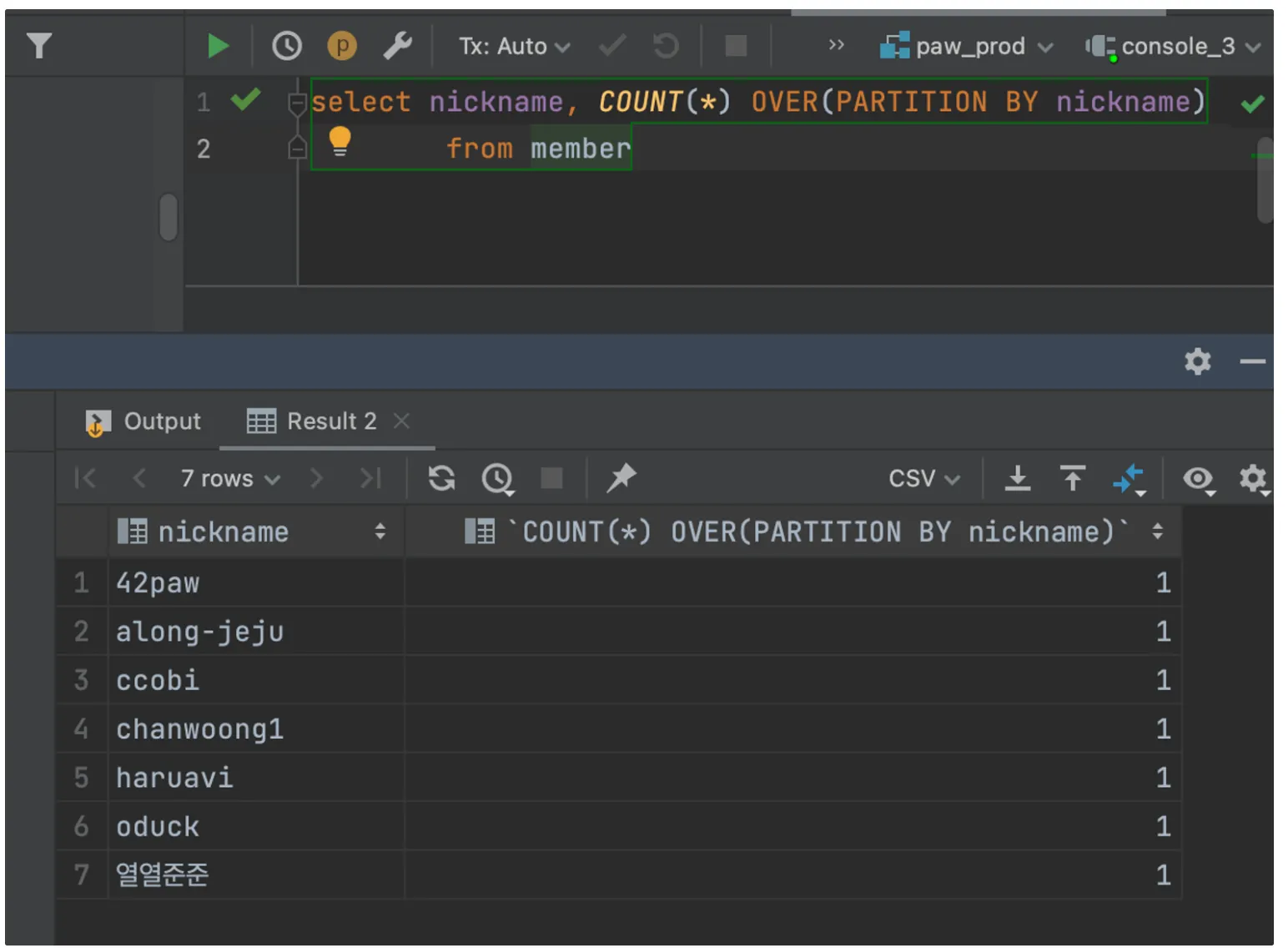
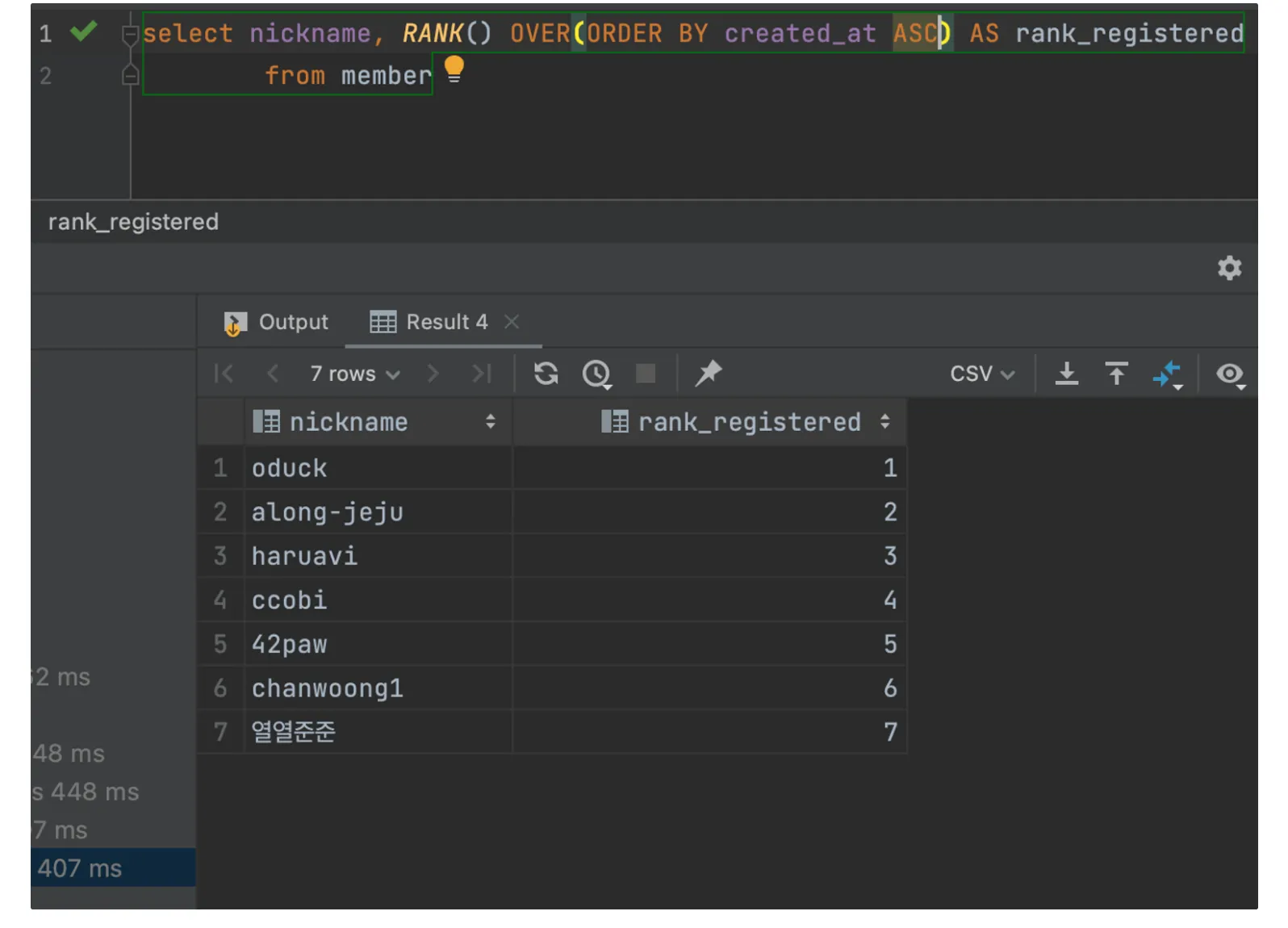
윈도우 함수
집약 기능이 없는 GROUP BY라고 생각하자.
→ 자르기만 있지 묶는 건 없다. 무슨 소리냐고?

윈도우 함수도 테이블을 자르는 것은 GROUP BY와 같으나, PARTITION BY로 수행하여 자른 뒤, 집약하지 않으므로 출력 결과의 레코드 수가 입력되는 테이블의 레코드 수와 같다.
기본적인 구문은 집약 함수 OVER(PARTITION BY 키)으로 구성된다.
트랜잭션과 갱신
인데.. 트랜잭션 관련 내용은 업네..?